Transcript
MayaPicture a sheet of log-scale graph paper. An engineer has trained a handful of small models — cheap runs, a weekend each — and plotted their final losses as dots. Then she does something that should feel reckless. She lays a ruler along those dots and reads off the loss of a model hundreds of times bigger. A run she hasn't started. A run her team can only afford once.
LeoAnd the ruler's right?
MayaThat's the astonishing part. In the ranges this paper measured, it kept being right.
LeoWhich would make it the least messy result in machine learning. Because normally? You change the model, change the data, change the training setup, and the numbers jump all over the place.
MayaAnd this paper says: underneath the mess, there's a line.
LeoOne line?
MayaThree, really — one for each resource, and we'll get there. We're inside Scaling Laws for Neural Language Models today — the Kaplan paper, from twenty twenty. Last episode we set up the whole topic: scaling as resource allocation, one fixed budget split across parameters and tokens.
LeoAnd today is where the word "predictable" in that story comes from. This paper is the measurement — the actual curves. Link's in the show notes, and the figures are worth your eyes; the plots carry the argument.
MayaSo start with what's being measured, because everything hangs on it. Cross-entropy loss. Strip the jargon and it's a surprise meter. Show the model real text, and the loss says how surprised it was by each next word. Lower loss, less surprise, better prediction.
LeoWhich is not the same thing as usefulness. Hold that complaint — I'll be back for it.
Maya[chuckle] Noted and filed. The paper takes that one number and asks how it moves when you turn three things: the number of parameters, the amount of training text, and the total compute spent on the run.
LeoAnd the answer, in every direction they looked, is a power law.
MayaWhich sounds technical, so here's the plain version. A power law means each multiplication of scale buys you a predictable slice of improvement. Ten times the model, a certain drop in loss. Ten times again — another drop, same recipe. The slices get thinner as you go, but they arrive on schedule.
LeoAnd the point isn't that the gains are big. They shrink. The point is they shrink *smoothly*. No wall, no cliff, no sudden jump anywhere in the measured range. Plot loss against compute on a log scale and you get something embarrassingly close to a straight line.
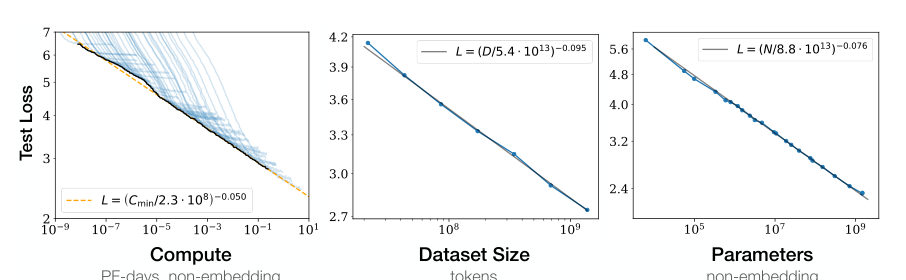
MayaThat regularity is the first landmark of this episode. Call it the ruler. If loss falls along a straight line on log paper, then small, cheap experiments become forecasts. You fit the line in the region where training is affordable, and you extend it into the region where it isn't.
LeoThat's the wind-tunnel move. Aerospace teams don't build five airplanes to find a good one — they test scale models in a wind tunnel and trust the extrapolation. These curves were the field's wind tunnel.
MayaAnd think about what our one-run team from last episode does with that. They cannot rehearse their single pretraining run. But they *can* afford a ladder of pilot runs — small models at different sizes, different token counts. Measure the validation losses, fit the line, and pick the full-scale recipe that lands nearest the frontier.
LeoThat pilot-first habit is a direct cultural descendant of this paper. It turned giant training from a leap of faith into a forecasting problem.
MayaThere's a second result hiding in those curves, and it set the field's direction for the next two years.
LeoGo on.
MayaThe paper found that architectural details — depth versus width, the exact shape of the network — mattered far less than overall scale, within the range of reasonable designs.
LeoMattered less — or stopped mattering?
MayaI'll defend the strong reading: architecture is over. Within the studied range you can trade depth against width and the loss barely moves. Total scale explains the outcome; the design details are noise on top of the budget.
LeoNo — look at what those curves were measured on. Working Transformer setups, every single one. Models that already train stably. Not arbitrary networks —
Maya— which is most of what anyone actually runs.
LeoIt's everything the plot lets you see! An architecture that can't train won't be rescued by scale. "Architecture is over" only sounds true because the broken designs never made it onto the graph.
MayaThat one I'll give you. The result is conditional — it's "given a setup that works," not "given anything with parameters."
LeoAnd I'll hand one back: inside that family, the flatness is real. Depth-versus-width choices moved loss far less than scale did. The budget explains most of the outcome.
MayaSo the sentence we can both sign: among competent Transformer setups, the scaling budget is the dominant variable. Not "design is dead" — "design isn't where the leverage is."
LeoSigned.
MayaThen comes the result that actually tells you how to spend money. Larger models are more sample-efficient. A bigger model learns more from each token it sees.
LeoEvery individual token teaches the big model more than it teaches the small one. Which has a strange consequence —
Maya— that the budget should chase size. Exactly the logic. Follow sample efficiency to its conclusion and you get the paper's allocation recipe: for a fixed compute budget, train a very large model on a relatively modest amount of data, and stop before convergence.
LeoStop before convergence. That's our second landmark — the early exit. And I want to sit on it for a minute, because on first hearing it sounds like malpractice. Everything you're taught in ordinary machine learning says train until the model stops improving.
MayaThe reframe is economic, not statistical. Near convergence, each additional training step buys almost nothing.
LeoSure. Thin slices.
MayaSo the question stops being "can this model improve a little more?" and becomes "is this the best place to spend the next unit of compute?" By the paper's curves, the answer near convergence is no. That compute would have bought more loss reduction as extra parameters instead.
LeoSo you deliberately walk away from a run that's still improving, because the same money buys more model. That was the recipe: err huge, feed it modestly, leave the last drops of convergence on the table.
MayaAnd to be fair to the paper, that recipe wasn't ideology — it's what the fitted slopes implied. The exponents said size pays better than data.
LeoFor the one-run team that's not abstract advice. It says: of your one budget, put most of it into parameters. Train the biggest model the number allows, and accept that by classic standards it will be undertrained.
MayaOkay. {pause=0.7} You said you'd come back for the surprise-meter complaint.
LeoI did, and here's where I stop nodding along. Everything we just admired is a statement about loss. Loss is an average over next-word prediction.
MayaAs advertised.
LeoYou can make that average fall and still ship a model that fabricates citations, mangles multi-step reasoning, and fails the rare cases your users actually hit. A smooth curve can be a smooth road to the wrong destination.
MayaThen explain the track record. Teams that understood these curves allocated real budgets with real confidence — and the forecasts held. Predictable scaling guided actual progress. That's not a story the optimists tell; it's what happened. You don't get to call the most reliable planning instrument this field ever found "false comfort."
LeoIt's not the instrument I distrust, it's the worship. These curves are fitted inside a measured range. Within that range — interpolation — fine, I'll trust them all day. Beyond it, extrapolation is a bet. And the frontier run is always beyond it, because the final run is precisely the experiment nobody could afford to rehearse.
MayaBut that bet came in! Over and over, across orders of magnitude — the trends held far past where skeptics said they'd bend.
LeoUntil the part where the *recipe* didn't. And we'll spend the entire next episode there — Chinchilla went back, re-measured the trade-off, and argued the mix was wrong: those huge models should have seen far more tokens per parameter.
MayaCareful — that revises the allocation, not the regularity. The power-law structure survives Chinchilla; what moves is where the optimum sits on it.
LeoGranted.
MayaHmm. Actually, let me concede the real point before I defend the rest: the proxy complaint lands. Loss is a surprise meter, not a usefulness meter. A team that cares about code has to test code. Factuality, safety, tool use — none of that arrives free with a lower average.
LeoAnd I'll concede the forecasting record. The curves earned the budgets they unlocked — pilot runs predicting frontier losses, and getting them right, is a kind of rigor this field simply didn't have before.
MayaSo the honest synthesis: the ruler is excellent for one question — where a fixed budget should go — and silent on another — whether the model that comes out is good at your job. Two instruments. You fly with both.
LeoWhich would have settled our argument before it started. [chuckle] Where's the fun in that.
MayaThe synthesis still has edges, though, and they're worth naming — the third landmark, the edge of the map.
LeoSuch as?
MayaThe curves treat dataset size as one clean variable. Later work keeps pressing on what that hides: what *kind* of data? How duplicated? How filtered? How balanced across domains?
LeoAnd whose distribution. Say the one-run team fits its pilot curves on clean web text, but the product is legal reasoning. The line can keep predicting language loss beautifully while telling you nothing about legal usefulness.
MayaThere's a quieter caution underneath that. Average loss can improve while the tails don't move. The model gets better at common patterns and stays brittle on rare tasks — which is exactly why downstream evaluations became standard practice alongside the curves rather than instead of them.
LeoOne more edge, a practical one. The budget on paper is not the budget delivered. If your cluster sits idle waiting on communication between machines, theoretical compute never becomes actual training. The curves assume you can deliver the compute — making that true is Topic 3's entire problem.
Maya[sigh] Right — the laws say how compute should be allocated, and say nothing about whether you can physically spend it.
LeoNeatly put.
MayaNow step back from any single recipe, because I think the paper's deepest contribution isn't the recipe at all.
LeoWhat is it, then?
MayaThat it made large-scale training feel less like alchemy. There were regularities. You could fit them, plan with them, budget around them.
LeoAnd capital followed the regularity. If improvement can be bought predictably, you can justify the bigger cluster, the larger data effort, the multi-generation roadmap. Scaling stopped being an art project and became capital planning.
MayaThere's a responsibility angle to that same predictability. If you can forecast a more capable model before it exists, you can prepare for it — infrastructure, safety evaluations, deployment plans — instead of being surprised by your own results.
LeoThat's the grown-up version of curve confidence. Not "we can predict improvement" — "we can prepare for its consequences."
MayaSo that's the Kaplan paper in three landmarks. The ruler: loss falls along smooth power laws in model size, data, and compute, so small runs forecast big ones.
LeoThe early exit: sample efficiency says spend the budget on size and stop short of convergence.
MayaAnd the edge of the map: it's all loss, all measured range, all averages.
LeoAnd the early exit is precisely the claim Chinchilla walks in to re-measure next time. Bring the skepticism you just heard me practice.
MayaSo here's the question to sit with. Your one run, your whole budget, and a beautifully straight line telling you exactly where to spend it — what's the one test you would still demand before you trust the line?
Source material
← Back to Mastering Language Models: From Architecture to Optimization