Transcript
MayaPicture a research archive in the nineteen-sixties. The collection has outgrown the building — kilometers of shelving, no budget for a second site. So the librarians put the whole thing on microfilm. Every page still readable through the viewer, at a fraction of the shelf space.
LeoOkay…
MayaHere's the rule that makes it work, though. Scholars keep doing new work on that collection — annotations, cross-references, corrections. But nobody writes on the film. The film is read-only by physics. All the new scholarship goes into fresh notebooks, full-sized paper, kept beside the viewer.
LeoRead the compressed thing. Write somewhere else entirely.
MayaThat sentence is today's paper. The model is the archive. Four bits is the microfilm. And the LoRA adapters are the notebooks.
LeoWhere we left off: LoRA — Low-Rank Adaptation — froze the base model and trained two thin matrices beside it. Trainable parameters collapsed by orders of magnitude. But the frozen giant still had to sit in GPU memory at full width, and that bill never moved an inch.
MayaToday's paper goes after exactly that bill. QLoRA — Efficient Finetuning of Quantized Large Language Models. Q for quantized. The question it asks is blunt: can you keep the frozen base in four-bit form, train LoRA adapters through it, and lose nothing?
LeoAnd the headline, because it's the reason everyone knows this paper: a sixty-five-billion-parameter model, fine-tuned on a single forty-eight-gigabyte GPU — while matching full sixteen-bit fine-tuning performance. In their setup, on their evaluations.
Maya[chuckle] You got the caveat in before the sentence even ended.
LeoBecause it matters, and we're coming back to it. But take the result at face value for a second. That's a model you used to need a cluster to touch, now trainable on one card you can rent by the hour.
MayaAnd it changed the texture of the field almost overnight. Fine-tuning very large open models stopped being a lab-cluster activity and became something a small team could at least attempt.
LeoMechanics, then. Quantization first, plain language.
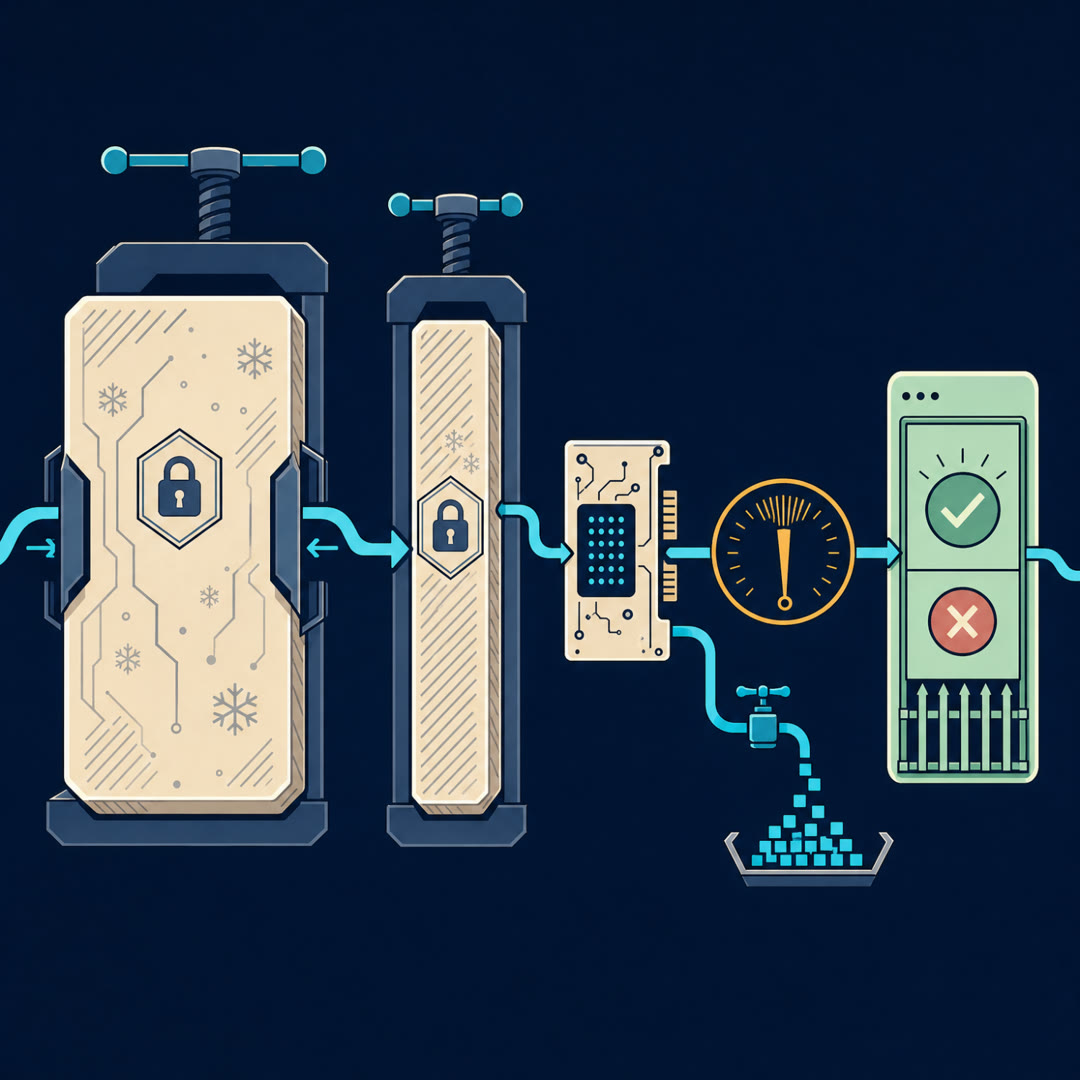
MayaQuantization is storing numbers with fewer bits. A model weight normally lives as a sixteen-bit or thirty-two-bit number — fine gradations, lots of memory. Squeeze it to four bits and each weight can take only one of sixteen possible values. Every weight gets rounded to its nearest allowed value.
LeoSixteen values standing in for everything a weight used to be. That sounds violent.
MayaIt is violent — done naively. Which is why the paper's first contribution isn't "we used four bits." People had tried four bits. {pause=0.7} It's choosing which sixteen values.
LeoGo on.
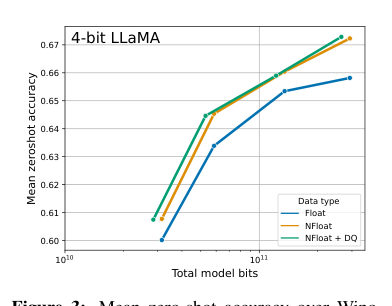
MayaThe data type is called NormalFloat four-bit — N-F-four. The insight: trained weights aren't spread evenly across their range. They cluster, roughly in a bell curve — most weights near zero, fewer and fewer out at the edges. So instead of spacing your sixteen allowed values evenly, like ruler marks, NF4 places them where the weights actually live. Dense near zero, sparse at the tails.
LeoBuild the shelves where the books are.
MayaAnd the payoff is direct: buckets that match the distribution lose less information per rounding. Same four bits, less damage.
LeoAnd there's another trick stacked on top of that one. Double quantization. Which sounds like a joke — quantizing the quantization?
Maya[chuckle] It's exactly what it sounds like, and it's real money. Quantized weights can't stand alone — each block of them needs a scaling constant to map those sixteen coarse values back to actual magnitudes. Those constants get stored at higher precision, and across billions of weights they add up. So QLoRA quantizes the constants too.
LeoThe boxes are compressed, and then someone notices the labels on the boxes are taking up a shelf of their own.
MayaSo you compress the labels. A small win per block, multiplied by billions of weights.
LeoAnd the last safety net is paged optimizers.
MayaThis one's about spikes rather than steady state. Training memory isn't flat. Long sequences and optimizer bookkeeping create sudden peaks, and a peak that exceeds your GPU for one moment—
Leo—kills the whole run. Hour nine, gone.
MayaPaged optimizers use unified memory between the GPU and the CPU, so a spike spills over gracefully instead of crashing. Slower for the moment the valve is open, but the run survives.
LeoWhen you're on a single GPU at the edge of capacity, "slow for a minute" versus "dead at hour nine" is the whole project.
MayaThat's why it's in the paper as a contribution and not a footnote.
LeoSo stack it up. LoRA cuts trainable parameters. Four-bit storage shrinks the frozen base. NF4 makes the four bits hurt less. Double quantization shaves the overhead off the compression itself. Paged optimizers catch the spikes. Five mechanisms, one budget.
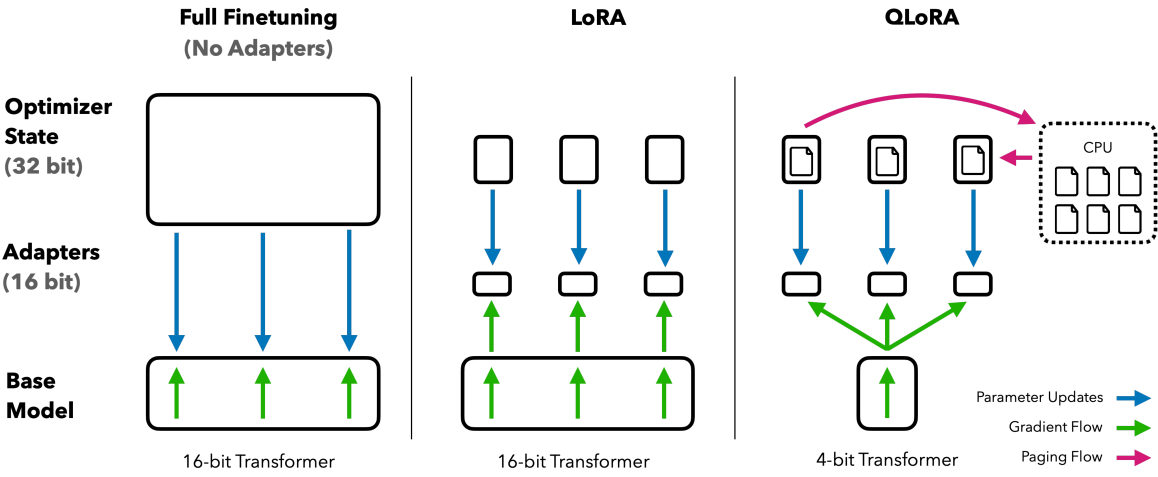
MayaAnd one rule holds it all together: the base is never written to. Gradients flow backward through the frozen four-bit model — you read it, you compute with it — but every update lands in the LoRA adapters, which stay at training precision. The microfilm gets read through the viewer. The notebook takes the ink.
LeoWhich answers the question I was about to ask — doesn't learning need precision? And the answer is: the precision lives where the learning lives.
MayaIt also marks a distinction that trips people. QLoRA is not training a four-bit model from scratch. The model learned everything it knows at high precision, during pretraining. QLoRA compresses that finished knowledge for the adaptation phase and routes the new learning down a separate, precise side path.
LeoThe scholarship was done before the microfilming. Nobody's asking anyone to write a dissertation at four bits.
MayaNow bring back the hospital team from this topic — the discharge-note summarizer. Last episode they priced LoRA, and the adapters were cheap. But the base model they actually wanted wouldn't fit on the records-office workstation.
LeoAnd QLoRA is the version of the story where the thirty-three-billion-parameter model they wanted runs on the hardware they already own. That's not a benchmark abstraction — that's a team that gets to run the experiment at all versus a team that doesn't.
MayaWith limits worth saying out loud. Activations still take memory at full size — sequence length and batch size still push on the same wall. Four-bit kernels can be slower or fussier depending on hardware. The door is open; the room still has furniture in it.
LeoPossible, not free. Good. Now the part I respect most. The paper didn't stop at the method, right?
MayaFar from it. They fine-tuned more than a thousand models across datasets, model families, and scales, and used that sweep to study instruction following and chatbot quality. Their best family, called Guanaco, scored remarkably well on the Vicuna benchmark in their own evaluation.
LeoAnd here's the respect part: the same paper that posts the great chatbot score spends real space warning you not to trust chatbot benchmarks. Automated ratings, narrow test sets — the authors say current evaluations may not measure what users actually value.
MayaA paper that hands you a sword and a warning about swords.
LeoRare shape.
MayaOne more finding from that thousand-model sweep outlived the memory tricks: data quality beat data quantity. A small, carefully built instruction set could outdo a huge noisy one.
LeoFor the hospital, that's three hundred summaries the chief resident actually checked beating a million scraped notes nobody read. That result became a recurring theme in specialization far beyond this paper.
MayaWhich brings us to the argument. Because this paper opened a door, and every team standing in front of it now has the same choice.
LeoOne GPU. Do you take the big model at four bits, or a smaller model at full precision? Take a side.
MayaThe big one, and not timidly. Scale buys capability you cannot fine-tune into a small model — broader language coverage, stronger reasoning, more graceful handling of the input nobody anticipated. For years the only reason to skip the larger model was that you couldn't afford to touch it. QLoRA removed that reason. Choosing the small model now is leaving capability on the table out of habit.
LeoAnd I'll take the small one out of arithmetic, not habit. Every quantization is an error term you've agreed not to look at. The averages come out clean — but the damage doesn't land evenly. It pools in the corners no benchmark visits. The rare drug-interaction note, the discharge summary with the weird edge case — the places I can least afford a compressed model's rounding to land are exactly the places the score sheet never checks.
MayaExcept your comparison is rigged — it's not compressed versus perfect. It's a compressed big model versus a small model that may lack the capability entirely. You're weighing a rounding error you can measure against a missing ability you can't—
Leo—fine. When the task genuinely needs the scale, that argument wins, and I'll say it plainly: for broad reasoning, take the big model and quantize. But our summarizer is narrow, repetitive, format-bound. Smaller, simpler, full precision: faster inference, fewer moving parts, no quantization surprises waiting in the audit.
MayaAnd I'll concede the operations side — the small model is a simpler machine to own. So neither side wins in the abstract, which is, annoyingly, the resolution.
LeoThe deciding layer is evaluation — and not of the method, of the exact configuration you'll deploy. This model, this adapter, this precision, this prompt, this context length, this latency budget. Test the thing you ship, on the tails you fear, and let that decide.
MayaSigned. That's more concession than I planned to hand out today. [chuckle]
LeoOne hidden cost before the close, because people get it wrong constantly: weights are not the whole memory bill. Optimizers like Adam carry extra statistics for every trainable parameter. Gradients need space. Activations need space. Temporary buffers need space. "Sixty-five billion parameters at four bits" is the starting line of the estimate, not the answer.
MayaTraining is a different animal from inference. Inference is mostly weights, activations, and the generation cache. Training drags a whole bookkeeping department along behind it — which is precisely the mess the paged optimizers exist to manage.
LeoAnd the lesson continues after training. A QLoRA-tuned model is not one tidy file. It's a quantized base, an adapter, a tokenizer, a quantization configuration, and serving code that has to reassemble all of it exactly. If production loads any piece differently than training did, your model card describes a model you are not actually running.
MayaMm — seen that one.
LeoSame discipline when comparing experiments. If two tuning runs differed in kernels or sequence length, and the only variable on paper was the dataset, you may end up crediting the data for what the configuration did.
MayaEfficient fine-tuning is a measurement discipline wearing a modeling costume.
LeoStealing that.
MayaSo place this paper on the topic's arc. LoRA shrank what you train. QLoRA shrank what you train against — the frozen base dropped to four bits, and in their setup, quality held. Which sets up the next question in a way the field couldn't resist.
LeoHow low does that floor go.
MayaNext episode is LowRA, and it pushes adaptation below two bits per parameter — down where naive rounding stops working entirely and the whole game becomes deciding where each precious bit gets spent.
LeoFour bits sounded violent at the top of this episode. Two is going to be a fight.
MayaSo carry this one out the door: you get one GPU and one week — do you spend them on a smaller model you can touch at full precision, or a bigger one you can only reach through compression?
Source material
← Back to Mastering Language Models: From Architecture to Optimization