
Transcript
MayaPicture the release page on download day. Three files. One fits on a developer's laptop. One needs a proper server. And one — the four-hundred-and-five-billion-parameter flagship — most teams will never run at all. Here's the strange part: the paper is proudest of that last one for what it did to the other two.
LeoWait, what?
MayaThe giant isn't really a product. It's the herd's teacher. It raises the quality ceiling, it helps generate and grade training data, it sets the bar the small ones get measured against — and then almost everyone deploys the siblings.
LeoSo the headline model is infrastructure for the models people actually use. That's a different pitch from "we built a big one."
MayaThat's today's source — Meta's paper, The Llama 3 Herd of Models. Quick thread from last episode first.
LeoRight — Llama 2 was the moment an open chat model shipped with its alignment recipe attached, and builders inherited the safety and deployment work along with the weights.
MayaAnd today that single bargain becomes a family.
LeoEight billion, seventy billion, and the flagship — one shared recipe, with multilingual text, code, tool use, and long documents folded in.
MayaAnd our running build from this topic keeps us honest. The mid-sized company making an on-device coding and data-analysis assistant — they can't put the flagship on anyone's laptop. But the herd framing says they were never supposed to.
LeoThey run the eight-billion locally, maybe the seventy on a private server, and keep the big one as the measuring stick. Okay. Where does the paper start?
MayaWith a decision that looks like a non-decision. The team names three levers — better data, larger scale, and managing complexity — and the architecture choice falls out of that third lever. Call this stretch the Steady Frame. Llama 3 is a mostly standard dense Transformer. No mixture-of-experts, no exotic routing. Dense meaning the whole network fires for every single token.
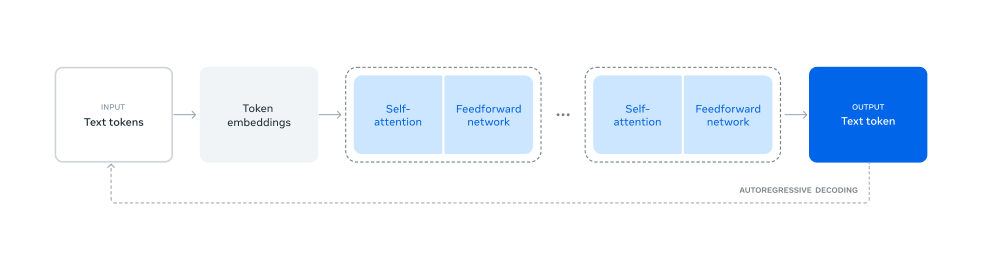
LeoWhich on paper is the expensive choice. Sparse expert models wake up only the pieces a token needs.
MayaIt is the expensive choice — at inference. The paper's argument is that it buys something at training time: stability. When one training run costs this much, you want a machine whose failure modes you already understand. They say it almost that plainly — standard dense over mixture-of-experts, partly to maximize training stability.
![Illustration of 4D parallelism. GPUs are divided into parallelism groups in the order of [TP, CP, PP, DP], where DP stands for FSDP. In this example, 16 GPUs are configured with a group size](images/t6e2_the_llama_3_herd_of_models_fig5.jpg "The Llama 3 Herd of Models — https://arxiv.org/pdf/2407.21783")
LeoHm. Insurance, basically.
MayaInsurance, with a few quiet upgrades smuggled in. Grouped-query attention, which shares key-value heads across groups of query heads — that shrinks the decoding cache. A much larger tokenizer vocabulary. Positional settings tuned so the context window can stretch later.
LeoThe cache part isn't trivia for our company, by the way. Smaller key-value caches are the difference between an assistant that keeps up while you type and one that stutters on a mid-range laptop.
MayaAnd the bigger tokenizer earns its keep too — more text packed into the same compute budget, especially across languages. Internal tickets in Portuguese, code comments in German — the model reads them cheaper.
LeoFine, so the architecture is deliberately plain. Then where did the capability actually come from?
MayaThe Diet. Fifteen trillion tokens of pre-training data.
Leo[gasp] Fifteen trillion. That's a different universe from what Llama 2 ever saw.
MayaAnd not fifteen trillion tokens of just anything. Cleaning, deduplication, quality filters, dedicated pipelines for code and reasoning data, and safety-driven removal of domains heavy in personal information or adult content. The weight file everyone argues over is the fossil. The data work is the living animal.
LeoThere's one move inside the Diet I want flagged, because it's the part our company should copy. The code expert. Mid-pre-training, they branch the model, continue it on a mostly-code mix, and then use that specialist to gather better code annotations and synthetic examples for the rest of the herd.
MayaA herd member bred to improve the feed for the others.
LeoWhich means when you're shopping for a model to do repo-aware bug fixes and S-Q-L analysis, the question isn't "how many parameters." It's "did anyone deliberately train and filter for code." Llama 3 answers yes, with receipts.
MayaThen comes what I'd call the Compute Bet. The flagship trained at roughly fifty times the compute of the biggest Llama 2. But the interesting bet isn't the size — it's how they chose the size. Scaling laws told them: for this budget, the optimal model is about this big. The flagship was sized from a forecast, not from bravado.
LeoAnd then they deliberately broke the same math for the small ones.
MayaDeliberately! The eight and the seventy billion are trained well past what a compute-optimal recipe says. On the training ledger that looks wasteful. But —
Leo— but training cost is paid once and inference is paid forever. An overtrained small model beats a theoretically optimal one at the same serving cost. That's the line that actually shows up on our company's cloud bill.
MayaSo the herd runs two economies at once. The flagship is sized for training efficiency; the siblings are overfed for inference efficiency. Same recipe, opposite bets, on purpose.
LeoHuh. Neat.
MayaNext stretch — the Finishing School. Post-training, where a text predictor learns to behave like an assistant. Several rounds of it. Supervised finetuning: show the model examples of the answers you want. Rejection sampling: generate a handful of candidates and keep the strongest.
LeoMm-hm.
MayaA reward model that scores preferences. And Direct Preference Optimization — D-P-O — which nudges the model toward preferred answers without running the full reinforcement-learning loop.
LeoThat last one is a quiet headline. Llama 2 leaned on the heavy on-policy reinforcement machinery. Llama 3's team tried those methods again and found DPO cheaper — and stronger on some instruction-following benchmarks at this scale.
MayaWith stabilizers around it — handling of formatting tokens, an added likelihood term — but yes. The assistant behavior comes from cycles: generate, score, filter, tune, repeat.
LeoAnd tool use lives inside those cycles. I want this said loudly, because people assume a model picks up tool calling by reading code on the internet. It doesn't. The paper trains it: synthetic tool trajectories, human annotations, multi-step interactions, file-upload tasks, zero-shot function calling.
MayaBecause a tool call isn't an answer — it's a little workflow. Think of our assistant inspecting a private C-S-V file: write a small script, hit an error, fix it, explain the result. The paper treats that as a dialog with actions, and trains it as one.
LeoLong context gets the same treatment. The window stretches to a hundred and twenty-eight thousand tokens — continued pre-training plus synthetic long-document examples. And they're careful about a failure mode I see constantly in the wild: long-context tuning quietly wrecking short-context skill. The mix is balanced to avoid that.
MayaThough a long window deployed is not a long window used well. The company can feed in a whole design doc; whether the model attends to the right paragraph is an evaluation question, not a spec-sheet line.
LeoAlways the eval question.
MayaOne more stop before the argument — the Refusal Dial.
LeoGo on.
MayaSafety, in this paper, is two numbers in tension. Violation rate: the model says something harmful. False refusal rate: the model refuses something safe. Turn one dial down and the other tends to creep up.
LeoAnd both are product failures. An assistant that answers dangerous prompts is unacceptable. An assistant that won't debug a security ticket because it saw the word "exploit" is useless to the team that bought it.
MayaSo Llama 3 works both levels — safety finetuning inside the model, and Llama Guard 3 as a system-level filter around it. Adversarial and borderline prompts, multilingual safety data, long-context jailbreak mitigation, tool-use safety evaluation.
LeoHere's my asterisk, though. Some of those safety benchmarks are internal. Outside teams cannot reproduce every comparison. Open weights do not equal open evidence — and for a regulated deployment, that gap is real.
MayaFair asterisk. And it walks us straight into the fight, because the release question is genuinely contested — so let's actually have it. I'll argue for releasing weights at this level.
LeoThen I'm the skeptic. Go.
MayaReleasing the herd creates a testing surface no closed lab can match. Thousands of teams probing it, fine-tuning it, auditing it at the deployment layer — and small teams get to build specialized assistants that a closed A-P-I would price out or black-box. Broad access produces more scrutiny and more useful systems than any one provider could.
LeoAnd the same release lowers the misuse bar for everyone, permanently. You cannot patch a model that's already on everyone's hard drive. No recall, no coordinated fix, no enforcement. You've shipped the hardest safety decisions to downstream developers who mostly haven't hired for them.
MayaThose downstream teams also get something a closed provider never gives them — inspection. Privacy-sensitive deployments, cost-sensitive ones —
Leo— fine, inspection and adaptation survive. The research acceleration too; the open ecosystem since Llama 2 is the evidence for it. What doesn't survive is the patching story. Once the weights are out, misuse response is somebody else's problem forever.
MayaAnd that is the strongest card your side holds: release is irreversible, and coordination after release is close to impossible. So where we actually land —
Leo— is a judgment call about which risk you'd rather hold: concentrated control with no outside audit, or broad access with no recall. The paper plants its flag on access and builds Llama Guard as the mitigation. Reasonable people read that ledger differently, and the evidence doesn't settle it yet.
MayaHonest landing. There's a second fight, smaller but live: dense versus sparse. And here I'll switch chairs on you — I think mixture-of-experts is the future this herd is postponing. Capacity that spends inference compute only where it's needed. At flagship scale, dense inference is brutally expensive every single day you serve it.
LeoThen I'll defend the choice they actually made. [chuckle] The dense run finished. Stability and debuggability are not aesthetics when a flagship run is this expensive — a routing failure halfway through is a disaster you can't refund.
MayaThat holds — for this run, this generation. It holds less and less as model capacity keeps growing and the serving bill compounds.
LeoAgreed it's a postponement, not a verdict. And conveniently, the next episode is DeepSeek's technical report making the sparse case at full volume. We'll rerun this argument with their numbers on the table.
MayaSo pull it together for the builder. The herd is an operating philosophy, not a single model. Data quality gives it its instincts. Scale, spent two opposite ways, gives it strength. Post-training gives it manners and its tool-using moves. The safety stack draws the fence.
LeoAnd the company in our example still owns the unglamorous remainder — evaluations on their own tasks, logging, red-team tests, data governance, license review, fallback behavior. The herd widens their choices. It doesn't do their homework.
MayaFrom Llama 2 to Llama 3, open weights went from "a chat model you can adapt" to a menu — sizes, context lengths, tools, safety layers, chosen per constraint.
LeoSo here's the question to walk away with. If you were choosing one member of the Llama 3 herd for a private coding and data assistant, what capability would you demand proof of before trusting it with real work?
Source material
← Back to Mastering Language Models: From Architecture to Optimization