Transcript
MayaFour cooks, one catering order — two hundred sandwiches. Cook one handles bread, cook two fillings, cook three wrapping, cook four boxes them. Now watch the rookie mistake: cook one finishes all two hundred breads before passing anything down the line.
LeoSo three cooks just stand there.
MayaFor the entire first shift. Then cook two works while everyone else waits, and so on down the line. One worker busy at a time, four paychecks running. And the fix is almost insultingly simple — pass the order down in small trays, and within a couple of minutes every cook has work in front of them.
LeoSame four cooks. Same two hundred sandwiches.
MayaNothing about the work changed — only the schedule. Hold that thought, because it's the whole episode in one line.
Leo[chuckle] And that tray trick is the whole paper today, isn't it.
MayaThat tray trick, applied to a neural network too big for one chip, is GPipe.
LeoLast time we walked the bottleneck map for this topic, and the rule we landed on was: find the bottleneck first, then choose the technique. Today is the first deep dive, and it attacks the bluntest bottleneck on that map — the model doesn't fit on a single device at all.
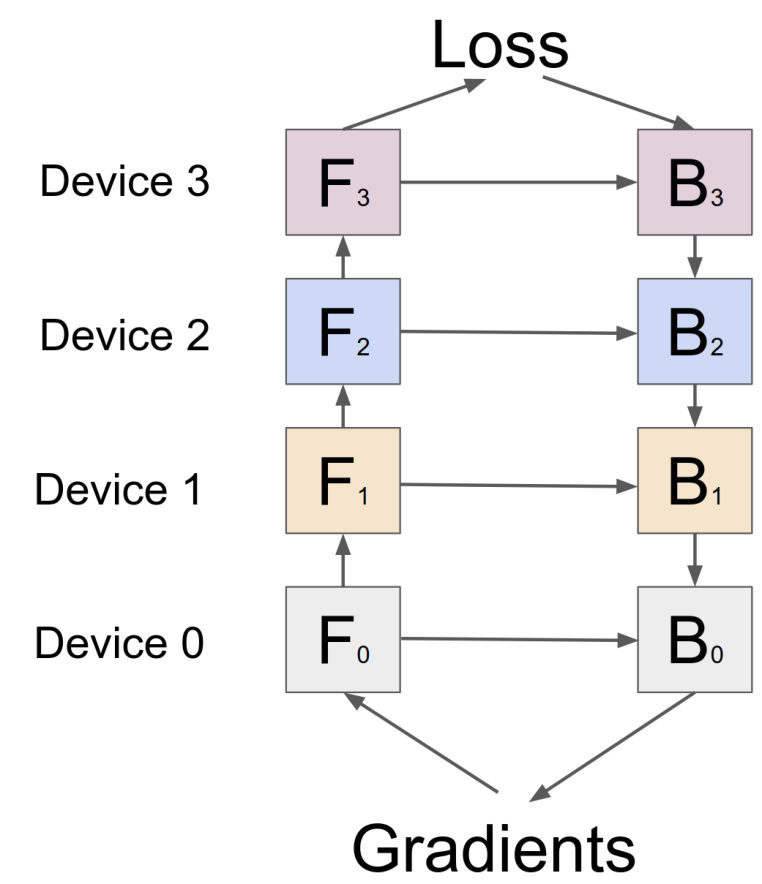
MayaAnd GPipe's answer is almost physical. If the model is too tall for one chip, slice it into floors and give each floor to a different chip.
LeoWhich sounds obvious right up until you remember the floors aren't independent. Layer seventeen can't start until layer sixteen finishes. You've spread the model across eight chips — and built eight chips that take turns.
MayaThat dependency is the villain of this episode. The move is called pipeline parallelism: divide the layer stack into stages, one stage per device, and let work flow through them. The trays — the paper calls them microbatches — are what keep that flow from collapsing back into turn-taking.
LeoGround it in our team from the overview. Hundred-billion-parameter model, sixty-four GPUs, and nothing fits anywhere.
MayaTake their translation stack — say it's a hundred twenty-eight layers deep. GPipe-style, you put layers one through sixteen on the first GPU, seventeen through thirty-two on the next, and so on down the rack. Each GPU owns a floor of the building.
LeoAnd without the trays?
MayaSend one big batch through and you get the rookie kitchen. Stage one computes while seven stages idle. Then stage two. Then stage three. The model fits now — congratulations — and your cluster runs at an eighth of its possible speed.
LeoOuch.
MayaSo GPipe slices that big batch into microbatches and streams them. Microbatch one enters stage one.
LeoOkay.
MayaThen it moves on to stage two while microbatch two enters stage one. A few steps in, every stage is chewing on something.
LeoThat middle stretch is where the pipeline earns its keep. But the edges don't go away. At the start, the late stages have nothing yet. At the end, the early stages have run dry.
MayaFilling the line and draining the line. Those two ramps are the pipeline bubble — genuine idle time that no schedule can fully delete, because the dependency between floors is real.
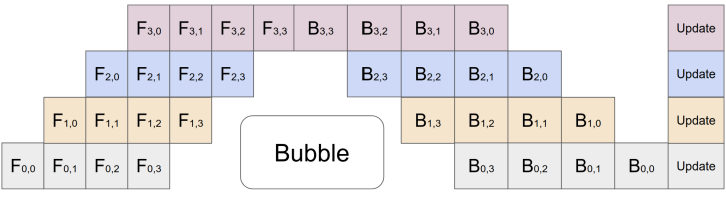
LeoAnd the backward pass makes the choreography harder, right? Gradients flow in the opposite direction, so the schedule is managing traffic both ways without letting anyone stand around.
MayaWhich brings us to the first of two knobs GPipe hands you: how thin you slice. More microbatches means the ramps are small compared to the productive middle—
Leo—but not free. Microbatch count isn't just a scheduling detail. It touches your effective batch size, your memory profile, your optimizer's behavior. Slice too thin and you're not tuning throughput anymore, you're tuning training dynamics.
MayaThe second knob is stranger, and it's my favorite thing in the paper: choosing what to forget.
LeoForget?
MayaDuring the forward pass, every layer produces intermediate values — activations — that the backward pass will need later. Normally you store all of them, and on a very deep stack that storage gets enormous. GPipe can throw most of them away and recompute them on demand when the backward pass arrives.
LeoRecompute, as in run pieces of the forward pass twice. On purpose.
MayaOn purpose. The paper calls it re-materialization. You spend extra compute — which the cluster sometimes has spare — to buy memory, which it almost never does.
LeoAnd when does that trade hurt?
MayaWhen the recomputation overhead lands on a stage that was already your slow one. It's a knob, not a free lunch — you're spending compute you might have needed.
LeoOkay, let me do the evidence, because the evidence is why anyone cared. The paper reports nearly linear speedup as you partition across more accelerators — more chips, proportionally faster.
MayaClean scaling.
LeoAnd it demonstrates scale that was out of reach at the time: a five-hundred-fifty-seven-million-parameter AmoebaNet on the image side, and a six-billion-parameter, hundred-twenty-eight-layer Transformer trained for multilingual translation.
MayaSix billion parameters was giant back then. And the deeper win isn't a percentage — it's a boundary crossing. Before: does not fit. After: fits, trains, and keeps most of the hardware busy while it does.
LeoMm-hm.
MayaWhich is where you start arguing with me, I suspect.
LeoI do, because there's a real fight in the field here and the other camp has a case. The tensor-parallel side looks at GPipe and says: you built a machine whose best case is "mostly busy." The bubble never reaches zero. Stages drift uneven and everyone waits on the slowest one. Why not split the math inside each layer across devices instead — every chip works on every layer, all the time, no bubble at all.
MayaBecause "all the time" hides a price you're not quoting, Leo. Splitting inside the layer means devices trade partial results constantly — layer after layer, the whole run long. That only feels free inside one server with a fast interconnect. Cross to a second server and that chatter lands on slow cables — the no-bubble story dies right there.
LeoAnd your story dies the moment a single layer outgrows a device! Slicing by depth does nothing for that — a floor that doesn't fit is a floor that doesn't fit, however cleverly you schedule the trays.
MayaGranted. Depth-slicing cannot rescue one oversized layer. That hole is real.
LeoAnd I'll hand you generality in return. GPipe asks for almost nothing — if the network can be written as a sequence of layers, it pipelines. No rewriting the math inside attention, no custom surgery per architecture. That's a genuine virtue, and re-materialization compounds it.
MayaSo price what each side actually buys. Pipeline buys reach — it works across servers, across slow links, on anything shaped like a chain — and pays for it in idle time at the edges. Tensor splitting buys fully busy chips and pays in constant conversation that only fast local wiring can afford.
LeoWhich is why the published numbers never actually collide. Near-linear pipeline scaling in GPipe's setting, tensor parallelism nearly unbeatable inside a single box. Different walls, different measurements.
MayaAnd our sixty-four-GPU team doesn't have to pick a religion. Next episode's paper splits inside the layers; this one slices across them; real stacks run both — pipeline between servers, tensor within one.
LeoSettled the way these fights actually settle: by topology, not ideology.
MayaThere's one more trap inside GPipe itself, though, and it's sneakier than the bubble.
LeoSneakier?
MayaSay the team splits those hundred twenty-eight layers evenly — sixteen per GPU. Equal layers is not equal work.
LeoThe sandwich line again. If wrapping takes twice as long as bread, trays pile up behind wrapping, and the whole line moves at wrapping's pace no matter how fast the other stations are.
MayaThe slowest stage sets the tempo for the entire pipeline.
LeoRight.
MayaSo good partitioning balances measured compute time and activation size per stage, not layer count. Some layers are heavy — attention cost grows with sequence length — and a count-based split can quietly build you a bottleneck stage.
LeoWhich sets up the field-engineer question. The team turns on pipeline parallelism, throughput disappoints, and they call you. What do you measure?
MayaFour things. Bubble time — how much of each step is just the ramps. Per-stage compute time — whether one floor is the slow floor. Activation memory — whether re-materialization is pulling its weight. And microbatch count — high enough to keep stages fed, low enough not to destabilize training.
LeoNotice that none of those is "does the method sound modern." A pipeline can look beautifully parallel on a diagram and still spend a third of its life waiting. The diagram doesn't bill by the hour. The cluster does.
MayaAnd one honest limitation to file away: GPipe's whole framing assumes the model is a chain. A clean sequence of layers makes clean floors. Hand it heavy branching, routing, uneven blocks — and the question stops being "where do I cut the stack" and gets genuinely hard.
LeoSo the legacy is a pattern more than a system. Find the resource being wasted — here, expensive chips idled by a dependency — and redesign the training loop around it. Trays for the turn-taking, forgetting for the memory.
MayaA pattern the rest of this topic keeps composing, too. G-Pipe solves the depth problem, tensor parallelism solves the width problem—
Leo—and sharding solves state. Real systems mix all three.
MayaWe just took the depth floor of that building.
LeoThe paper is on arXiv — GPipe, efficient training of giant neural networks using pipeline parallelism — and the link sits in the episode notes with the rest of the references. Worth opening: its schedule diagrams say in one picture what took us ten minutes. [chuckle]
MayaSo here's the question to walk away with. Your model is an assembly line now, and you get to improve exactly one thing first — faster stages, fewer bubbles, or better balance between the stations. Which one do you pick, and why does your workload make it the right choice?
Source material
← Back to Mastering Language Models: From Architecture to Optimization