Transcript
LeoDeep in the evaluation appendix of a twenty twenty-two paper, there's a table where a seventy-billion-parameter model out-scores a model four times its size. Benchmark after benchmark, the small column keeps winning.
MayaSame lab?
LeoSame lab — and here's the detail that turns an upset into an argument: a comparable training bill. The smaller model wasn't the budget option. It spent the same compute. Differently.
MayaAnd listeners, you can already hear it in his voice — this is the paper Leo has been waiting for. [chuckle]
LeoTwo episodes of patience. Today it pays out.
MayaTraining Compute-Optimal Large Language Models — Hoffmann's team, twenty twenty-two, better known by the small model's name: Chinchilla. Link in the show notes, and the tables comparing model sizes against token counts are worth your eyes on their own.
LeoLast episode we walked the original scaling-law curves: loss falls along smooth power laws, bigger models learn more from every token, and the recipe that followed said pour the budget into parameters, feed modestly, stop training early.
MayaToday's paper goes back and re-runs that measurement with more care.
LeoAnd revises the conclusion. The regularity was fine. The recipe over-bought parameters. By this paper's accounting, many of the era's biggest models were trained with too many parameters and too few tokens.
MayaUndertrained giants.
LeoA whole generation of them.
MayaSo pin the phrase before we go further, because "compute-optimal" sounds like jargon and it's actually one precise question.
LeoYou have a fixed amount of training compute — one budget, paid once. Given exactly that number, what model size and what dataset size get you the lowest loss?
MayaNot the largest model the money allows. Not the most impressive headline. The best trade for the budget.
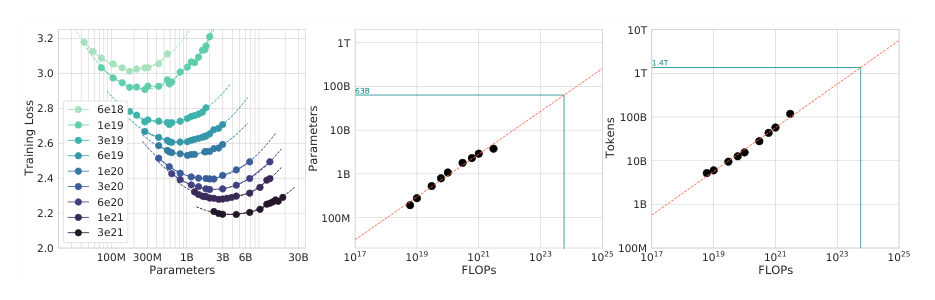
LeoThe method is stubbornly empirical: train hundreds of models across different parameter counts and token counts, measure everything, fit fresh scaling relationships to what actually happens.
MayaHundreds?
LeoHundreds. That's the cost of re-asking a question the field considered settled. And out of that grid comes the rule everything else hangs on — the first landmark of the episode. Call it the rebalance: model size and training tokens should scale roughly together. Double the parameters? Roughly double the tokens.
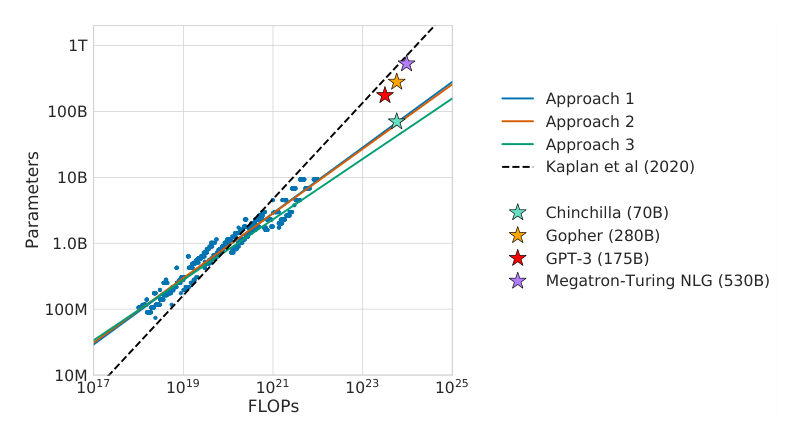
MayaWhich lands very differently from "make it enormous and exit early." Every step up in capacity has to be matched by—
Leo—a step up in education. That's the sentence the era's giants failed.
MayaSame power-law structure as before, notice. What moves is the optimum sitting on it.
LeoRight.
MayaOkay — here's what I want unpacked, though. Last episode the sample-efficiency logic sounded airtight. Bigger models genuinely learn more from each token. How does that survive a paper saying the big models were the mistake?
LeoIt survives untouched, which is the elegant part. Chinchilla doesn't deny sample efficiency. It denies the conclusion the field drew from it.
MayaGo on.
LeoA big model learns more from each token, yes. But each token also costs more to push through a big model. Weigh both sides of that trade across the whole grid, and the balance point moves — toward smaller models reading far more.
MayaSo the mental model is opportunity cost. Every FLOP spent nudging an enormous model through its modest diet is a FLOP that could have carried a smaller model through much more text. And FLOP, for the road: floating point operation, one unit of numerical work. Don't count them. Just hear "training effort."
LeoSpend the effort where it teaches the most.
MayaThen why did the whole field drift the other way? You don't get a generation of undertrained giants by accident.
LeoTwo engines. The cynical one: parameter count was the visible number, the press-release number. Bigger sounded more advanced.
MayaThe honest engine, though, is the uncomfortable one. The earlier scaling guidance really did read as "large models are the efficient place to put compute." Teams weren't ignoring the science. They were following it as written.
LeoWhich is what makes this a revision rather than a scandal. The field did the math available — and then someone did more math.
MayaNow give the demonstration properly. You teased it at the top.
LeoThe rematch — landmark two. Take a training budget comparable to what built a two-hundred-eighty-billion-parameter model like Gopher. Spend it the rebalanced way instead: Chinchilla, seventy billion parameters, fed far more data. Then run the evaluations. The smaller model wins in many of them, against models several times its size.
MayaThe precise claim matters more than the headline here, so say it carefully.
LeoNot "seventy billion beats every bigger model forever." It's: at the same training budget, the smaller, better-trained model beat the larger, undertrained one. That conditional is the whole paper.
MayaAnd then there's the dividend that isn't even in the training math. The seventy-billion model is the one you live with afterward.
LeoEvery query, every day. Serving seventy billion parameters is far cheaper than serving two hundred eighty. The correction improves the model and cuts the operating bill at the same time — corrections almost never do both.
MayaRun it through the one-run team. The old recipe hands them a giant that is, at best, marginally better — and then charges them its size as a tax on every user request, forever. The rebalanced recipe hands them a model that's stronger and cheaper to operate. Same budget.
LeoTraining cost is paid once. Serving cost compounds. For a team that has to answer users every day, that dividend can matter more than the benchmark wins.
MayaHere's the image I'd keep from all this. A parameter count is like the size of a university campus. It tells you something real — it doesn't tell you whether anyone showed up to teach. A giant campus with empty classrooms isn't a great education. It's expensive decoration.
Leo[chuckle] Expensive decoration. That one's going on a sticker.
MayaIn production the decoration actively hurts, too — slower responses, heavier hardware, bigger bills, and no promise of better answers.
LeoSo that's the case, and you can hear where I stand. The correction won. Balanced beats big. Parameter-count bragging deserved to die.
MayaHold on — not that cleanly. Let me argue the other camp properly, because it isn't the strawman you're enjoying. Frontier labs kept training models larger than compute-optimal after this paper. Not out of vanity. A larger model may be the better platform for everything that comes after pretraining — fine-tuning, tool use, multimodal capacity, abilities that only show up with scale. Compute-optimal is measured on one number: training loss. Their bet is on what that number doesn't see.
LeoThen the bet should pay evidence — because "we over-sized it for capabilities the loss can't measure" is unfalsifiable exactly where it's convenient. The eval table, I can check. The invisible futures, I can't.
MayaSome of it you can check! Product tiers are real. A lab serving different markets may want a flagship past the optimum because quality is the product and latency be damned — and the inverse is just as real: sometimes you go smaller than optimal because serving cost rules everything. Both are rational. Neither is compute-optimal. The paper answers a training question; companies are answering a business question.
LeoHm. Fine — here's the line I'll actually defend. Chinchilla answers its own question, and answers it well: lowest loss for a fixed training budget. Settled, re-measured, demonstrated. What it cannot do is choose your question for you. Compute-optimal is not business-optimal, product-optimal, or safety-optimal by default.
MayaI'll hand back what your side earned, too. The eval table survives every objection I just made. Whatever reasons a lab has for going bigger, "undertrained by accident" stopped being one of them. After this paper, oversizing has to be a decision — not a default.
LeoDecision, not default. I'll take that as our resolution.
MayaThen let's read the fine print — the last landmark — because the rule carries caveats that cut deeper than strategy. The recipe is stated in token counts. And tokens are not interchangeable.
LeoTen excellent books are not ten thousand spam pages. If the extra tokens the rebalance demands are low quality, the clean arithmetic bends. More text is not automatically more education.
MayaWhich is why modern pretraining recipes obsess over everything the curves compress into a single variable — filtering, deduplication, code data, multilingual balance, synthetic data. The data team stops being housekeeping. It becomes part of model capability.
LeoWith a sharp edge attached: train for many more tokens, and any systematic flaw repeats at scale. A biased source mix, a duplicated corpus, benchmark examples leaking into the training set — the longer education amplifies whatever's printed in the textbook.
MayaSo the balanced recipe is not "just add tokens." It's "add enough useful tokens to match the capacity."
LeoSecond piece of fine print: these laws optimize a loss objective. If your job is code, math, medicine, customer support — lowest loss certifies none of it. You still run task evaluations. We fought over that exact point last episode, and Chinchilla doesn't resolve it. It inherits it.
MayaThen the third piece follows from the rule itself, and it's the cliffhanger. If every doubling of parameters demands a doubling of tokens, data demand grows fast. Chinchilla points straight at a data bottleneck — where do all those high-quality tokens come from?
LeoThat question gets the entire next episode: what happens when the balanced recipe asks for more fresh text than anyone has.
MayaBefore we go there, make it practical, because the one-run team has a decision in front of them. Say they're building a legal assistant. Old instinct: the biggest model the budget allows, trained on whatever corpus they've got.
LeoNew instinct: ask the unglamorous question first — would that model be undertrained? Check the ratio before admiring the size. And the paper hands them a method, not just a slogan: train small models at several token counts, fit the curves on your own data, estimate your own frontier. Budget experiments aren't overhead. They're how you avoid spending the only run on a mistake.
MayaDon't assume the bigger parameter count wins. Measure whether it would.
LeoAnd the lesson traveled fast. Look at what changed in open model releases afterward: token counts started appearing next to parameter counts, prominently. Teams trained smaller models for longer and got strong results inside realistic budgets.
MayaThere's a democratizing streak in that. Not everyone can afford the biggest model. Nearly everyone can think hard about the ratio of data to parameters.
LeoIt rewired how to read announcements, too. A meaningful model card tells you parameters, tokens, data mixture, training compute, and the evaluation suite. One number alone tells you almost nothing.
MayaEven leaderboards read differently now. A huge model scoring well is impressive. A small model scoring nearly as well is often worth more to the people who have to ship something.
LeoBragging rights moved. The question stopped being "how big is it?" and became "how well was the budget spent?"
MayaSo set the arc of the topic. Transformers made scale practical. The scaling laws made progress predictable. Chinchilla made the allocation honest — capacity and education, scaled together, priced together.
LeoAnd next time, the honest recipe walks into an empty library.
MayaHere's the question to carry out. The next model announcement that crosses your feed will lead with its parameter count. What would you ask to find out whether that capacity was ever actually filled?
Source material
← Back to Mastering Language Models: From Architecture to Optimization