Transcript
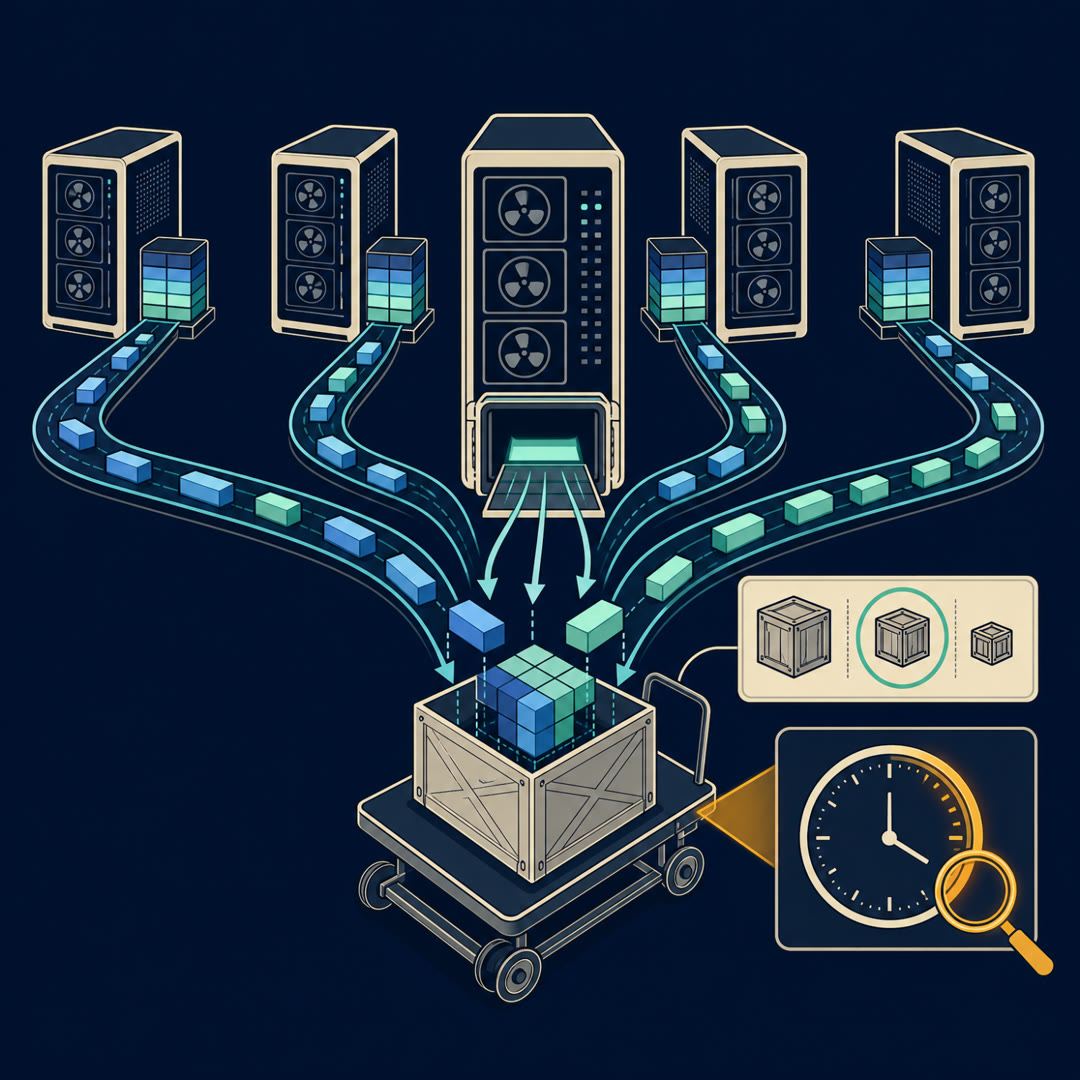
MayaWalk into a good machine shop and watch the bench, not the mechanic. There's no warehouse at that bench. A cart rolls up holding exactly the parts the next job needs, the job runs, and the cart rolls off with everything the bench is finished with.
LeoAnd the warehouse?
MayaSpread across the whole shop — every station keeps one aisle of it. Nobody hoards. And whether that shop hums or stalls comes down to two decisions somebody made before the first job of the morning: how big the crates are, and when the cart leaves.
LeoNot the mechanic's skill. Not the parts. Crate size and departure time.
MayaThose two decisions are today's entire episode.
LeoBecause today's the sequel. Last time, ZeRO won an argument — the waste in data parallelism was never the math, it was the copies, so shard the training state across the team and fetch pieces on demand. Today's source is what happens after the argument wins.
MayaThe idea moves into PyTorch and becomes Fully Sharded Data Parallel — F-S-D-P. FSDP from here on.
LeoAnd notice what kind of source it is. Not an arXiv paper. An engineering post from Meta — "Fully Sharded Data Parallel: Faster AI Training with Fewer GPUs." The format is the message.
MayaThis is the moment sharding stops feeling like a research trick and starts feeling like a daily tool. Which moves our conversation too. ZeRO's episode asked whether sharding is a good idea. This one asks what it takes to make sharding *ordinary* — something a team switches on without redesigning their model.
LeoSo, plain words before anything else. What is it?
MayaA data-parallel training algorithm. Every GPU still works through its own slice of the data — that rhythm survives untouched. But the model's parameters are sharded across the workers, and the system can optionally push parts of the training computation out to CPUs.
LeoSame rhythm, no full copies.
MayaAnd when a particular block of the model needs to run, the worker gathers the full parameters for just that block, runs its microbatch locally — local is the key word, the computation never leaves the GPU — and then lets the assembled copy go.
LeoThe cart arrives, the job runs, the cart leaves.
MayaThat's the loop. And the engineering question — really the entire engineering question — is what counts as a crate, and when the cart should roll.
LeoPut our team on it. The one we've followed all topic — hundred-billion-parameter model, sixty-four GPUs, a clock that bills every idle second. What does FSDP change for them on a Tuesday morning?
MayaMostly what they *don't* have to do. Nobody sits down to design a custom model-parallel layout — no deriving splits, no rewriting the forward pass. They keep their training script, wrap the model's blocks, and the sharding happens underneath.
LeoAnd the title's promise is the payoff: a larger model, trained more efficiently, often with fewer GPUs than naive data parallelism would demand.
MayaThat's the brochure, and for once the brochure is roughly honest.
LeoRoughly. Because "fully sharded" reads like "fully solved," and it is not. That phrase is doing some quiet marketing.
MayaFair pressure. The truer phrase would be fully *negotiable*. The system hides the complexity — it does not delete it.
LeoThen what's actually on the table? This is where the episode earns its keep. Start at the bench — what counts as a crate?
MayaThe wrapping policy decides— okay, here's the cleaner way in. FSDP makes engineers choose which blocks of the model get sharded as a unit. That choice is the wrapping policy, and it *is* the crate-size decision from this morning's shop.
LeoThe boundary is the decision.
MayaWrap too coarsely, and the gathered crate is enormous — memory spikes every time it lands on the bench. Wrap too finely, and the cart never stops moving — communication overhead on every tiny trip.
LeoSo the abstraction says fully sharded, but the performance lives at the boundaries. Where a wrapped unit ends, when the gather fires, when the memory gets released.
MayaWhich drags in the shop's other morning decision — departure time. Send the cart too early and crates pile up on the bench: the exact memory spike you were trying to dodge. Send it too late—
Leo—and the GPU stands there with empty hands, billing you anyway.
MayaSo memory under FSDP isn't a flat line. It climbs while a block computes, falls when the copy is released. The peak matters — and so does *when* the peak lands.
LeoHm. Peak and timing both.
MayaThere's a bargain hiding behind both of those, too. FSDP shrinks model-state memory, but activations can still dominate — especially at long sequence lengths.
LeoSo you throw some of them away and re-derive them during the backward pass. Activation checkpointing.
MayaPaying compute to buy memory back. It pairs naturally with sharding, as long as the extra compute is acceptable.
LeoAnd when even that isn't enough — when the state just won't fit on the GPUs?
MayaThen the shop rents an overflow annex — CPU offload. Move parts of the state, or parts of the work, out to CPU memory. It relieves pressure on the GPU. But the road between CPU and GPU is narrow, and if that transfer path runs hot, the whole run slows down.
LeoSo the honest summary of this tool: it converts one hard problem you couldn't solve into a handful of medium problems you can mismanage. [chuckle]
MayaWhich is genuinely an upgrade! The hard problem was a wall. Medium problems are a trade-off space — and you can profile your way through a trade-off space.
LeoThat's actually the post's own framing, more or less. Use FSDP to *enter* a better trade-off space, then profile the shape of it. Not "turn it on and forget it."
MayaNot a magic memory eraser. The gather timing, the wrapping, the checkpointing, the batch size, the overlap between communication and compute — all of it decides whether the run gets faster or merely fits.
LeoOkay, but here's the question sitting under this whole episode, and practitioners genuinely pull in two directions on it. Our team has FSDP running by lunch. A hand-built layout — the kind of careful surgery we covered two episodes ago — might still beat it. When does the custom job still win?
MayaWhen the model is strange enough. Unusual architecture, extreme sequence lengths, a throughput target with no give in it — a layout tuned to that exact shape can still beat the general tool.
LeoAnd the general tool's strongest card is the boring one: it composes with ordinary training code. Most teams, most models, most deadlines — the integration *is* the feature.
MayaPart of the appeal is honestly psychological. An engineer keeps thinking in modules — wrap this block, checkpoint this path, offload that state. Nobody invents a full parallel schedule from a blank page.
LeoSo I'll land it where the evidence lands it: the choice isn't ideological, it's situational. The model's shape, the sequence lengths, the cluster's wiring, and how many engineer-months the team can actually spend. General tool by default; custom layout when the defaults run out.
MayaWith one warning stapled to that. The simplicity is conditional. Skip the profiling, and FSDP will hide the problem right up until the throughput report disappoints.
LeoBecause a model can fit and still train too slowly. Fitting and training well are different achievements.
MayaWorth saying twice.
LeoThen here's the ticket that lands on your desk. Our sixty-four GPUs again. The team wrapped the model, it finally fits, everyone celebrated — and step time is ugly. Where do you look first?
MayaPeak memory, split by what's actually sitting in it — parameters, gradients, optimizer state, activations, temporary buffers, communication buffers. Each category has a different fix, so you measure them apart.
LeoThen?
MayaThen the timing side. All-gather time, reduce-scatter time, how much of each hides behind compute, and whether step time is steady or jittery from one step to the next.
LeoBecause the failure mode worth fearing is the quiet one: the sharding worked, the memory bill dropped — and the pain just moved into network time. The number on the dashboard improved while the number that bills got worse.
MayaBottleneck first, technique second. Same habit as the whole topic, and this tool rewards it more than most, because any one of those negotiations can be the thing that's actually hurting you.
LeoOne more reviewer's habit before the wrap-up. Compare against the simplest tuned baseline. If the sophisticated setup beats a sloppy baseline but loses to a well-tuned simple one, the story isn't finished.
MayaAnd zoom out once, because this tool's real legacy isn't one fast run. Some techniques train one model faster. This kind matters for what it makes *possible to try* — model sizes, sequence lengths, training recipes that whole teams previously couldn't touch.
LeoWhich is this topic's quiet thesis, restated. Distributed training isn't bragging rights. It changes which experiments researchers can afford, and those experiments shape the models everyone else ends up using.
MayaThe Meta engineering post is linked in the episode notes — short, readable, and the diagrams do a lot of the work.
LeoNext time we step back from single tools entirely — a survey of distributed training architectures, the view from the whole cluster, where machines fail and hardware refuses to match.
MayaSo leave the shop with this. FSDP works because it makes a powerful thing invisible — and it bites exactly when that invisibility gets taken literally. Look at the systems you lean on every day and ask: when should a training system feel invisible, and when should its engineers insist on seeing the knobs?
Source material
← Back to Mastering Language Models: From Architecture to Optimization