Transcript
MayaMoving day. The truck is parked right at the front door — nobody is driving anything across town this time. Full crew on the clock, three stairwells between the apartment and the street. And they still lose the whole afternoon.
LeoTo what?
MayaStand in the lobby and watch. One mover spends twenty minutes with a tape gun, shrink-wrapping lamp cords, while packed boxes pile up behind him. Two of the three stairwells sit empty, because the chief sent everyone down the same one. And inside the truck, every box gets passed over the same man's head to reach the back wall.
LeoSo nothing is far away and nobody is lazy. Same furniture, same truck — the division of labor is the villain.
MayaToday's paper re-divides the labor.
LeoFlashAttention-Two — faster attention with better parallelism and work partitioning. Same lead author as the original, about a year later. And the load-bearing phrase is the last one. Work partitioning: who, inside the chip, does which slice of the job.
MayaWhich picks up exactly where we left off. Last episode, FlashAttention ended attention's commute — tile the computation through the tiny on-chip memory, carry the running tally, and the giant score table never parks in main memory at all.
LeoThe sequel opens with an awkward audit of that triumph. Trips: gone. Math: identical. And the chip is still nowhere near as busy as it could be.
MayaTheir own kernel.
LeoTheir own kernel. Nobody audits one harder than the person who wrote it.
MayaSo the question changes. Episode six asked, can we stop wasting traffic? This one asks, can we keep the GPU as busy as a matrix multiply?
LeoWhy is matrix multiply the bar to clear?
MayaIt's the chip's native gait. GPUs carry specialized units that make matrix multiplication the fastest thing they do — when one is running, the silicon is earning its price tag. Everything else runs, comparatively, in the slow lane.
LeoAnd attention is mostly matrix multiplies. The token-to-token scores are one, the weighted average at the end is another. In principle it should fly.
MayaIn principle. The paper's audit finds three places the labor goes wrong instead — and they map straight onto our movers. The tape gun. The empty stairwells. The over-the-shoulder pass.
LeoTape gun first.
MayaThe tape gun is all the work that isn't lifting. Attention's arithmetic is not— let me come at it through the tally. That running tally from last episode needs maintenance: comparisons, rescaling, small bookkeeping operations on the side. None of it is matrix multiplication. Counted in raw operations, it's a small fraction of the job.
LeoBut the hardware runs it at a crawl compared to its matmul units. So a sliver of the wrong kind of work eats an outsized slice of the clock.
MayaThat's the part people find backwards — a little slow-lane math can hold up the whole fast lane. So the tape-gun fix is to rework the bookkeeping. Keep the tally honest while doing meaningfully less of that side work, so the kernel stays on its best tool.
LeoA worker who's brilliant at lifting, kept busy taping cords. [chuckle] I've staffed projects like that.
MayaOn to the empty stairwells. This one needs thirty seconds of geography. A GPU keeps itself busy by handing out work in chunks called thread blocks, spread across the chip's many compute engines.
LeoHow many engines are we talking?
MayaEnough that filling them is its own problem. Occupancy is the plain question hiding under the jargon: how many of those engines actually have a chunk in hand?
LeoAnd if the answer is "few," you bought a building's worth of movers and staffed one stairwell.
MayaWhich is what the audit found. The original kernel could leave a single attention head's work too lumpy — if one head doesn't expose enough chunks to fill the machine, engines stand idle. FlashAttention-Two splits even a single head's work across many thread blocks.
LeoWhen does a run actually hit that, though? It smells like an edge case.
MayaIt's the configurations our sixty-four-GPU team keeps eyeing — long sequences.
LeoOf course it is.
MayaExactly the runs FlashAttention made thinkable in the first place. The deeper the context, the lumpier the work, and the more those empty stairwells cost.
LeoHuh. So the first paper opened the door to long contexts, and the second makes walking through it affordable. What's left on the audit?
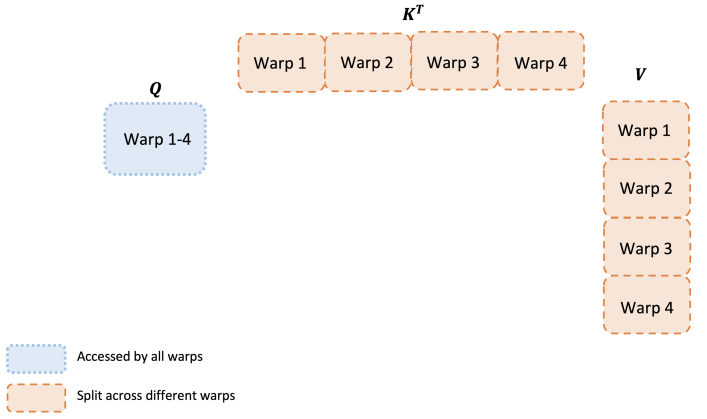
MayaThe over-the-shoulder pass — and now we're inside a single crew. One thread block is staffed by warps: small squads of threads the hardware marches in lockstep. Squads in the same block coordinate through shared memory. Think of it as the whiteboard in the crew room.
LeoThe box over the head.
MayaEvery pass across that whiteboard costs writes, reads, and squads waiting on each other. FlashAttention-Two re-divides the tile's work between warps so less of it crosses the whiteboard — each squad carries more of its own piece end to end, and the synchronization bill shrinks.
LeoThree fixes, then. Less slow-lane math, more filled stairwells, less crew-room chatter — and not one of them touches what gets computed.
MayaSame exact attention out the other end. That's the franchise signature twice over now: change the route, change the schedule, never the answer.
LeoStopwatch time, because the sequel has numbers. Around two times faster than FlashAttention — the kernel that was already the celebrated one. It reaches fifty to seventy-three percent of the theoretical maximum floating-point speed on the A one hundred, the data-center GPU these benchmarks live on.
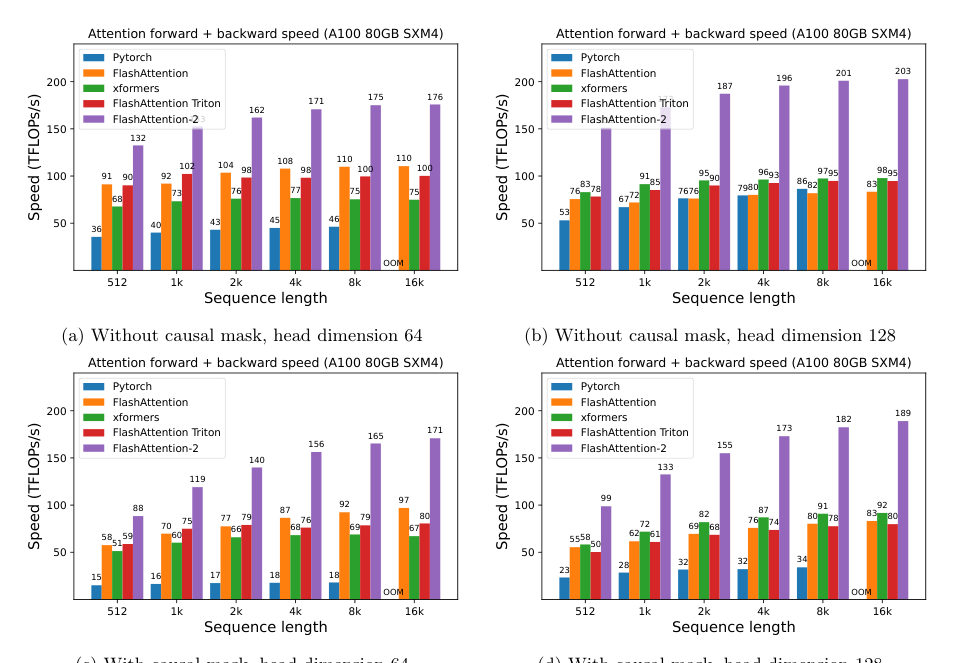
MayaDoubling the fast kernel.
LeoAnd the number I trust more, because it's end to end: GPT-style training at up to two hundred twenty-five teraflops per second, per GPU. About seventy-two percent model FLOP utilization.
MayaUnpack that one — it's the metric this whole topic has been circling.
LeoOf all the useful model arithmetic a chip could theoretically perform each second, the full training run actually delivers seventy-two percent. Not a kernel in a vacuum — the whole step, optimizer and communication and all, holding that pace.
MayaA schedule change inside one operation, visible on the bill for the entire run.
LeoI have to file an objection, though. I read this and a voice in my head says: is this research, or very good tuning? The math is untouched. The tiles are the old tiles, the tally is the old tally. They moved work between squads. That reads like an engineering memo, not an algorithm.
MayaHonestly, I went back and forth on that myself reading it. But look at what the result depends on: the GPU's architecture, the memory hierarchy, how the computation maps onto blocks and warps. Get the mapping wrong and the same equations run at half speed. On hardware like this, the schedule stops being an implementation detail and becomes—
Leo—part of the algorithm itself. Fine, I'll grant it: the honest answer is both, and the both-ness is the lesson.
MayaBut?
LeoBut that concession cuts the other way too. If the winning partition is fitted to this chip's geometry — its engines, its squad sizes, its whiteboards — what happens on the next GPU generation?
MayaThat's the open question, and it deserves saying plainly: a work partition tuned for one chip is a hypothesis about the next one, not a guarantee.
LeoAnd the principles?
MayaThe principles travel — feed the strong units, fill the machine, cut the chatter. The particular split that achieves them gets re-audited, generation after generation.
Leo[sigh] So the chase doesn't end; it re-runs on every new chip. And even here — seventy-three percent of theoretical max still leaves a real gap. How much headroom is left is exactly the kind of number nobody can promise in advance.
MayaNotice what happened across the two papers, though. The first answered a broad question: where does the time go? The sequel's questions are narrower and meaner — which operations aren't matrix multiplies, which warps are waiting, which blocks are under-filled.
LeoAfter every systems win, the remaining waste gets more specific.
MayaAnd harder to find. That's what a maturing optimization story looks like — the questions shrink as the easy money disappears.
LeoThen comes the week after the upgrade. Our team drops the new kernel into the hundred-billion-parameter run on their sixty-four GPUs. What gets measured before anyone celebrates?
MayaEnd-to-end throughput, never kernel speed alone — the habit carries straight over from last episode. Then the run's shape: the sequence lengths they actually train at, attention's memory footprint, occupancy across the chip.
LeoAnd the map.
MayaAnd whether the bottleneck moved. Attention gets cheaper, and the queue re-forms somewhere else — the feed-forward layers, communication between the sixty-four machines, the optimizer step, the data pipeline. A faster kernel redraws the bottleneck map; it doesn't erase it.
LeoThere's a budget consequence hiding in there, and it's the part I'd underline twice. When attention gets twice as cheap, longer sequence lengths and larger batch configurations become economically practical.
MayaWhich for our team is not a smaller bill — it's a different menu. Model shapes they had ruled out quietly come back into reach.
LeoKernel work changing model design from below. That's why a scheduling paper belongs in a language-model series at all.
MayaThe paper is on arXiv — FlashAttention-Two: faster attention with better parallelism and work partitioning — linked in the episode notes, and the work-partitioning diagrams reward a slow look.
LeoNext episode we climb out of the engine room entirely. A model teaching itself — self-distillation, embarrassingly simple by its own title's admission — and what that does to code generation.
MayaKeep the lobby view until then. The next time something you own gets a headline upgrade and still feels slow, stand in the lobby and watch before you buy anything: is the work actually too big — or is it just badly divided among the workers you already have?
Source material
← Back to Mastering Language Models: From Architecture to Optimization