Transcript
MayaA math olympiad announces one strange rule this year: a team may submit as many answers per problem as it likes before the bell, and the graders keep only the best one. Two coaches walk away with opposite plans. One keeps polishing his star — the deepest thinker in the building, one beautiful answer per problem. The other looks at her quick, steady kid and thinks: under this rule, ten decent attempts may beat one brilliant attempt.
LeoAnd the bell decides.
MayaThe bell decides. But notice what just happened — a rule about how answers get submitted reached backward and changed who you would train. And how long you'd train them.
LeoWhich turns out to be today's paper in miniature. Quick orientation: last episode, S-S-D — self-distillation — pulled the bottleneck out of the machine room entirely. A model fine-tuning on its own raw samples, no teacher, no grader, no referee — attacking the post-training bill instead of the hardware.
MayaAnd today the bill moves one more step down the line, to serving time — then does the genuinely strange thing. It reaches all the way back to the first decision anyone makes about a model: how big, and how long to train.
LeoTitle?
MayaTest-Time Scaling Makes Overtraining Compute-Optimal. The last paper of our topic, and it closes Topic 3 by picking a fight with Topic 2.
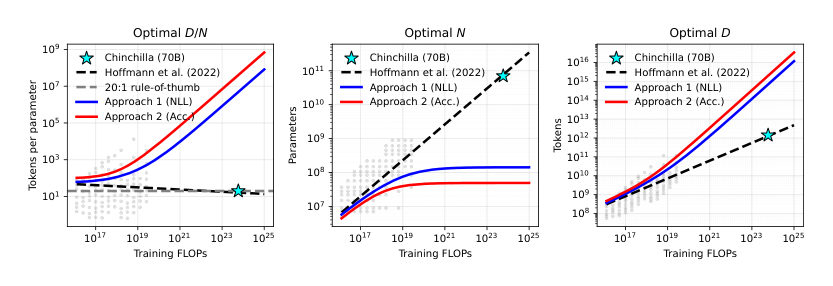
Leo[chuckle] Chinchilla should be nervous. Topic 2's headline was the compute-optimal recipe: fix a training budget, balance model size against training tokens, get the most model per unit of compute. That result reorganized how the field trains.
MayaAnd this paper doesn't say the recipe is wrong — it says the recipe answered a narrower question than everyone treats it as answering.
LeoDefinitions before claims, then. "Overtraining" sounds like an insult, and "test-time scaling" sounds like a slogan.
MayaTest-time scaling is spending extra compute at answer time instead of training time. Sample several candidate answers and vote among them. Run a verifier over the attempts. Think in longer drafts, or search. Anything where the system buys accuracy with more inference rather than a better single forward pass.
LeoAnd overtraining?
MayaTraining past the point the pretraining-only law calls balanced — pushing more tokens into a smaller model than the classic recipe prescribes. It doesn't mean bad training. It means: relative to a law that counts only training compute, you overspent on tokens.
Leo"Relative to" is doing a lot of work in that sentence.
MayaAll of it — change the accounting and the same training run stops being a mistake. Here's how— let me hold it this way. Every model runs two meters. The training meter spins once. Enormous number, but once. The serving meter spins on every query, for the life of the deployment.
LeoMm.
MayaClassic scaling laws optimize the first meter and never glance at the second. Then test-time scaling makes the second meter spin harder — sample eight answers and vote, and you pay inference eight times for one question. The serving meter stops being a footnote. Over a deployment's life, it can be most of the bill.
LeoThat framing I'll accept without a fight. So state the paper's actual move.
MayaIt writes down Train-to-Test scaling laws — T-squared, in the paper's shorthand. One end-to-end budget, three knobs turned jointly: how big the model, how many training tokens, how many samples drawn at inference time. Not the best model given training compute — the best system given everything you will pay.
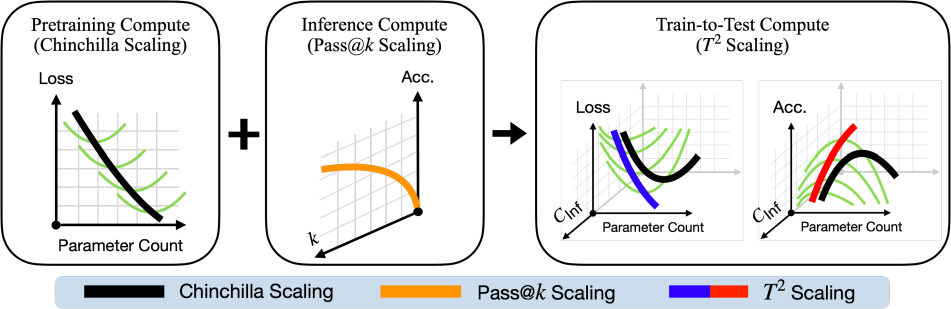
LeoThree knobs, one bill.
MayaThat's the whole reframe.
LeoBefore we get there — defend its seat in this topic. Nine episodes of cables and kernels, and this one contains no hardware at all.
MayaBecause the topic was never really about the cables. It was about finding the bottleneck and redesigning around it. Same discipline, widest lens: training decisions aren't isolated, and the deployment strategy reaches backward to change what you should train.
LeoFair seat. So — under the bigger budget, the answer moves.
MayaIt slides. Per-sample price tracks model size — a smaller model is cheaper every single time you ask it anything. So a smaller model trained longer may be slightly weaker per attempt, but it buys more attempts for the same money.
LeoQuantity, on a budget.
MayaAnd if deployment takes many attempts per query, the optimum slides away from the balanced point. Toward smaller, trained longer. Into exactly the regime the old law labels overtrained.
LeoThat's an intuition, and intuitions are cheap. Evidence?
MayaEight downstream tasks. Across them, the paper finds that once inference cost enters the budget, the optimal pretraining decisions shift into an overtraining regime well outside what standard pretraining scaling suites even explore.
LeoHuh. Well outside.
MayaNot a nudge at the margin — the optimum lands in territory the canonical experiments never mapped, because the old accounting gave nobody a reason to go there.
LeoLand it on the team we've followed all topic. Sixty-four GPUs, a hundred-billion-parameter model that doesn't fit on any single device, nine episodes spent making it trainable — splitting, sharding, streaming.
MayaAnd this paper interrupts them before any of that starts, with an earlier question: is that the right model to train at all? If what they're actually building is an assistant that drafts several candidates per query and votes, the better use of the same sixty-four GPUs might be a smaller model trained far longer — cheap enough to sample ten times per question without wincing.
LeoHere's where I defend the canon, because it's getting caricatured. Chinchilla's entire virtue is that it's clean. Training compute is a number you actually know at decision time. Loss per unit of compute is comparable across labs and across years. The moment you fold inference into the objective, your "optimal model" depends on a forecast — query volume, samples per query, which test-time strategy — numbers nobody reliably has at pretraining time.
MayaTeams know their deployment patterns better than—
Leo—do they, though? Patterns change monthly. You optimize for ten-sample voting, the product ships single-shot with a long thinking budget instead, and your carefully overtrained model is now just… a small model. The pretraining-only law never lies to you, because it never guesses.
MayaIt never guesses because it answers a question nobody is asking anymore! No deployed reasoning system pays for exactly one forward pass per task. They retry. They vote. They run verifiers, they search. Pretraining-only optimality is the special case where the sample count equals one — and almost nothing in production lives in that special case now.
LeoHm.
MayaAnd the asymmetry is brutal. The training bill arrives once. The serving bill arrives millions or billions of times. Refusing to model the larger bill because it's harder to estimate isn't rigor — it's searching for the keys under the streetlight.
LeoFine. The accounting argument survives — fully, I'll give you that. If a system samples repeatedly, the balanced point can't be its optimum; that part is arithmetic, not opinion. What I won't concede is the precision. A law fitted to a usage forecast is exactly as good as the forecast underneath it.
MayaA real concession with a real edge left in it. So what would settle the rest?
LeoThe deployment profile. If a team can state how the model will actually be used — samples per query, query volume, the test-time strategy — then T-squared gives a strictly better answer than the pretraining-only recipe. If they can't, the overtraining prescription is a bet. A reasonable bet. Still a bet.
MayaAnd both of us would rather see that bet made with the whole bill on the table than with half of it.
LeoNo argument there — fight about the forecast, not about whether inference costs money. [chuckle] That stopped being controversial the first time anyone deployed anything.
MayaThere's a product-design reading I find almost more useful than the law itself. A coding assistant generates several candidate patches, runs the tests, asks the model to repair the failures.
LeoA retry machine.
MayaAnd for that system, the best base model is not the best one-shot model. It's the model with the best cost-quality curve across repeated attempts.
LeoWhich breaks leaderboard instincts. A larger model can win the one-shot accuracy column and still lose the cost-adjusted pass rate. The smaller overtrained one is the better engine because it's cheaper to crank.
MayaPass-at-k is the cleanest way to feel that — give the model a handful of tries, count success if any try lands. The moment that's your metric, per-sample cost is part of quality.
LeoOne thing I'd flag before this hardens into doctrine — keep the claim's edges clean. What the paper shows is the shift on its eight tasks, under its budgets. What people are already inferring — overtrain everything, always — is an extrapolation it doesn't owe us.
MayaWhat else would you flag?
LeoModels don't ship raw. They get post-trained, and a post-trained model can behave differently under sampling, reasoning, and verifier loops. A scaling law has to survive the way models are actually used — end of the pipeline included. That's open territory, not settled ground.
MayaAnd the diagnostic habit transfers even if the exact fits drift. When a team brings you a plan like this, ask for total task cost, not one training metric: samples generated, fine-tuning compute, inference spend, accuracy, pass-at-k, and the cost of the failed attempts.
LeoThe failed attempts are the unglamorous line everyone skips. The wrong answers you paid to generate and threw away are still on the bill.
MayaSo look at how far the bottleneck traveled in ten episodes. We started inside the box — memory pressure, cables, idle clocks. We went down into the kernels. Then the bill walked out of the machine room to data. And in the topic's final episode, the bottleneck is the entire path from training run to solved task — and the cheapest fix on the table is choosing a different model to train in the first place.
LeoFor the sixty-four-GPU team, that changes the review meeting one last time. The question is no longer "did the cluster stay busy" — the earlier episodes earned them that. It's the whole-bill question: this size, these tokens, this sampling strategy — does the system built from all three solve tasks more cheaply than the system they didn't build?
MayaBecause a model isn't only expensive when you train it. It's expensive every time you ask it to think, retry, or vote.
LeoThen take one question out of Topic 3 with you: when you compare two models, what's the honest unit — training compute, inference dollars, or the full cost of a task actually solved?
Source material
← Back to Mastering Language Models: From Architecture to Optimization