Transcript
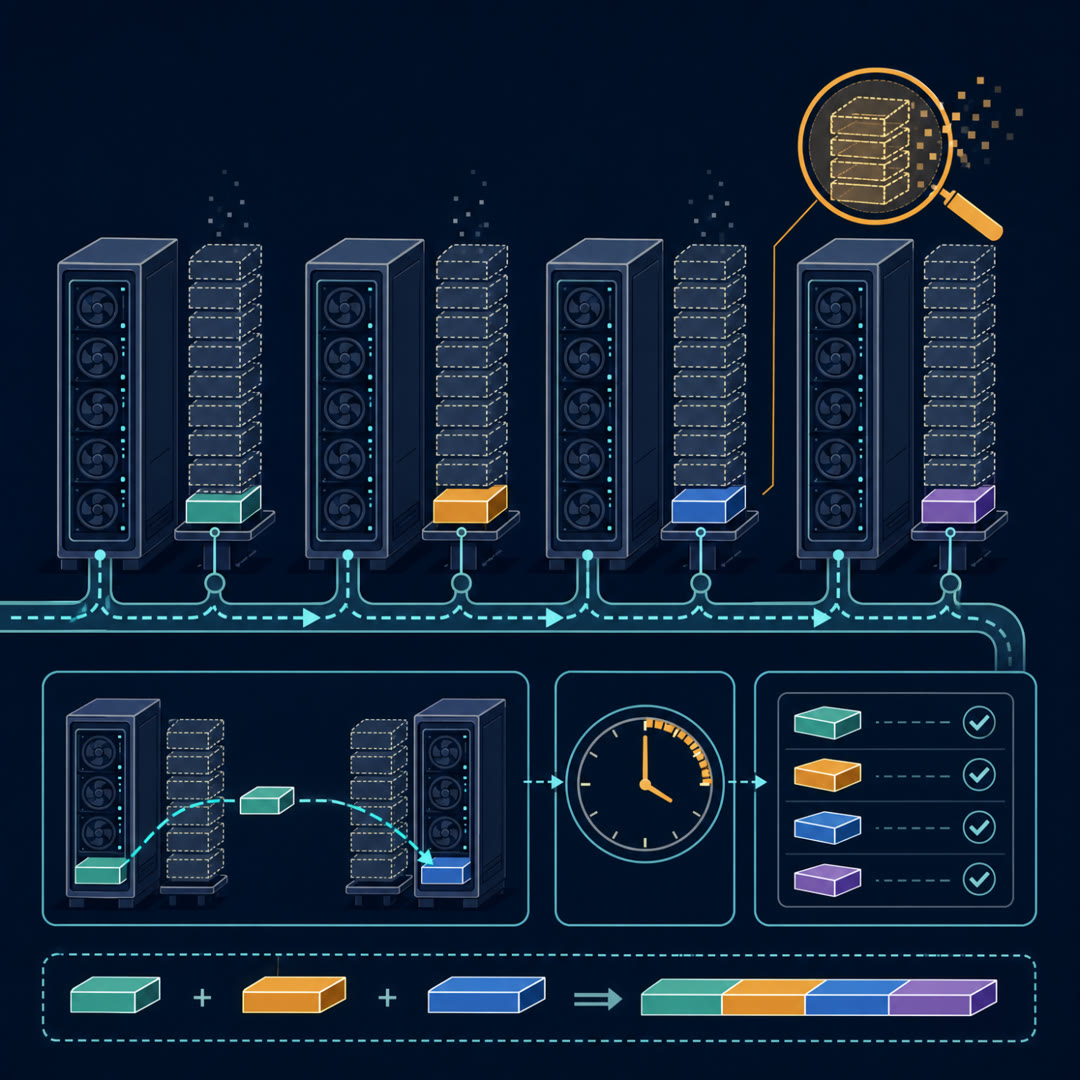
MayaPicture a town with eight branch libraries. And every branch — all eight of them — stocks the identical, complete collection. Every book, every shelf, duplicated across town.
LeoEvery branch?
MayaEvery branch. And it's worse behind the counter. Each one also keeps the full circulation ledger — the borrowing history and running notes for every single book in the system. Eight identical ledgers. And here's the absurd part: each ledger is fatter than the collection it describes.
LeoThat's the detail nobody believes at first. The paperwork outweighing the books.
MayaThen somebody at a town meeting asks the obvious question. Why does every branch carry everything? Keep one-eighth of the ledger at each branch, run a courier van on a tight schedule, and the town gets most of its shelf space back overnight.
LeoProvided the van is never late.
MayaProvided the van is never late. That's today's paper, whole.
LeoThe paper being ZeRO — spelled Z-E-R-O, the Zero Redundancy Optimizer. Full title: memory optimization towards training trillion parameter models. And this is the punchline I teased at the end of last episode.
MayaYou did promise.
LeoWe'd just watched Megatron-LM slice the matrix math inside every layer — careful surgery, communication placed exactly where partial results meet, all of it bounded by the fast wiring inside one server.
MayaAnd ZeRO walks in and asks the question that sounds almost rude after all that craftsmanship: what if you never had to cut the model at all? What if the real waste was never the math — it was the copies?
LeoTo feel the heresy you need the orthodoxy first, though. Two episodes of "the model is too big, so partition the model." Pipeline splits it by depth. Tensor splits it inside the layer. Both treat the model itself as the thing that has to give.
MayaAnd underneath both sits the technique everybody learns on day one — data parallelism. Every GPU carries the full model, each one chews on different data, and they average their updates. Beloved for one reason: your training loop barely changes.
LeoBeloved right up until the team we've been following tries it. Hundred-billion-parameter model, sixty-four GPUs, and data parallelism's first requirement is that the whole model fits on every single one of them. Dead on arrival.
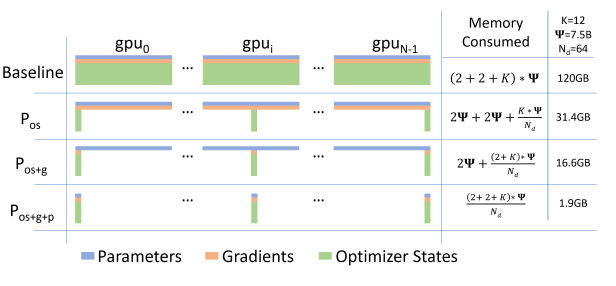
MayaBut before declaring it dead, look at what actually sits in a GPU's memory during training. Three tenants. The weights themselves — the parameters. The corrections — gradients flowing out of backpropagation. And the third tenant, the one nobody budgets for: the bookkeeping.
LeoBookkeeping?
MayaThe optimizer's own state. Take Adam, the optimizer at the center of the paper's analysis — it doesn't just hold parameters. For every single parameter it keeps momentum-like statistics, running records of how that value has been moving.
LeoPer parameter.
MayaPer parameter. And in mixed-precision training there are master copies of the weights and assorted buffers stacked on top of that.
LeoSo tally one parameter honestly: the weight, its gradient, a couple of Adam records, maybe a master copy. The bookkeeping runs several times the size of the thing it's keeping books on.
MayaThe ledger fatter than the collection. Now multiply by billions of parameters. Then — and this is where ZeRO points — multiply again by every worker, because classic data parallelism keeps all of it on all sixty-four GPUs.
LeoSixty-four identical ledgers. The team pays the full memory bill sixty-four times over to store one model's training state. A model that sounds like it should fit, going by parameter count alone, dies on memory because the training state is several times the weights.
MayaAnd when you ask why it was ever built that way, the answer is disarming. [chuckle] Convenience. Full copies make every worker self-contained. Nobody ever waits on anybody.
LeoConvenience, priced in gigabytes, sixty-four times.
MayaHere is ZeRO's move, and the reframing is what I love. It turns memory from a possession problem into a scheduling problem. Stop asking "which worker owns this state." Ask "which worker needs it right now."
LeoAccess, not ownership.
MayaThe state still exists exactly once across the team — sharded, a distinct slice per worker, like a distributed database for training state. The data lives somewhere in the group instead of everywhere at once.
LeoSomewhere, with a delivery promise attached.
MayaWhen a piece is needed, the system gathers it, computes, reduces what came out, and releases. Nothing has to live everywhere. It has to arrive on time.
LeoThe courier schedule, formalized.
MayaAnd ZeRO climbs into it gradually — three rungs on one ladder, each bolder than the last. The bookkeeping rung: shard the optimizer state. Adam's statistics get split across the team, each GPU keeping the records for its own slice of the parameters and updating only that slice. The fattest tenant, evicted first.
LeoThen?
MayaThe corrections rung. Gradients stop being fully replicated too — each worker holds the reduced gradients for the slice it owns, and the rest are passed along rather than hoarded. And then the weights rung, the bold one—
Leo—the one that sounds impossible.
MayaEven the parameters themselves get sharded. No GPU holds the whole model. Ever. Not during the forward pass, not during the backward.
LeoHold on — if no GPU ever holds the whole model, how does a layer even run? The forward pass reaches for weights that aren't there.
MayaIt borrows them. Just before a layer runs, the workers holding its shards broadcast them, the layer computes everywhere, and the borrowed copies are dropped immediately after.
LeoBorrowed and returned.
MayaGather, compute, release — the van pulling up at the exact moment you reach that shelf, then driving off with the books you finished.
LeoAnd every rung down that ladder buys memory and bills coordination. The trade-off line moves each time.
MayaWhich changes the question. Not "do we shard" — but "how much state are we willing to shard, and what communication are we willing to pay for it."
LeoNow the numbers, because this is where the paper earns its title. Shard the state across the team and per-device memory shrinks roughly with the number of workers. Flip that around and it becomes the headline: the model size you can train grows roughly with the size of the team — while the computation still looks like plain data parallelism.
MayaBigger team, bigger model.
LeoAlmost linearly. The paper reports training models over a hundred billion parameters on four hundred GPUs, and its analysis argues the approach can scale beyond one trillion parameters on the hardware of its day.
MayaA trillion. In the title, and meant literally — at a moment when that number would have read as a typo. And the shape of the training loop barely changes.
LeoOkay — barely changes, there's the brochure talking, and I want to argue with it. Because the orthodoxy you're calling waste had reasons. If the model is too big, split the model. Megatron splits the computation directly — and for some architectures that is simply faster. Its communication sits where the algebra demands it, a few predictable points per layer. Meanwhile your courier van is doing an enormous amount of quiet work in this story—
MayaThe van keeps its schedule—
LeoDoes it? Every gather has to land before the layer needs it. Every reduce has to be choreographed. You haven't deleted the cost — you've made the network part of your optimizer.
MayaAnd what does your surgery charge for the privilege? You re-derive the splits for every new architecture. You live inside the chassis, because the chatter only survives on fast local links. You hand a researcher a rewritten training stack and call it progress. ZeRO asks nothing of the model — no surgery, no per-architecture cleverness. The researcher keeps the loop they already have, and the system handles the memory layout underneath. That is why it spread, Leo. Adoption is evidence too.
LeoAdoption — fine, that point lands, and I'll hand you a second one: sixty-four copies of the same ledger is genuinely indefensible. But now concede mine. The whole gain lives or dies on overlap. If those gathers don't hide behind compute, you've traded a memory wall for synchronized waiting — every worker stalled at the same moment, step after step, while the van fights traffic.
MayaConceded — fully. ZeRO saves memory and raises communication complexity; that is the honest ledger of it. The difference between elegant and slow is whether the data movement disappears behind the math. It's a memory paper whose success depends on the network being disciplined enough not to erase the win.
Leo[chuckle] And then the paper itself refused to crown either of us. Look at its own biggest reported runs — they compose. Sharded state carrying the bulk of the memory problem, model parallelism where shapes or speed demand it. The pick isn't ideological. It's model shape, sequence length, hardware topology, and how much engineering time the team actually has.
MayaLast episode's heresy is this episode's orthodoxy, and they stack. Hold both.
LeoSo play the support call. The team flips on sharding expecting headroom, and instead step time gets worse. Where do you look first?
MayaPeak memory, by category — parameters, gradients, optimizer state, activations, temporary buffers, communication buffers. Six tenants, measured separately, because the fix for each one is different.
LeoAnd then?
MayaThen the second look: whether the sharding simply moved the pain into network time.
LeoWhich is the hard question stated plainly: are we saving memory at the cost of synchronized waiting that dominates step time? A run can improve the metric on the slide and quietly damage the one that bills.
MayaBottleneck first, technique second. ZeRO rewards that habit more than most papers, because its three rungs are really three different answers to "how much pain are you in."
LeoAnd weigh what the idea made easier afterward, because that's the bigger ledger. Some techniques train one model faster. This one changed which model sizes ordinary teams could even attempt — experiments that were flatly out of reach became Tuesday.
MayaWhile keeping the familiar loop. A researcher who never wants to think about parallelism gets to keep not thinking about it — that's the quiet gift.
LeoThe paper is on arXiv — ZeRO, memory optimization towards training trillion parameter models — linked in the episode notes, and the memory-budget tables are worth the click on their own. Next time, this idea grows up and ships as Fully Sharded Data Parallel — the engineering sequel to today's argument.
MayaSo take the ledgers with you. Memory redundancy sat in plain sight for years, defended by nothing stronger than convenience, until someone asked why the team was hoarding instead of sharing. Look at your own training loop — your pipeline, your stack, your system — and ask: where else are you paying, over and over, for copies nobody actually needs?
Source material
← Back to Mastering Language Models: From Architecture to Optimization