Transcript
MayaFour painters, one mural, one afternoon. The wall is too wide for any single painter to finish, so nobody takes turns — they all paint at once, each owning a stripe. And whether that goes brilliantly or terribly comes down to one decision: where you draw the cuts.
LeoWhere, not whether.
MayaWhere. Cut along the seams the picture already has — sky meets rooftops, one building ends, the next begins — and each painter works alone for hours, conferring maybe twice all day. Cut straight through a face, and now two painters are leaning across the line on every brushstroke, matching skin tones, negotiating the nose.
LeoSame wall, same painters, wildly different afternoon.
MayaThe cut decides how much they have to talk. Hold that — it's today's entire paper in one sentence.
LeoThe paper being Megatron-LM: training multi-billion parameter language models using model parallelism. Last time, GPipe attacked a model too deep for one chip — slice the layer stack into stages, stream microbatches through, manage the bubble.
MayaAnd today's paper starts exactly where that trick runs out. What if one single layer is already too big? Depth-slicing can't touch that. No schedule rescues a layer that overflows its device.
LeoSo today we go inside the layer.
MayaInside the layer, into the matrix math itself. But before the algebra, fix the picture of what a training job even is. Not a whiteboard equation — a living system. Chips, memory, network links, data loaders, kernels, and a clock that punishes every idle moment.
LeoSo the question is never just "can we compute this." It's whether we can store it, move it, and synchronize it before the GPUs go idle.
MayaThat's the frame. The move is called tensor parallelism — the paper says intra-layer model parallelism, same thing. Plain version first: instead of GPU A owning layer ten and GPU B owning layer eleven, both GPUs cooperate on layer ten.
LeoOn the same multiply?
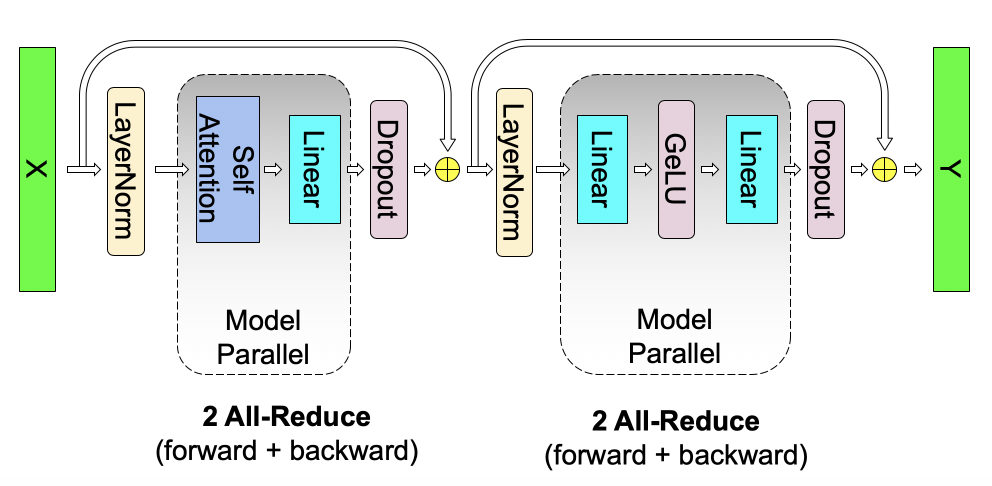
MayaOn the same multiply. A Transformer layer is mostly dense linear algebra — the attention projections, then the feed-forward network. Each one is a big activation matrix times an enormous weight matrix. Megatron cuts the enormous weight matrix across devices. Each GPU computes a slice of the answer, and only at specific, chosen points do the slices get combined.
LeoMake it our team — hundred-billion-parameter model, sixty-four GPUs, meter running.
MayaTake one feed-forward layer of theirs. It expands the hidden representation out to something several times wider, applies a nonlinearity, then projects back down. Those two projection matrices are the mural.
LeoCut them how?
MayaThe first one column-wise. Say eight GPUs each own a vertical stripe of the weights, and each computes its own slice of that wide intermediate. Then the elegant part: the nonlinearity acts on each slice independently — no conferring required.
LeoOkay.
MayaAnd the second matrix gets cut the other way, row-wise, so each GPU's slice flows straight into its own rows. Local work stacking on local work, the whole way down—
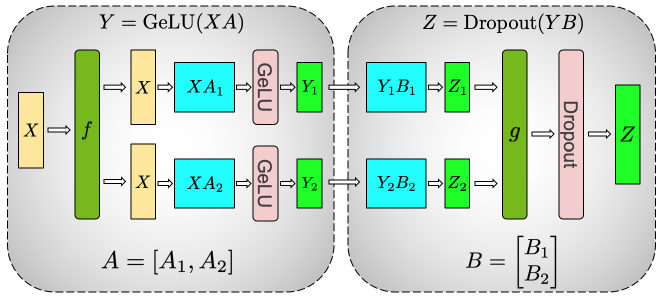
Leo—until it can't.
MayaUntil it can't. At the block's end, every GPU holds a partial answer and the next operation needs the whole one. So everyone shares what they have, everything sums, and everyone walks away with the complete result. The operation is called an all-reduce. {pause=0.7} I call it the huddle.
LeoThe huddle.
MayaEverybody stops, everybody contributes, everybody leaves with the same picture in hand. The painters stepping back to look at the whole wall together.
LeoThen the design rule writes itself. Make huddles rare, make them small. Cut along the algebra's seams and the math runs free for long local stretches. Cut against them and you've split a face — partial results needing reconciliation constantly.
MayaWhich is the paper's key insight stated plainly: Transformer matrix multiplications can be split along rows or columns, and the block's structure tells you which — so the communication lands at a few predictable points instead of everywhere. The algebra chooses the conversation.
LeoCompare the rhythm to GPipe for a second, though. A pipeline stage hands work to its neighbor once per microbatch — occasional, point to point. This is chattier, isn't it?
MayaMuch chattier, by design. Tensor parallelism communicates more often — that's the toll for unlocking a layer too large or too compute-heavy for any single device. Frequent, but predictable and manageable when the cuts are right.
LeoDoes attention split as cleanly as the feed-forward?
MayaMore cleanly — attention is almost a gift. Query, key, and value projections divide naturally across attention heads, and heads are already independent workers, so spreading them across devices barely disturbs the math. Head count, hidden size, batch and sequence shapes decide the best arrangement, but the seams are sitting right there.
LeoEvidence, because this is where Megatron earned the reputation. The paper trains Transformers up to eight-point-three billion parameters on five hundred twelve GPUs, sustains fifteen-point-one petaFLOPs, and holds seventy-six percent scaling efficiency against a strong single-GPU baseline.
Maya[gasp] Seventy-six — at five hundred twelve chips.
LeoAt five hundred twelve chips. And the detail that makes you sit up: it's native PyTorch plus a few communication operations. No new compiler, no bespoke training stack. A handful of carefully placed cuts, in code an ordinary engineer can read.
MayaThat's the historical punch. GPipe wanted your model re-expressed as a clean chain of stages. Megatron wanted a few lines wrapped around your matrix multiplies — and suddenly multi-billion-parameter Transformer training felt implementable by mortals.
LeoCareful — you're sliding into advocacy, and we have unfinished business. Last episode I argued the tensor side against your pipeline. Swap chairs?
MayaGladly, because you undersold my new side last week. No bubble, Leo. Not a smaller bubble — none. Every GPU works on every layer at every moment. No fill ramp, no drain ramp, no slowest stage setting everyone's tempo. A pipeline's idle time is structural — no scheduler deletes it. This design never has any.
LeoThen count the huddles! Every layer, forward and backward, those all-reduces fire — that's not painters conferring twice an afternoon, that's a conference call that never hangs up, the entire run long. On fat links inside one server, fine, you can afford it. Let the tensor group span two servers and that chatter lands on slow cables — your no-bubble miracle becomes a parking lot.
MayaWhich the paper never pretends otherwise! The splits live inside a box with fast wiring, deliberately. And inside that box, show me the pipeline schedule that beats always-busy. You can't — you said so yourself last episode.
LeoInside the box, I can't. That concession stands. But hear the shape of what you just defended: a ceiling with a number on it. Eight GPUs in the server, maybe sixteen, and the technique is spent. Our team's hundred-billion-parameter model doesn't care that one box is busy — it needs all sixty-four chips. Pipeline reaches across servers. Yours stops at the chassis.
MayaThe ceiling is real — reach is yours. But notice what you just did: you composed them. Tensor inside the box, pipeline between boxes. That's not my side losing. That's both sides being right at different distances.
Leo[chuckle] Which is honestly the only sane truce once you see it: splits like these where the wiring is fast, something pipeline-shaped where it isn't, data parallelism over the top.
MayaThe cut is cheap; the conversation isn't. You buy conversation only where the wiring makes it affordable — and the wiring diagram, not the whiteboard, draws that boundary.
LeoMaking Megatron secretly a paper about cluster layout as much as algorithm design. Same code, wrong placement — a tensor group stretched across a slow network boundary — and the numbers collapse.
MayaAnd one trap lives inside the algorithm itself, because "just split the matrix" hides the layout question. Choose the wrong dimension and the clean column-then-row composition disappears. Extra huddles appear, or enormous tensors travel at exactly the moment every device is synchronized and waiting.
LeoSplitting the face.
MayaThe algebra offers seams. Nothing forces you to take them.
LeoField call, then. The team switches on tensor parallelism, throughput disappoints, your phone rings. What do you measure first?
MayaFour dials. All-reduce time — what fraction of each step is huddle. Matmul utilization — whether each slice is still meaty enough to keep its GPU efficient.
LeoTwo more.
MayaTensor shapes — whether the splits genuinely align with the algebra's seams. And overlap — whether communication hides behind compute or stands in front of it as a hard barrier.
LeoNotice "does it sound modern" isn't a dial. A tensor-parallel run can be flawless in the design doc and still spend a third of its life on conference calls.
Maya[chuckle] Painfully true.
LeoSame review habit for any systems paper, really: do the measurements show the right problem being solved? Did the split relieve memory or compute pressure without building a worse communication wall?
MayaPlus the baseline check. If a clever layout beats a weak baseline but loses to a tuned simple setup, the story isn't finished. Distributed training work is strongest when it crosses a hard boundary — fits versus doesn't, stalls versus flows — and keeps its efficiency while crossing.
LeoOne honest limitation before we land it. Slices thin as you widen the split. Eight ways, each GPU still chews on fat, efficient matrix work. Push wider and the slices shrink until devices spend more time coordinating than computing — the quiet second reason the box is the natural border.
MayaAnd still, the legacy outweighs any single number. Megatron's real gift wasn't the eight-point-three-billion-parameter model — it was a pattern cheap enough to adopt. Find your biggest computation, find where the algebra lets you cut, place communication only where partial results truly must meet.
LeoAnd note which kind of valuable that is. Some techniques train one model faster. Others change what experiments a team can afford — model sizes, sequence lengths, recipes that were out of reach. Megatron is the second kind.
MayaThe systems our sixty-four-GPU team would actually run today compose this pattern with pipelines and—
Leo—and with sharded state, which is next time. A paper that watches all this careful slicing and asks something almost rude: what if you never had to cut the model at all?
MayaNo spoilers.
LeoToday's paper is on arXiv — Megatron-LM, training multi-billion parameter language models using model parallelism — linked in the episode notes. Worth opening for the split diagrams alone; they make the column-and-row trick obvious in one glance.
MayaSo take the mural with you. Look at the biggest computation in your own system, the one nothing else fits around, and ask: if you had to split it across four machines tomorrow, where does the math hand you a free cut — and where would the cut force a conversation you can't afford?
Source material
← Back to Mastering Language Models: From Architecture to Optimization