Transcript
MayaA calligraphy student fills a page with the same character, forty attempts. Some strokes land clean, some wobble, two of them blot. Then she does something that sounds like a waste of an evening: she lays a fresh sheet over her own messy page — nobody circled the good ones, the wobbles are all still there — and traces all forty.
LeoBlots included?
MayaBlots included. No teacher in the room. And after a few evenings of this, her hand is steadier.
LeoMy prediction runs the other way. Trace your wobble, get a more confident wobble. Somebody has to grade the page, or the page can't teach you anything.
MayaHold that objection — it's the whole episode. Today's paper does the machine-learning version of the tracing trick, and the title admits exactly how it feels: Embarrassingly Simple Self-Distillation Improves Code Generation. S-S-D, if you want the short form.
LeoQuite the change of scenery. Last time we were as deep inside the silicon as this series gets — FlashAttention-Two re-dividing attention's labor between thread blocks and warps so the chip finally stayed busy.
MayaAnd today the bottleneck walks out of the machine room. Seven episodes of chips, memory shelves, cables, schedules. This paper says: fine, your cluster is efficient — now look at everything you pay for besides the hardware.
LeoMeaning data.
MayaMeaning labels, teachers, graders, attempts — the whole apparatus that normally surrounds a model after pretraining. SSD asks whether a model can get better at code generation using nothing but its own raw outputs. No human labels. No stronger model. No checker proving the code even runs.
LeoPlace it in the family tree first, because "distillation" carries baggage.
MayaClassic knowledge distillation is a hand-me-down. A stronger teacher model generates the training signal; a smaller student learns from it. Self-distillation snips off the word "stronger." The model is both the generator of the training data and the recipient of the update. It writes the page, then traces the page.
LeoAnd the recipe. Say it out loud, because I want to hear how little is actually in it.
MayaSample solutions to coding problems from the model under decoding settings you choose — a temperature, a truncation rule. Collect the samples. Fine-tune the model on them with completely standard supervised fine-tuning. That's the loop.
LeoThat's it?
MayaThat's why "embarrassingly" made the title.
LeoThen let me name what's missing, because the absences are the claim. Post-training pipelines usually keep three figures in the room. The teacher — a stronger model whose outputs you imitate.
MayaGo on.
LeoThe grader — a verifier that actually executes the code against tests before a sample earns its way into training. And the referee — a reward model with a whole reinforcement-learning loop wrapped around it.
MayaThree chairs. SSD empties all three. No teacher, no grader, no referee anywhere in the core recipe.
LeoThe grader's chair is the one that worries me. No verifier means wrong code goes straight into the training set — unexamined, known to be partly wrong, fine-tune on it anyway. Everything the field has absorbed about models eating their own output says that should make things worse.
MayaThat's the respectable objection, and the paper answers it with evidence rather than theory — we'll get to the number. But first the mechanism it proposes, because there's a real idea here about why tracing your own messy page can work.
LeoGo.
MayaThe authors frame what they call a precision-exploration conflict in decoding.
LeoUnpack that.
MayaWriting code demands two opposite virtues at once. At the level of the plan — which algorithm, which structure — you want exploration, because the obvious first idea is often mediocre. At the level of tokens — syntax, small implementation details — you want near-perfect precision, because one wrong token breaks everything.
LeoAnd one decoding knob can't serve both masters. Turn sampling up and you explore plans but wander into bad tokens. Run it greedy and the tokens are careful but you're married to the first mediocre plan.
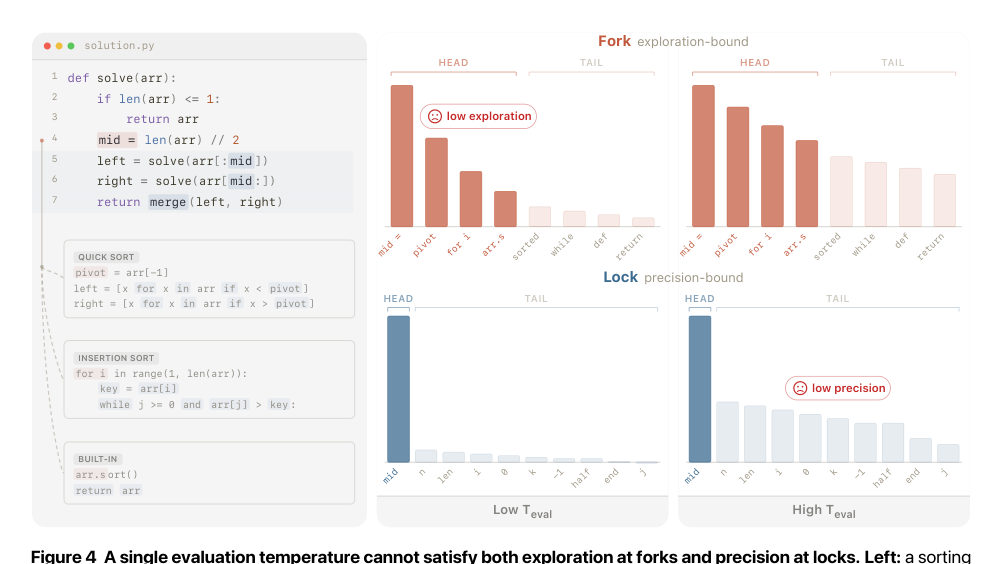
MayaEvery inference-time setting is a compromise between those two. SSD's move is to stop fiddling with the knob and change the distribution behind it. Fine-tuning on the model's own samples shifts probability mass away from the distracting low-precision tails and—
Leo—keeps the exploration. The range of plans survives; the token wobble gets suppressed.
MayaWhich is your calligraphy student. The strokes she lands consistently appear on every copy of the page. The wobbles scatter — a different direction each attempt. Trace the whole thing and the consistent core gets reinforced while the scatter washes against itself.
LeoSo the page does grade itself, in a sense. Consistency is the grade. [chuckle]
MayaWith one honest caveat: the page analogy is ours. The paper's framing is the precision-exploration conflict. Either way the bet is the same — the model's own distribution contains structure worth consolidating, even unverified.
LeoNumbers, then. And read them slowly, because I walked in skeptical.
MayaThe headline experiment takes Qwen three — the thirty-billion-parameter instruct model, spoken "kwen" — and runs the recipe on it.
LeoMeasured how?
MayaOn LiveCodeBench version six, pass-at-one goes from forty-two point four percent to fifty-five point three percent.
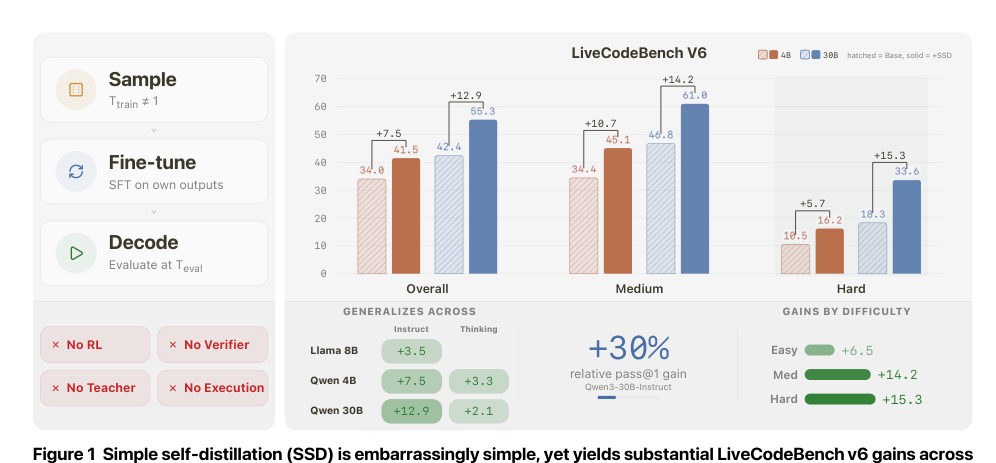
Leo[gasp] Forty-two four to fifty-five three. That's almost thirteen points — from tracing its own unmarked homework.
MayaAnd pass-at-one is the strict reading of "better." One attempt per problem, and the attempt has to pass the tests. No best-of-ten mercy.
LeoThe detail that actually moves me, though, is where the gains land.
MayaConcentrated on the harder problems. That matters because the cheap story — the method just polishes cases the model already nearly solved — predicts the opposite. Gains stacking up on hard problems suggest it's changing how the model behaves in uncertain solution spaces, not buffing the easy wins.
LeoFine. The result survives my first objection. It does not survive all of them, so let me get the rest on the table. Self-generated data amplifying errors is a documented worry for a reason. If the model's generations carry a systematic bias — a consistent wrong habit, not a scattered one — the tracing trick reinforces exactly that habit. The scatter argument only works for errors that scatter.
MayaConceded, fully. Poor self-training can entrench mistakes, and nothing in SSD is automatically safe across domains. The counterargument is empirical, not theoretical: with the right sampling setup and the right task, the model's own distribution held enough useful signal for supervised fine-tuning to consolidate. That's a much narrower claim than "self-training is solved."
LeoAnd "the right task" is doing real work in that sentence. Code is unusual.
MayaUnusually well-suited, maybe. The output distribution in code has sharp constraints — one token can break syntax, one wrong branch fails the tests. When correctness is that brittle at the token level, reshaping token probabilities buys a lot. Prose doesn't punish a wobbly token the same way.
LeoSo the open engineering question is where else a model's own distribution carries enough signal — and how you'd detect, in advance, when it doesn't. The paper doesn't hand you that detector.
MayaIt doesn't. So bring it back to our team — sixty-four GPUs, the hundred-billion-parameter model, every idle second billing somebody. Pretraining is done. Now they want it better at code, and look at what each of those three chairs would cost them.
LeoThe teacher means renting or hosting a stronger model and paying for every token it writes. The grader means building and operating an execution sandbox — real engineering, real compute. The referee means standing up an entire reinforcement-learning pipeline.
MayaAnd SSD's bill is inference on a cluster they already own, plus one standard supervised fine-tuning run. The same sixty-four GPUs we spent seven episodes keeping busy can generate the whole dataset overnight.
LeoThe cheapest upgrade in the topic. Not one new cable.
MayaWhich is why this episode belongs in the bottleneck story even though there's no kernel in it. Compute was never just hardware. It's also how many attempts, labels, checks, and post-training cycles a result demands — and SSD attacks that side of the bill.
LeoBefore anyone sprints off to try it, though — say the team actually runs the experiment. Here's the review I'd hold when the results land. The cost question first: total task cost, not one flattering metric.
MayaItemize it.
LeoSamples generated, fine-tuning compute, inference cost, accuracy, pass-at-k, and the cost of every failed attempt along the way. A run can improve one number and quietly damage another.
MayaThe baseline question next, I assume.
LeoAlways. If the elegant method beats a weak baseline but loses to a well-tuned plain setup, the story isn't finished.
MayaAnd the third?
LeoThe habit question — the one I care about most. Are the gains broad, or did we mostly teach the model to repeat what it already does? Benchmark transfer is the tell. One benchmark moving alone is a warning, not a triumph.
MayaThat review travels well beyond this paper. And so does the larger frame. Some methods matter because they make one model better. Others matter because they change which experiments whole teams can afford — and SSD is squarely the second kind. It lowers the entry price of post-training improvement.
LeoWith the ceiling stated honestly: it's a low-friction direction, not proof that labels, execution checks, or human feedback stopped mattering. Anyone applying it still owes the monitoring — transfer, failure modes, whether improvements stay where you wanted them.
MayaSometimes a field needs a result this plain — something so simple it forces everyone to re-ask what all the expensive machinery was actually buying.
LeoWhich leaves the question for the walk home. If a model can get better by studying its own unmarked attempts, where exactly is the boundary between cheap improvement and self-reinforcing noise?
Source material
← Back to Mastering Language Models: From Architecture to Optimization