
Transcript
MayaTwo boxes arrive from the same factory. The first holds a raw engine — a language model that will continue any text you feed it, brilliantly and indifferently. The second holds a finished assistant: it follows instructions, holds a conversation, declines the sketchy requests. And taped to that second box is the thing factories almost never ship — the build log. The recipe that turned box one into box two.
LeoThat recipe is why this paper matters. Llama 2 gets remembered as "Meta released open weights," but the weights were half the release. The other half was documentation of the assembly line — supervised tuning, preference training, safety work — at a level of detail closed labs mostly kept to themselves.
MayaLast time we reframed open-weight model choice as a systems-design decision — what a team actually takes ownership of when it downloads a model instead of renting one.
LeoToday's paper is where that stops being abstract. Llama 2: Open Foundation and Fine-Tuned Chat Models shows what Meta put in the boxes, what stayed inside the factory, and how much engineering sits between raw pretrained weights and something you'd let talk to a user.
MayaQuick plain-language pass before any acronyms. A foundation model is a general text engine. It has absorbed patterns from a huge corpus, but nobody taught it how an assistant should behave. Ask it a question and it might answer — or continue your question with three more questions, because continuing text is all it knows.
LeoSeen that live. Unsettling.
MayaA chat model is that engine after behavior shaping — trained to follow instructions, stay on task across turns, refuse certain requests, and stop acting like an autocomplete with opinions.
LeoOne label to get right up front, because the paper is careful about it: this is open-weight access under a license. You can download and run the trained parameters. It is not a fully reproducible open-source pipeline — the data recipe stays in the factory.
MayaWith that, four stops today. The Base Drawer, where the raw capability lives. The Chat Workshop, where the assistant gets built. The Safety Gate, where behavior gets stress-tested. And the Release Contract, where the lab decides what the world gets.
LeoBase Drawer first. What's actually in it?
MayaA family of pretrained models — from small enough to experiment with on practical hardware up to large enough to compete with the strongest open models of its time. Compared with the first Llama family, the team trained on more data, drew it from publicly available online sources rather than Meta's user data, and doubled the context window.
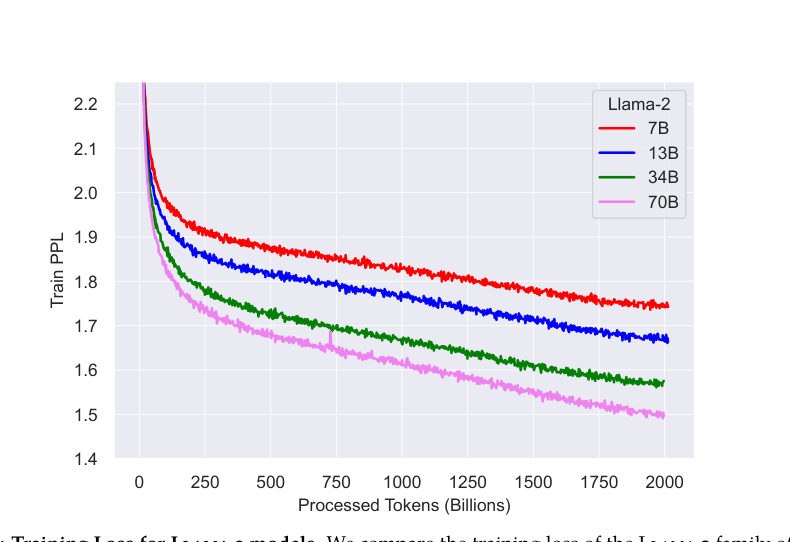
LeoContext window meaning the span of text the model can hold in view while predicting the next token. Doubling it buys longer instructions, longer documents, longer threads.
MayaThe larger variants also use grouped-query attention. Attention is the expensive part of serving a big transformer — every new token wants to look back at everything. Grouped-query attention lets heads share memory— let me restate that. Heads share some of the stored key-value information, so the model serves faster and leaner without losing much quality.
LeoWhich matters to exactly the team we keep returning to — the mid-sized company building an on-device coding and data-analysis assistant. For them, the Base Drawer is the inventory: a small model for privacy and latency on the device, a bigger one if the reasoning demands it.
MayaBut here's what the drawer doesn't give them. Drop raw base weights into a chat box, and the assistant will continue prompts instead of answering them, ignore policy, miss intent—
Leo—because nothing in pretraining ever told it those things matter.
MayaNothing at all. Which is why the Chat Workshop exists. Stage one: supervised fine-tuning. Humans write example prompts and the answers a good assistant should give, and the model trains on those demonstrations until it gets the shape of dialogue.
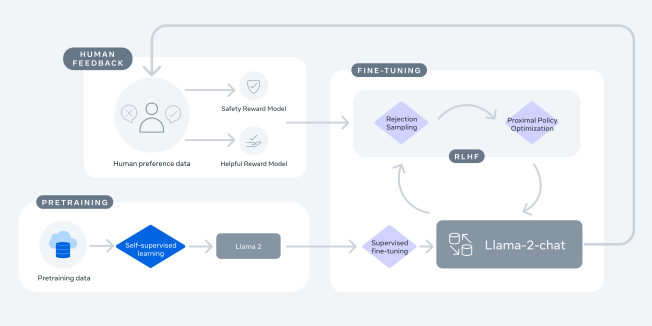
LeoAnd the workshop's first finding is one I'd frame and hang on the wall: quality beat volume. A relatively small set of carefully written instruction examples did more than enormous piles of noisy third-party instruction data.
MayaWhich fits a pattern from this series — the model already has the capability; post-training shows it which behavior to surface.
LeoThen stage two?
MayaReinforcement Learning from Human Feedback — R-L-H-F. People look at two candidate responses to the same prompt and pick the better one. Those preferences train a separate scoring model.
LeoThe reward model — a learned judge. It can grade outputs at a scale no human team could, and its scores steer further updates to the chat model.
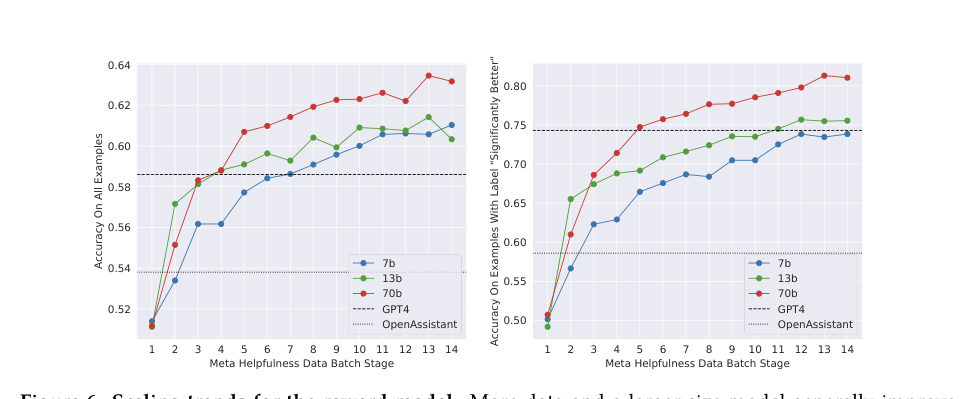
MayaAnd here Llama 2 makes a move I find genuinely elegant: it trains two judges, not one. A helpfulness reward model and a separate safety reward model.
LeoBecause one judge gets pulled in two directions. A single score averages "was this useful" against "was this safe," and the average hides exactly the cases you care about — maximally helpful in a dangerous way, or maximally cautious in a useless way.
MayaOur on-device team feels that split in week one. A developer asks for a database migration script. Helpfulness wants it concrete, runnable, complete. Safety says don't casually hand over commands that destroy tables. Two judges let you see both pressures instead of one blended grade.
LeoTwo dials, not one.
MayaThe workshop also runs as a loop — the production lesson hiding in the paper. As the chat model improves, its outputs change, and the reward model was trained to judge the old ones. It needs fresh comparisons from the model's current behavior, or its judgments drift off target.
LeoSo alignment data isn't a sticker you place on the box once. It's calibration equipment, and it has to stay matched to the machine it measures.
MayaOne more workshop tool: Ghost Attention. Multi-turn conversations have a failure mode where a system instruction — "stay within company data-handling rules," say — slowly fades as the conversation grows. Ghost Attention is a training trick that keeps that instruction in force across many turns.
LeoDeployment people feel that one in their bones. A rule that quietly expires after ten follow-up questions is not a rule. It's a suggestion with a half-life.
Maya[chuckle] A suggestion with a half-life. I'm keeping that.
LeoBefore the Safety Gate, there's a fork our company has to argue about, and I'll take a side. They hold base weights and chat weights. Start from the chat model. Instruction following, multi-turn behavior, baseline refusals — Meta already paid for that. Rebuilding it in-house means rebuilding this whole workshop, annotators and reward models included.
MayaAnd I'd push the other way: start from the base. The chat model's habits — its refusal style, its safety boundaries — reflect Meta's guidelines and Meta's annotators, and they're baked in. Fine-tune on top and you're specializing somebody else's assistant. The base is raw material you can shape without inherited assumptions.
LeoInherited assumptions, granted. But look at what the recipe costs. Preference data, iterative reward modeling, safety tuning — a mid-sized team doesn't casually reproduce that. Teams shipping on open weights overwhelmingly start from the chat variant, precisely because the workshop is the expensive part.
MayaFine — for an assistant that's mostly general behavior with a domain accent, chat-start wins on cost. But the further your product sits from "general helpful assistant," the more those baked-in habits become things you fight rather than features you inherit.
LeoThat's a split I can live with: chat-start near the assistant template, base-start far from it. Either way, you test which assumptions you just bought.
MayaWhich hands us to the Safety Gate — because what you bought there is the least visible. Llama 2-Chat went through safety-specific supervised examples, safety R-L-H-F with that dedicated safety judge, and a technique called safety context distillation.
LeoDistillation sounds grander than it is. Generate safer behavior by prefixing an explicit safety reminder, then train on those safer outputs so the behavior sticks without the reminder. Internalizing the note instead of re-reading it.
MayaPlus red teaming — people from many different domains deliberately trying to break the model, with the findings folded back into training.
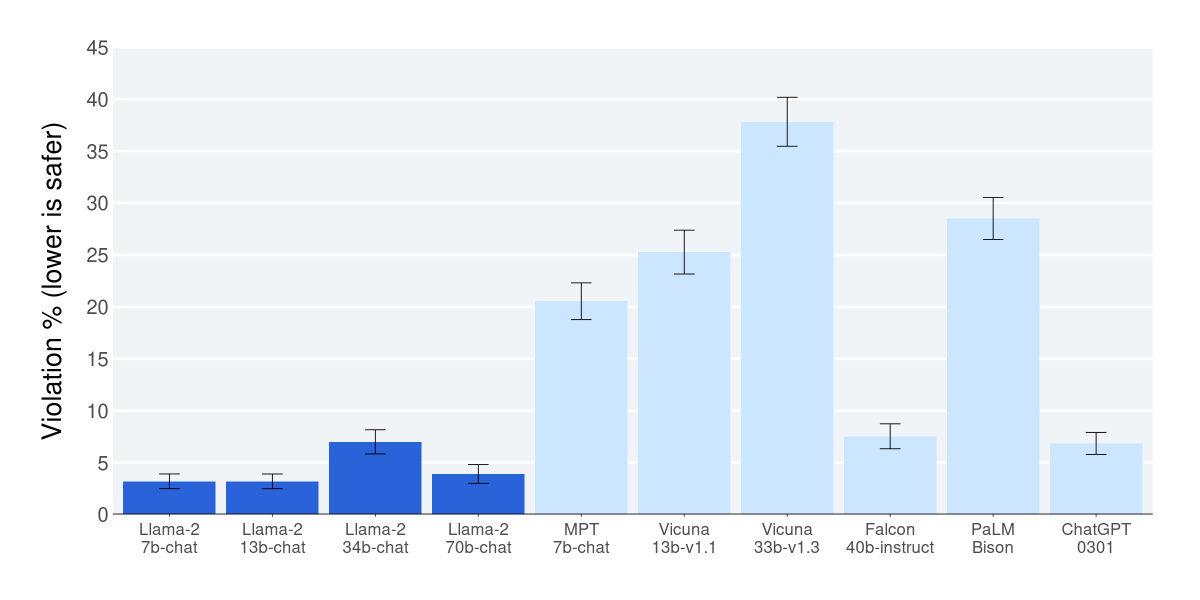
LeoThe paper is honest about where the danger lives, too: the long tail. Safety failures hide in odd phrasings, role-play setups, multi-turn traps, non-English prompts — places ordinary benchmark prompts never visit.
MayaRight where tests aren't.
LeoWhich is the uncomfortable part. And the gate has a cost on its other side: push safety tuning hard enough and the model turns cautious, vague, refusal-heavy on perfectly legitimate requests.
MayaOur data analyst hits that wall: debugging a failing script that touches customer records. Too loose, and the assistant walks into a privacy mistake. Too nervous, and it refuses routine engineering work until the analyst stops asking.
LeoSo the gate isn't passed by trusting the paper's aggregate safety scores. It's passed by testing your application, your users, your languages, your failure modes.
MayaLast stop — the Release Contract. Llama 2 shipped for research and commercial use under a license with an acceptable-use policy, code examples, and a responsible-use guide.
LeoAnd around that contract sits the real fight of this release — one serious people are still having. Take a side, Maya. I know which one you want.
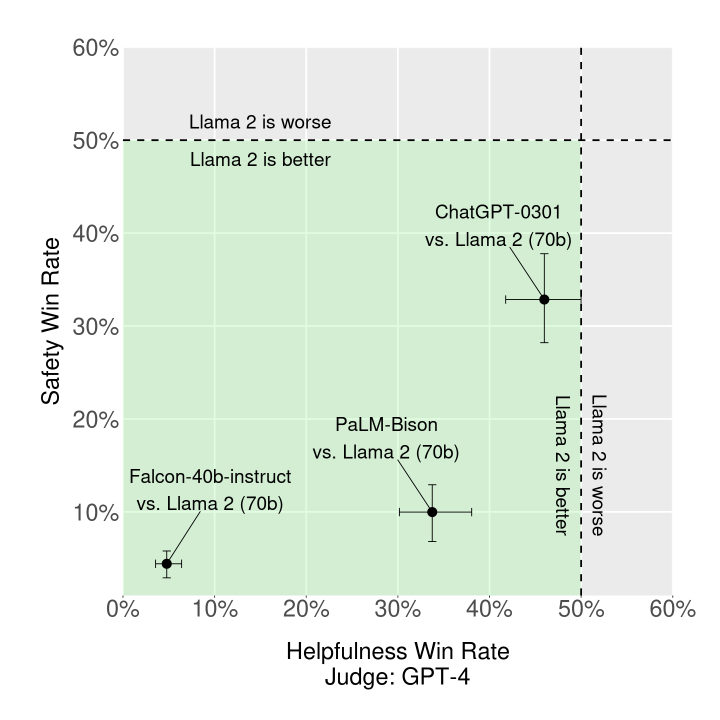
MayaThe open side, and not as ideology. Broad access is a safety mechanism. Thousands of researchers can inspect these weights, find failures, publish attacks, build defenses, adapt the system locally. A model behind an A-P-I is a model almost nobody outside the lab can examine — and you cannot repair what you cannot examine.
LeoThen I'll take controlled access, because the accountability math is brutal. Once weights are copied widely, the lab's ability to patch anything ends. No rollback, no monitoring, no revocation. A provider behind an interface can watch for abuse, fix failures, stage access to stronger models. Open weights cannot prevent the harms they enable — by construction.
MayaAnd the open camp's answer is that the alternative concentrates that power in a handful of labs and calls the concentration safety—
Leo—while the controlled camp answers that distributing capability to everyone includes everyone you'd rather not arm. Both arguments are real — that's why this is worth staging instead of summarizing.
MayaHere's where it lands. Llama 2 doesn't resolve the tension — it occupies it. More access than a closed product, more shared methodology than almost anyone before, and still a license, an acceptable-use policy, and downstream responsibility as the leash.
LeoI'll concede this much to your side: the open release demonstrably produced inspection and repair work no access program matched. What neither of us can produce is the counterfactual — how much misuse the weights enabled stays unobservable. The debate runs on incomplete evidence, and anyone claiming it's settled is selling something.
MayaAgreed — and notice the paper hedges the same way about evaluation. It reports Llama 2-Chat beating open chat models and competing with some closed systems on the authors' prompt sets, while warning in the same breath that human evaluation is noisy and incomplete.
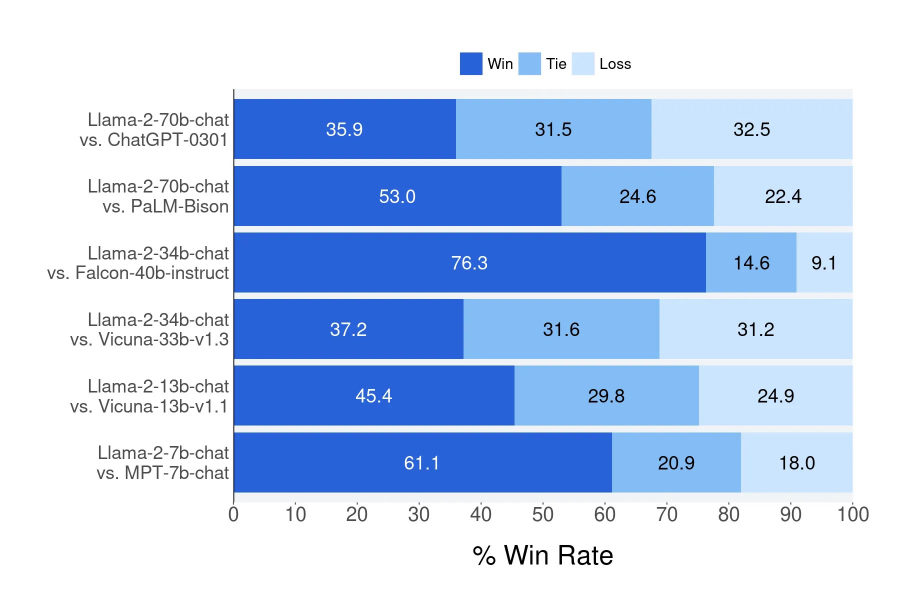
LeoThat warning deserves the airtime. A win on curated prompts says nothing about your spreadsheet formulas, your internal A-P-Is, your quiet refusal behavior. The right takeaway was never "Llama 2 is good." It's "open weights let you build your own evidence."
MayaTwo limitations to carry out the door. The training data isn't reproducible — you can run the weights, but you can't rebuild them. And the reported development is primarily English-focused, so multilingual deployment shifts the testing burden back onto the builder.
LeoHm. So name the mental model you'd keep.
MayaThe release stack. Base capability, chat behavior, safety shaping, evaluation evidence, license terms — one object, not five announcements. Evaluate them together, because you adopt them together.
LeoMine is blunter: openness doesn't delete work, it relocates it. Vendor negotiation becomes ownership of evidence. You can finally inspect and adapt everything — which means you now answer for everything.
MayaAnd that's why this paper sits here in the series — the moment fine-tuning and R-L-H-F stopped being lab techniques and became a public artifact teams could actually hold. Next episode the family becomes a herd: Llama 3, with newer training choices and much wider ambition.
LeoSo, for the road: if you were shipping an open-weight assistant tomorrow, which part of the Llama 2 stack would you trust as reusable infrastructure, and which part would you insist on re-testing for your own users?
Source material
← Back to Mastering Language Models: From Architecture to Optimization