
Transcript
MayaLast time we walked the Llama 3 herd — one dense recipe scaled across sizes, with the flagship doing double duty as a teacher for the smaller models people actually run.
LeoToday's paper walks away from that recipe. The DeepSeek-V3 technical report asks a stranger question — how much frontier capability can you ship if most of the model stays asleep?
MayaPicture an office tower at two in the morning. A question arrives at the front desk, and the building does not light up. Nine windows turn on — eight specialists up in the floors, plus one generalist desk by the lobby that sees every request. The answer goes out, the lights go off, the next question wakes a different nine.
LeoHuh. Nine exactly?
MayaNine exactly, and that's not me stretching an analogy — it's the literal mechanism. DeepSeek-V3 holds six hundred seventy-one billion parameters in the tower, and about thirty-seven billion of them wake up for any one token.
LeoThat ratio is the whole bargain. You store a frontier-scale model but pay mid-scale compute per token. The other headline numbers: fourteen point eight trillion tokens of pre-training, a context window extended to a hundred twenty-eight thousand tokens, and a full training run of roughly two point eight million GPU hours on H eight hundred chips.
MayaWhich they price at about five point six million dollars.
LeoWith a footnote doing heavy lifting. That assumes two dollars per GPU hour, and it counts only the final run — no prior research, no failed ablations, no engineering exploration. A real bill. Not the whole bill.
MayaGranted. Now put our running example in front of it — the mid-sized company building an on-device coding and data-analysis assistant. Their local model is fast and private, and then a brutal database migration lands on someone's desk. The hosted frontier model could handle it; the privacy budget says no. DeepSeek-V3 shows up looking like the middle path: open weights, frontier-adjacent capability, sparse activation.
LeoLooking like. Whether it is the middle path is the rest of this episode.
MayaSo here's the building tour. The Latent Locker, where long-context memory gets compressed. The Switchboard, where tokens find their specialists. The Traffic Dial, which keeps those specialists evenly loaded. The Machine Room, where the cluster engineering lives. And the Loading Dock, where you learn what serving this thing actually costs.
LeoLocker first. It's the part summaries skip, and it's where the long-context promise lives or dies.
MayaIt's attention. Long-context generation is expensive because the model carries a running memory — keys and values for every token it has already seen. Ask the assistant to read a whole repository and that cache balloons until memory, not math, is the bottleneck.
LeoMm-hm.
MayaMulti-head latent attention — M-L-A — compresses that memory. Instead of storing the full bulky keys and values, the model caches a small latent representation plus a separate positional piece, and reconstructs what attention needs on the fly.
LeoFor the company's assistant that's not exotic. Long repo, big analytics notebook — every byte the cache doesn't hold is latency and memory headroom back. The capability is "reads your whole codebase"; the enabler is a smaller locker.
MayaThen the Switchboard, the part everyone quotes. The Transformer backbone stays, but most feed-forward layers become DeepSeekMoE layers — mixture of experts. Each holds one shared expert that processes every token, plus two hundred fifty-six routed experts, of which eight get picked per token.
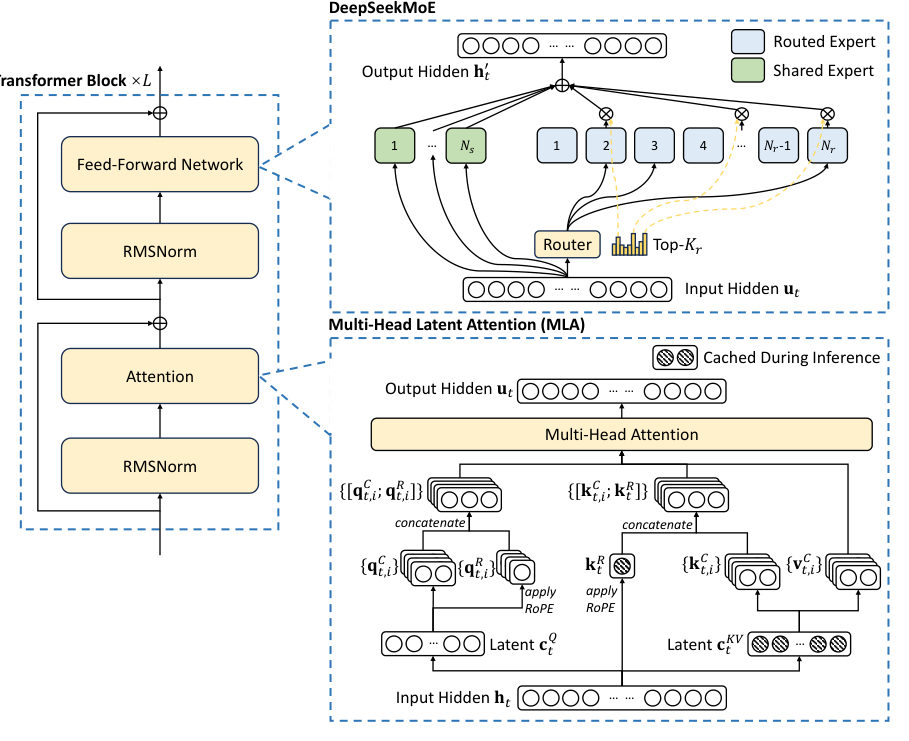
LeoThe lobby desk and the eight lit windows.
MayaStraight out of the hook. And here's where the report gets more interesting than a generic mixture-of-experts summary, because routing has a famous failure mode—
Leo—load imbalance. Everyone's tokens pile onto the same few experts, the hardware sits unevenly used, and the router can collapse into bad habits it never escapes.
MayaThe classic fix is an auxiliary loss — a penalty pushing the router to spread work around. The report's complaint: push hard enough on balance and the experts lose room to specialize.
LeoSo the medicine suppresses the symptom and the talent at the same time.
MayaWhich is why V3 reaches for the Traffic Dial instead. Each expert gets— okay, here's the cleaner way in. When the router ranks experts for a token, each expert's score carries a little learned bias. Overloaded expert? Bias nudges down. Underused? Nudges up. But — and this is the move — the bias only affects who gets chosen. The actual output weight still comes from the original affinity score.
LeoThat distinction earns its keep. The dial steers traffic without pretending an expert was more relevant to the token than it really was. You balance the load and keep the semantics honest.
MayaThe report calls it auxiliary-loss-free load balancing. A tiny sequence-wise balance loss remains as a guardrail, but the heavy lifting moved from a loss term to a bias.
LeoFine — then let me make the dense camp's case properly, because I mostly believe it. Everything you just described is surface area. A router that can mis-route. A balancer that can drift. Expert parallelism that scatters one model across machines. Their strongest argument is operational: one path through the model is something a small team can deploy, monitor, quantize, and debug. This is many paths and a dispatcher.
MayaAnd the sparse camp's answer is arithmetic you can't wave away. Scaling dense models naively is getting too expensive to be a strategy. If capacity you don't activate is cheap to hold, sparsity is how an open-weight model carries frontier capability at a price anyone—
Leo—anyone with a data center.
Maya[chuckle] With a data center, yes. That's the honest shape of it.
LeoBecause look at what the economics bought. The report itself names the limitation: the recommended deployment unit is large — multi-node, expert-parallel serving. Our mid-sized company can't put this on a laptop. Probably not even on one server.
MayaI'll give you the small team. I won't give you the frontier. For code and math at the top end, the dense route to this capability costs what almost nobody can pay. Sparse isn't the convenient choice; it's the open one.
LeoAnd the cost math is real — I'm not arguing with the arithmetic. So here's where the evidence actually lands: sparse wins when you can amortize the machine room. Dense wins when the team is the scarce resource. The paper doesn't dissolve that split. It prices it.
MayaBoth camps can sign that — and the authors quietly do, by listing deployment scale under their own limitations. So let's look at the Machine Room they amortized, because the architecture only works on top of it.
LeoMy favorite part of the report, honestly. It reads like an infrastructure paper wearing a model paper's badge.
MayaMixture-of-experts training spends enormous time moving tokens to experts and results back. DeepSeek-V3 trains on two thousand forty-eight H eight hundred GPUs with a pipeline schedule called DualPipe, built to overlap computation with communication — including the all-to-all traffic expert parallelism creates.

LeoKeep the chips fed.
MayaThey wrote custom cross-node all-to-all kernels to use InfiniBand and NVLink efficiently, and — my favorite single detail — the router is capped at four nodes per token. The model is literally not allowed to ask for a routing pattern the network can't serve cheaply.
LeoArchitecture and cluster topology, co-designed. That's a mental model worth keeping: sparsity looks free on a whiteboard and gets expensive in the network, so they constrained the whiteboard.
MayaSame philosophy in the precision system. Most heavy matrix multiplications run in F-P-eight — an eight-bit floating-point format — cutting memory and speeding up compute. The sensitive parts stay in higher precision: embeddings, output heads, gating, normalization, attention. And the eight-bit parts get fine-grained scaling — activations in small tiles, weights in blocks — with higher-precision accumulation so errors can't quietly pile up.
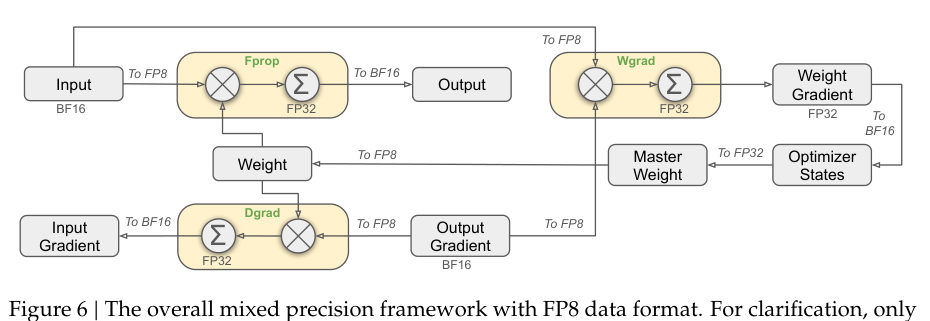
LeoSo the rule is not "use fewer bits and hope." It's "use fewer bits where the math tolerates it, and engineer the escape hatches where it doesn't."
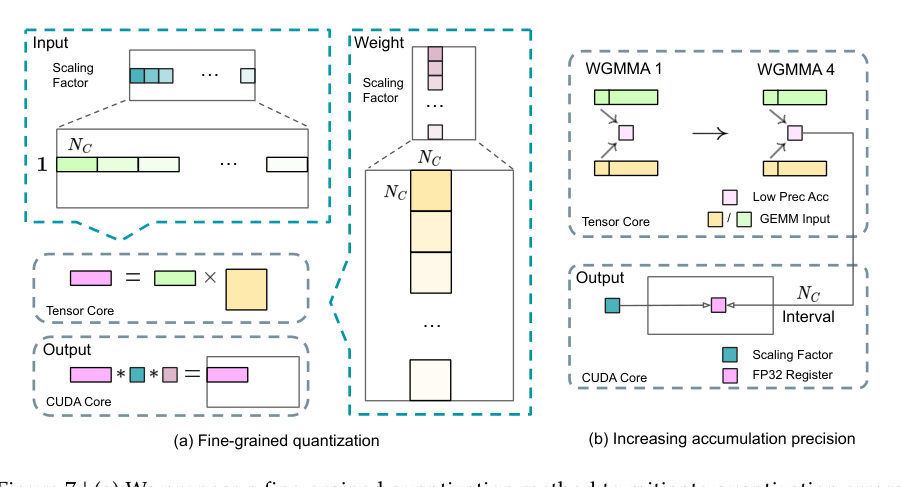
MayaThat sentence is the whole paper. Routing needs a traffic dial. Eight-bit needs scaling care. Long context needs a compressed locker. The claimed efficiency is many small constraints agreeing with each other.
LeoOne more training trick before the finishing work — the one with serving implications. Multi-token prediction. During training the model predicts not just the next token but one extra future token, through a small added module.
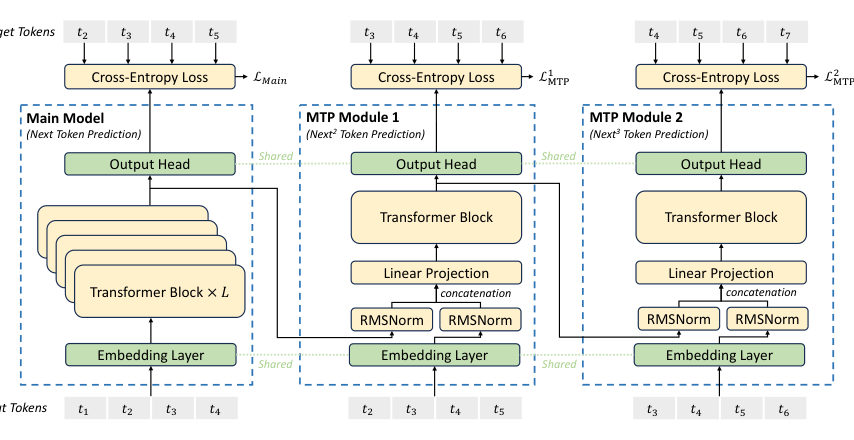
MayaAblations say it improves benchmark performance, and the module can simply be dropped for ordinary inference. Or kept — as a draft generator for speculative decoding.
LeoAnd there the report gives a number that carries its claim: the second token's acceptance rate runs about eighty-five to ninety percent across the topics they tested — about one point eight times more tokens per second in their setup. Not a universal guarantee. But it's a training-time choice paying rent at serving time.
MayaThen the Polish Pass. After pre-training comes supervised fine-tuning on about one and a half million instances across domains, then reinforcement learning — but not the usual proximal policy optimization from our earlier episodes. They use Group Relative Policy Optimization — G-R-P-O — which samples a group of outputs, scores them, and uses the group itself as the baseline instead of training a separate critic model of similar size.
LeoWith rewards split by checkability. Math and code get rule-based rewards — tests, verifiable answers. Freer-form tasks get a model-based judge. For our company's assistant that's directly reusable: hard validators where the task has them, softer judges where it doesn't.
MayaThey also distill reasoning patterns from an internal DeepSeek-R1 model — while explicitly fighting to keep output style and length from ballooning.
LeoNow the Scoreboard, where I get to do my job. The base model beats the compared open base models across a wide spread of benchmarks — math and code especially. The chat model is reported as competitive with GPT-four-o and Claude three point five Sonnet on several evaluations.
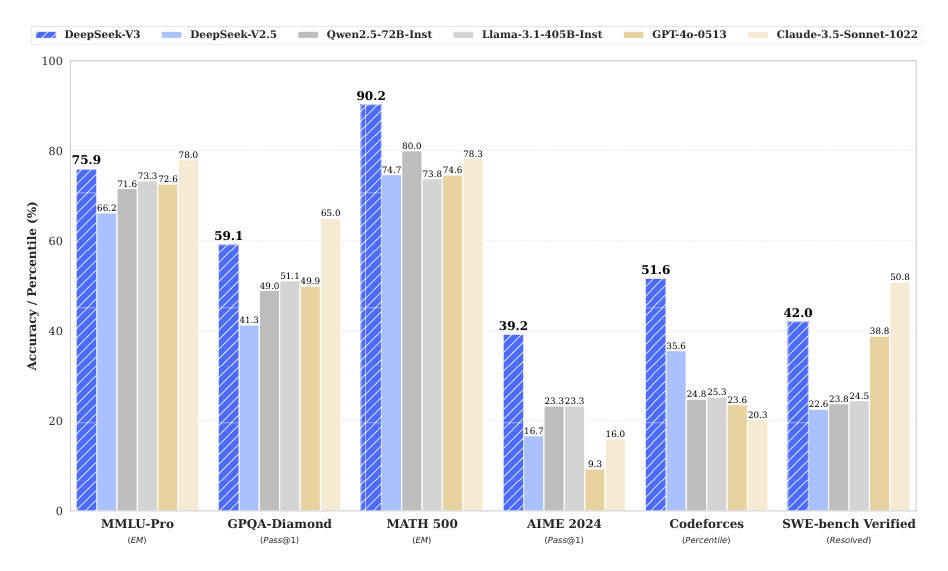
MayaBut?
LeoBut read it like an engineer, not a fan. Some evaluations are internal-framework runs. The report's own tables show V3 trailing GPT-four-o and Claude on English SimpleQA — plain factual recall — and trailing Claude on engineering-flavored coding measures like SWE Verified and Aider's edit format. Strong scorecard, real gaps, and none of it measures your proprietary tasks.
MayaWhich lands us at the Loading Dock. The weights are open, the context is a hundred twenty-eight thousand tokens, the license allows commercial use. And the serving story is what our debate predicted: inference frameworks, expert parallelism, serious GPU memory, often multi-node. Generation speed more than doubled over DeepSeek-V2 in their setup — and the authors still list it as needing improvement.
LeoSo what does the mid-sized company actually do?
MayaProbably not run it locally. The realistic play: keep a small open model on the device, and route the rare, hard, privacy-approved jobs — that migration script — to a hosted V3 endpoint or a private cluster deployment.
LeoOr treat the report as a design map instead of a purchase order. It hands you the checklist: capacity versus activated compute, routing balance, cache size, precision, communication overhead, post-training matched to how your tasks are checked. That checklist outlives this model.
MayaAnd that's the deep lesson. DeepSeek-V3 isn't "a big open model." It's evidence that frontier open-weight capability now comes from co-design — architecture, data, precision, parallelism, kernels, reward setup, deployment layout, tuned as one system. V3 is the sparse route, where openness meets data-center engineering head-on.
LeoSparse scale buys possibility, not simplicity. The router, the dial, the precision system, the serving plan — they're part of the product, and pretending otherwise is the easiest way to misread the paper.
MayaFor your own model stack, then: where would sparse capacity create real leverage — and where would the routing and deployment complexity quietly erase the benefit?
Source material
← Back to Mastering Language Models: From Architecture to Optimization