Transcript
MayaA friend of mine once timed her laundry. Door to door: three hours. Then she timed the machines. Forty minutes washing, maybe forty-five in the dryer.
LeoWhere'd it go?
MayaHer car. The wash finished, she drove the wet clothes home — don't ask — drove back to run the dryer, home again, back once more to fold. The machines were never slow. The trips were the whole bill.
LeoSo the fix isn't a faster dryer. It's a chair. Stay in the building until the laundry's actually done.
MayaToday's paper is the chair.
LeoFlashAttention — full title, fast and memory-efficient exact attention with IO-awareness.
MayaQuite a title.
LeoAnd it breaks the rhythm of this topic. Last time we zoomed all the way out — the whole training cluster as one system, where the slowest piece sets the pace for everything else.
MayaToday we swing the lens the other way. All the way in. One GPU, one operation — attention itself. Because there's a laundromat inside the chip, and standard attention has been driving home between cycles.
LeoThe odd word in the title — IO-awareness — is the thesis. I-O, input and output: the reads and writes, the data traffic. This algorithm treats traffic as a first-class cost to design around, not a detail somebody cleans up later.
MayaSo, the floor plan, because "inside the chip" has geography most people never picture. Two kinds of memory, wildly unequal. High-bandwidth memory — H-B-M — is the GPU's main memory. Tens of gigabytes, fast by any civilian standard. That's the apartment across town: roomy, holds everything.
LeoAnd the counter?
MayaRight beside the compute units: on-chip memory, S-RAM. The counter next to the washing machines. Tiny — megabytes against gigabytes — but zero distance, and dramatically faster.
LeoHold that against what we all learned first, because the textbook villain is different. Attention is quadratic in sequence length — every token scores itself against every other token, so a thousand tokens means a million scores. Double the context, four times the work. That's the monster everybody points at.
MayaThe monster is real. But the paper opens with an accusation: we were doing too much traffic, not just too much math.
LeoMeaning what, concretely?
MayaWatch what a standard implementation actually does. It computes the full table of token-to-token scores and materializes it — actually writes the whole million-entry matrix out to HBM. Drives it home.
LeoAnd it's not done.
MayaNot close. It fetches the table back to normalize the scores into attention weights. Writes those home too. Then fetches them again to average the values into the output.
LeoThree full round trips, each one hauling a table that grows with the square of the context. The compute units spend their day waiting on traffic.
MayaRun that through our team — the hundred-billion-parameter model on the fixed cluster of sixty-four GPUs. Every attention layer, on every one of those GPUs, makes this commute on every single training step.
LeoStep after step.
MayaTheir cluster isn't slow because it can't multiply. It's slow because it keeps hauling the same giant table back and forth.
LeoAnd memory takes the hit before speed even comes up, right? That materialized table has to live somewhere.
MayaAt long sequence lengths it's enormous. Long contexts weren't blocked by the math so much as by—
Leo—by the parking. Nowhere to put a table that grows with the square of the context.
MayaSo, the move. Two ideas, locked together. The first is tiling. Don't process the— okay, here's the picture: cut the computation into blocks small enough to fit in SRAM. Load a block of queries and a block of keys and values onto the counter, compute that tile's scores right there, fold the result into a running output, move to the next tile.
LeoNo big table?
MayaNo big table. Never written, never parked — never fully exists anywhere. Nothing million-entry ever lands in HBM.
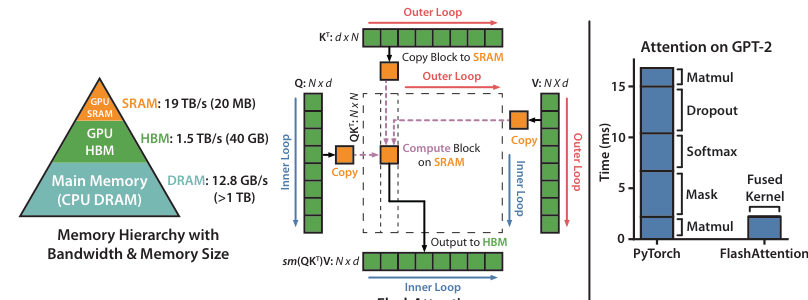
LeoWhich sounds lovely until you remember what normalizing requires. Softmax — the step that turns raw scores into attention weights — wants the whole row before it commits to anything. You can't normalize what you haven't seen yet. And a tile only ever shows you a piece.
MayaWhich is the second idea, the one that makes the paper sing: online softmax. As the tiles stream through, you carry a small running tally — the largest score seen so far, and a running sum — and each time a new tile arrives, you rescale everything already accumulated so it stays consistent with what just showed up. When the last tile lands, the answer is exactly what the full computation would have produced.
LeoExactly exactly? That word is doing legal work in the title. I want "exact" to mean exact — not "close enough that nobody sued."
Maya[chuckle] Mathematically the same attention output. Not a sparser pattern, not a low-rank impression of the table — the same numbers, computed in a different order, with the running statistics keeping the normalization honest the whole way through. The exactness is engineered, not hand-waved.
LeoAnd that's half the adoption story right there. A team swapping in this kernel — the actual GPU program that runs the operation — changes nothing about what the model computes. New route through the hardware, same math. No re-validation, no behavior drift to chase. The rare upgrade you can ship without calling a meeting.
MayaThe other half of the story is a fight. And it deserves to be had properly.
LeoGladly — I'll take the other camp, because it has a real case. By the time this paper lands, a whole research program says the fix is approximation. Attention is a square law, and you don't out-engineer a square law — you stop computing it.
MayaThe approximation camp.
LeoSparse methods score only the pairs that matter. Low-rank methods compress the table outright. They attack the asymptote itself — the theoretical operation count genuinely drops. Your tiling is a gorgeous polish on a doomed curve.
MayaThen why didn't the stopwatch move? That's the paper's blunt reply: many of those methods cut theoretical compute and fail to deliver wall-clock speedups — because they never cut the traffic. The table still gets hauled through memory, the kernel still stalls. And there's a quality bill on top: you changed what the network computes and have to hope it didn't matter.
LeoHope is unfair — those papers measure quality—
MayaThey measure it because they owe it! An exact method never takes on that debt at all.
LeoFine. Then it comes down to clocks, so let's read them — and I went into the results expecting kernel cherry-picking and found end-to-end numbers. Fifteen percent wall-clock speedup training BERT-large against the standing MLPerf training record. The record. Not some soft baseline.
MayaGo on.
LeoThree times faster on GPT-two at sequence lengths around a thousand tokens. And on the Long Range Arena benchmark — built specifically to stress long contexts — two point four times faster.
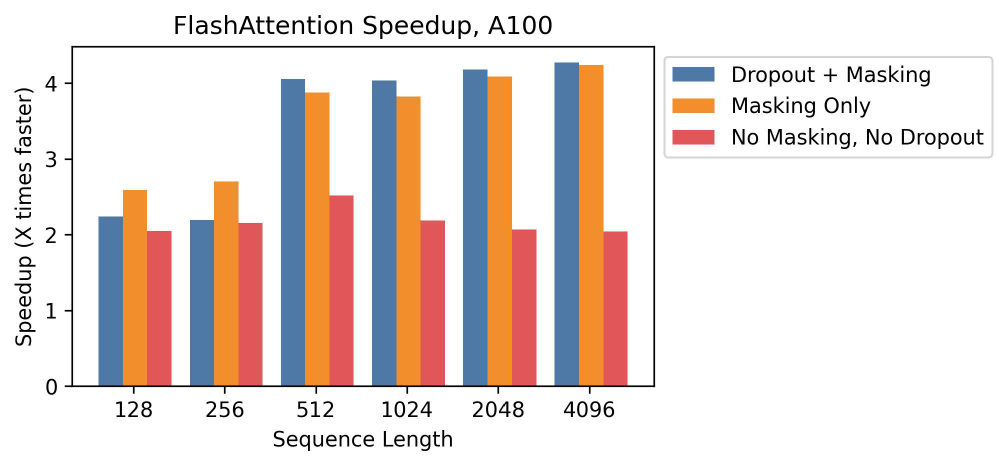
MayaOn a clock.
LeoOn a clock. So here's my concession, stated carefully: at the sequence lengths people actually train at, exact-but-IO-aware beat approximation at its own game — speed — while giving up nothing on quality. The wall-clock evidence is yours.
MayaAnd here's mine, because the asymptote doesn't dissolve. FlashAttention is still quadratic in compute. Double the context, four times the math — that law survives untouched. The paper repeals the traffic, not the arithmetic. Push sequence lengths far enough out and the square law collects eventually.
LeoSo the honest resolution: IO-awareness won the regime people actually work in, and pushed that regime's frontier outward. The approximation conversation isn't dead — it's waiting further down the curve, where the math itself becomes the bill again.
MayaMoving the frontier mattered, though. Once the materialized table stopped being the wall, longer contexts went from impractical to ordinary — and model designers started asking much greedier questions about sequence length.
LeoThe morning after, though. Our sixty-four-GPU team hears all this, swaps in the kernel — and their step time improves by noticeably less than three times. Did the paper lie to them?
MayaThe bottleneck moved. The kernel benchmark measures attention; the team's training step is attention plus everything else this topic has covered — communication between GPUs, pipeline scheduling, optimizer state, the data path. Clear one jam and the queue re-forms at the next.
LeoMeasuring what, then?
MayaEnd-to-end throughput first — never kernel speed alone. Then the run's shape: the sequence lengths they actually train at, because the win grows with context.
LeoAnd after that?
MayaAttention's memory footprint, to confirm the giant table is truly gone. And GPU occupancy — to see which bottleneck inherited the crown.
LeoThat last check is the reviewer's instinct this topic keeps drilling. A faster kernel that doesn't change the full training step is a benchmark, not a result. The question is whether the speedup survives contact with the rest of the system.
MayaThe design pattern underneath outlives the paper, and it's worth saying plainly: the formula was never the problem. The same math, the same operation count, got dramatically faster because someone respected the memory hierarchy. Asymptotic complexity is not the whole story — big-O counts the operations and says nothing about the commute.
LeoWhich is why you can't explain this speedup from the math alone. You need the hardware in the room.
MayaThe paper's on arXiv — FlashAttention: fast and memory-efficient exact attention with IO-awareness — linked in the episode notes, and the tiling diagrams are worth the visit on their own.
LeoNext episode, the same idea comes back sharper. FlashAttention-Two — the authors look at their own kernel and find it left speed on the table. Better parallelism, better division of labor inside the GPU.
MayaThe machines were never slow; the trips were. So pick one system you own that feels too slow — and before you reach for a faster machine or a cleverer formula, ask the question this paper asked: is it doing too much work, or making too many trips?
Source material
← Back to Mastering Language Models: From Architecture to Optimization