Transcript
MayaPicture the one-run team the night before they lock their only pretraining run. Model size chosen. Token budget balanced exactly the way last episode taught them. And then the data engineer posts one number in the team channel: the cleaned, deduplicated crawl is smaller than the recipe's token demand. Not slightly smaller. Half.
LeoOof.
MayaThe channel goes quiet. And then someone types the question nobody wanted to ask first — what if we just run the same data through twice?
LeoWhich sounds like cheating. We've spent two episodes saying feed the model more fresh text, and the proposal on the table is rereading the whole pile.
MayaThat rereading question is today's paper. Scaling Data-Constrained Language Models — Muennighoff's team, twenty twenty-three. Link in the show notes; the experimental grid alone is worth a scroll.
LeoAnd it picks up exactly where I left off. Last time, Chinchilla re-measured the budget split and said scale tokens with parameters — and I closed on a promise: the honest recipe walks into an empty library. Well. This is the empty-library paper.
MayaSo set the constraint properly before anyone reaches for workarounds, because "the internet is huge" is the objection everyone makes first.
LeoHuge isn't the same as usable. A big slice of the crawl is duplicated. Another slice is low quality.
MayaBefore the lawyers, even.
LeoThen the lawyers. Subtract private data, copyrighted data, toxic text, misleading text. And anything sitting too close to the evaluation benchmarks, because training on the test isn't capability, it's a leak.
MayaSo what you can responsibly train on is a much shorter shelf than the internet. Call it the usable shelf. And here's the squeeze: the balanced recipe's demand grows with every model generation. The shelf doesn't.
LeoRight.
MayaWhich makes the paper's question very concrete. If the unique text is fixed, can the model benefit from seeing it more than once?
LeoOne vocabulary beat before the result. An epoch is one full pass through the dataset. One epoch — the model has read everything once. Four epochs — it's been through the same shelf four times.
MayaWhich brings us to the second pass. And I'll admit what I expected here: a wagging finger. "Don't repeat your data" was practically folklore — deduplication is a best practice for a reason.
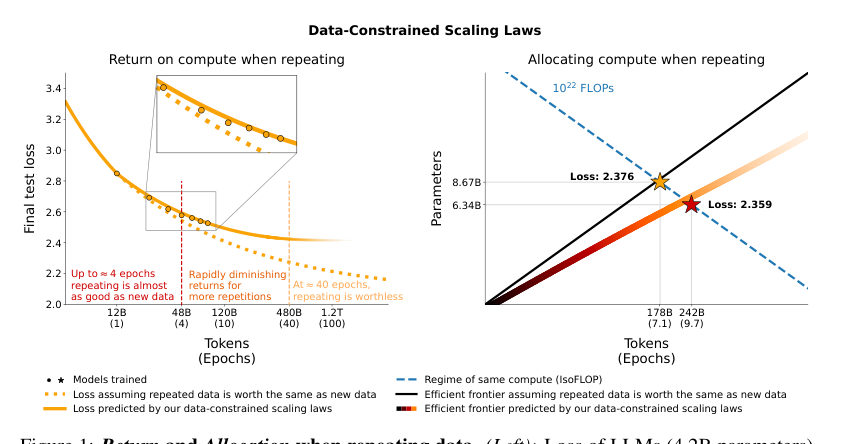
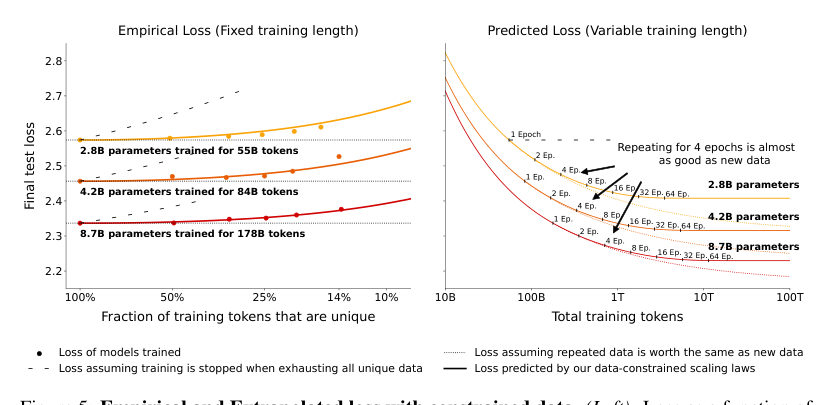
LeoAnd the data says the folklore was too pessimistic — that's the headline. The authors run a huge sweep across model sizes, compute budgets, and repetition levels, and repeating the dataset for a small number of epochs turns out to be surprisingly okay. The model keeps improving. Not identical to fresh text — but close.
MayaGenuinely close?
LeoClose enough to plan around for those first few passes. But here's what makes it science instead of permission: past that, the value of each repeated token decays. Keep cycling the same shelf, and every lap teaches less than the one before.
MayaSo here's the mental model I'd hang the whole episode on: tokens have marginal value. The first time the model meets a useful example, it learns a lot. The second time, it consolidates. The tenth time, less. The thousandth — almost nothing new. What this paper does is turn that intuition into a fitted curve.
LeoCall it the repetition discount. Repeated tokens still spend — just at a worse and worse exchange rate.
MayaIt's a musician's relationship with one étude. The first runs through build the skill. The twentieth polishes it. The five-hundredth isn't practice anymore — your fingers are just grooving in whatever habits are already there.
LeoIncluding the bad habits. Which is the overfitting risk, plain version: the model gets very good at the training examples themselves and worse at new ones. Heavy repetition raises exactly that risk.
MayaAnd the fitted law carries a second discount that I find more interesting than the first. It discounts excess parameters too. When data is the bottleneck, capacity beyond what the data can fill stops paying. The model has room to learn—
Leo—and no new experience to fill the room. Which quietly revises the planning advice one more time: under data constraint, the compute-optimal model is smaller than the one you'd build with unlimited fresh text.
MayaSo the whole topic arc, in three moves. Scaling is predictable. Balance parameters with tokens. And when unique tokens are capped — shrink, and reread.
LeoRun the one-run team through it, because this is where it stops being abstract. Say their assistant has to work in a low-resource language — call it forty billion good tokens in existence, total. A strict balanced recipe wants more than exists.
MayaSo now what?
LeoFive doors. Repeat the data. Pull in related languages. Translate. Generate synthetic examples. Or train a smaller model than they'd planned.
MayaAnd the honest answer probably mixes all of those. What the paper changes is that the first option stops being a guess. Repetition now comes with a measured decay curve — you can reason about it instead of treating reread data as automatically useless.
LeoPractice versus novelty is how I'd file it. A repeated token buys practice. Fresh text buys novelty. Both have value, the values are different, and a data-constrained scaling law is the attempt to price the difference.
MayaMake the pricing concrete. One million unique examples repeated four times is four million examples in a counting sense — but nowhere near four million independent lessons.
LeoMm-hm.
MayaAnd this is exactly the regime specialized domains live in. Medicine, law, chemistry, low-resource languages — the most relevant corpus is often a sliver of general web text, and you can't buy your way out with more crawling.
LeoNow the part where we stop agreeing.
Maya[chuckle] You've been waiting through the whole consolidation section.
LeoBecause the paper doesn't stop at repetition — it tests workarounds for filling the shelf. Two of them get measured directly: add code data to the mixture, even for a mostly-text model. And relax the quality filters everyone applies by default — because filtered-out text is still tokens.
MayaAnd the wider field has a longer menu: smarter data selection, domain mixing, synthetic data, retrieval, curriculum learning — or simply accepting a smaller model. Parts of that menu I trust a lot less than you do.
LeoThen let's argue it, starting where the evidence is. Relaxing filters is measured in this paper — it's not a vibe. And the case is real: aggressive filtering throws away useful diversity. Code, informal text, multilingual text, rare domains — the filter that protects average quality also starves exactly the long tail you'll wish the model had seen.
MayaAnd the caution side is just as real: noisy tokens aren't free. Lower-quality data can teach bad behavior, waste compute, and open safety holes. More tokens can make the model worse if they're noisy enough. "It's technically text" is not a curriculum.
LeoGranted — for the bottom of the barrel. But the measured middle, the stuff default filters reject that's merely informal rather than harmful? That's where this paper says there was value sitting on the floor.
MayaFine. Filter relaxation, measured and bounded — I'll concede that one. Synthetic data is where I plant the flag. The optimists say it's essential: strong models can write explanations, problem variants, clean examples, and high-quality human text is precisely what's running out. But model-generated text can collapse diversity and amplify the generator's own mistakes. Train models too heavily on the output of models, and the corpus starts inheriting their quirks instead of the world's.
LeoThe skeptics' own fix is sitting right there, though — filtered, verified, grounded in real tasks. Synthetic data with a verifier behind it isn't a photocopy of a photocopy. It's closer to generated exercises with an answer key.
Maya"With a verifier" — that's the load-bearing clause, and notice what it concedes: raw synthetic volume is not the answer. Verified synthetic data is a different, more expensive thing.
LeoSo we've negotiated our way to the unglamorous resolution. Repetition is a priced tool with a known discount. Filter relaxation is measured and bounded. Synthetic data is promising exactly in proportion to how hard you verify it. Nobody gets a free shelf.
MayaSigned. Now let me widen it, because a third disagreement hides under the other two — whether the scarcity is even universal.
LeoGo on.
MayaFor English web text, the frontier feels constrained. But "data" was never only static internet text. Multimodal data, interaction data, domain-specific logs, tool-use traces—
Leo—environments, simulations, user feedback, code execution, retrieval. Experience you collect or create by acting, not just crawl.
MayaSo the empty library might be one wing of a building with unopened doors. That camp says the bottleneck is a failure of imagination about what counts as data.
LeoSecond pass through the one-run team, different corner of the problem. Their most valuable corpus might be company-internal support tickets — tiny, but a perfect match for the product domain.
MayaTempting.
LeoVery. Moderate repetition helps the model learn the domain. Too much, and it starts memorizing the quirks. And the quirks include customer details.
MayaWhich is where this stops being purely technical. Repeating sensitive data raises the odds the model reproduces it. So data-constrained training collides with privacy, copyright, and evaluation contamination all at once. The real question was never "how many tokens exist?" It's "which tokens can we responsibly use?"
LeoA governance constraint stacked on top of a supply constraint.
MayaAnd there's a systems answer sitting right next to the training answer. If a fact is rare, rewiring model weights to memorize it may be the expensive way to know it. Retrieve it at inference time instead — let the surrounding system fetch reliable context when it's needed.
LeoData limits push you from "make the model know everything" toward "make the system know how to find what matters."
MayaWhich blurs a boundary this series will keep crossing — model training versus system design. And the constraint follows us downstream, too. Fine-tuning runs on small datasets by definition. Preference labels for reinforcement learning from human feedback — R-L-H-F, when we get there — are expensive precisely because high-quality human judgment is scarce.
LeoSo data-constrained isn't some exotic corner case. Downstream of pretraining, it's the default condition.
MayaOne uncomfortable consequence before we close the arc. Every workaround we just argued over — repeating, relaxing, generating — makes evaluation more important, not less.
LeoBecause each one has a failure mode users will eventually meet: memorization, degradation, brittle behavior. If you squeezed more from less, you owe proof that the squeeze didn't distort the model — and some distortions surface months later, not in week one.
MayaSo close the topic where it started. The earlier scaling-laws work made scaling predictable. Chinchilla made the budget split honest. And this paper makes the limits honest: scaling was never just model size and compute. It's data economics — availability, quality, legality, diversity, and how many times the model has already seen something close.
LeoThe shelf is finite. The discount is measurable. The workarounds are real, priced, and none of them free.
MayaThen here's the question to walk away with. When high-quality human text genuinely runs short, where would you place your bet for how models keep learning — repeating what we have, generating new text, retrieving instead of memorizing, or interacting with the world?
Source material
← Back to Mastering Language Models: From Architecture to Optimization