Transcript
MayaLast time we toured the whole territory — why reading one word at a time lost to letting every word look everywhere at once, and why the field still argues about the price of that look.
LeoToday we stop touring and read the source. "Attention Is All You Need" — Vaswani and colleagues, 2017. Not the legend of the paper. The actual paper: what it built, what it measured, and what it never claimed.
MayaStart with a sentence. "The agreement terminates if the buyer breaches it." Quick — what does "it" point to?
LeoThe agreement. Half a second.
MayaAnd notice what you didn't do. You didn't re-read from the start. The word "it" reached backward, weighed its options, and grabbed "agreement" — directly. The paper's bet is that this grab is not a garnish on language understanding. It's the meal.
LeoHence the title. Not "attention helps." All you need — subtract everything else and the model gets better.
MayaQuick scene-setting first. In 2017, the best translation systems were recurrent. They read step by step, and attention existed only as a helper bolted onto the side. The quality was decent. The clock was the real enemy.
LeoBecause step-by-step reading means step-by-step training. You cannot compute step fifty before step forty-nine exists.
MayaWhich leaves a GPU — a machine built to do thousands of multiplications at once — standing in line, doing one thing at a time. Training runs stretched into weeks, and the labs paying for those weeks were getting impatient.
LeoSo the paper's real pitch, the one under the architecture diagram, is a wall-clock pitch. Throw out recurrence. Keep only the lookup. And suddenly the whole sentence trains in one parallel sweep.
MayaFor the contracts firm we've been riding with, that's the difference between training their review assistant on the document archive over a weekend — or over a quarter.
LeoMm. Big difference.
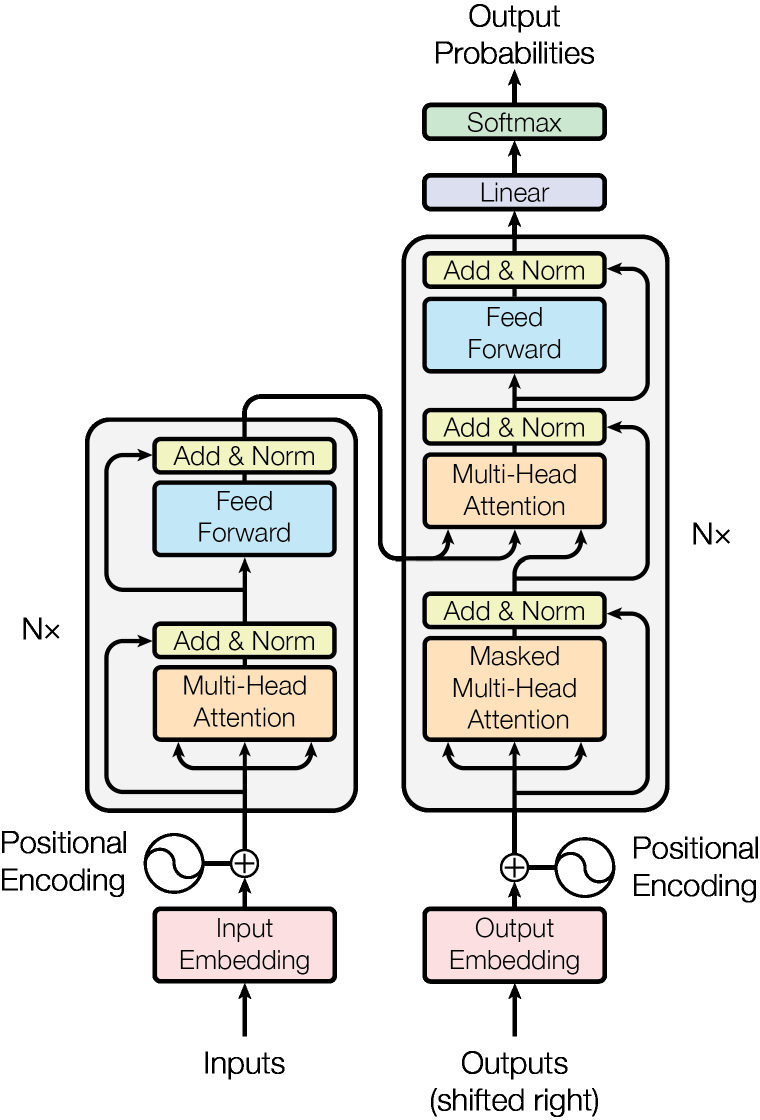
MayaSo let's open the machine, because the mechanism is more concrete than its reputation. The tour has three stations — the Matchmaker, the Committee, and the Chord.
LeoGo.
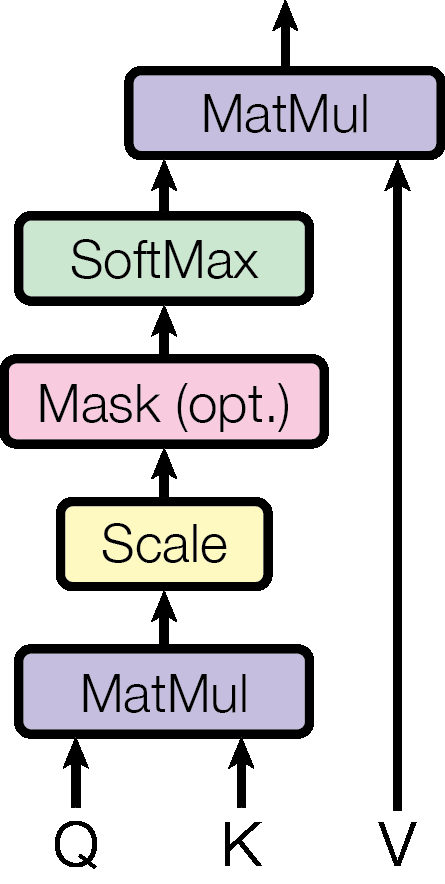
MayaThe Matchmaker is the attention lookup itself. Every word gets turned into three— okay, here's the cleaner way in. Picture every word filling out two cards. One card spells out what I'm looking for. The other lists what I have to offer.
LeoA dating profile per word.
Maya[chuckle] Essentially. The looking-for card is called a query. The offering card is called a key. The matchmaker compares every query against every key and scores compatibility — high score, strong match. And a matched word hands over a third thing, its value: the actual information it contributes.
LeoSo "it," in our contract sentence, files a query — seeking: a thing that can be breached — and "agreement," seventy words back, holds a key that screams compatibility.
MayaAnd the value of "agreement" flows into "it." Not as a hard pointer — as a weighted blend. Mostly "agreement," a trace of everything else. Every word runs this lookup against every other word, simultaneously, in one sweep.
LeoWhich is the part I want flagged for later: every word against every word. That sweep is where the famous cost lives.
MayaFlagged — and the paper flags it too, which we'll get to. Station two: the Committee. One matchmaker can only ask one kind of question per lookup. So the paper runs eight of them side by side, each with its own learned sense of what compatible means.
LeoEight full copies? That sounds expensive.
MayaEach member works in a slimmer slice of the representation, so the committee together costs about what one full-width matchmaker would. Eight narrow specialists for the price of one generalist.
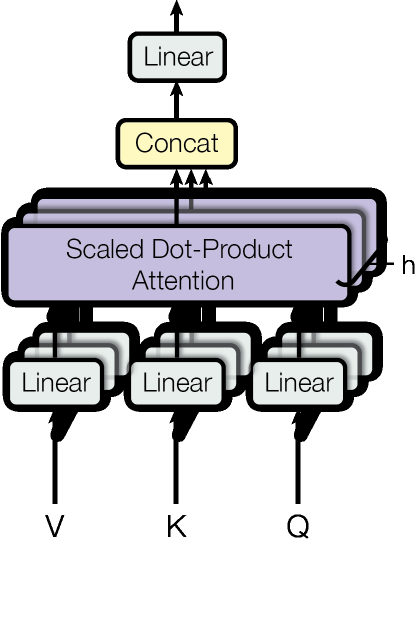
LeoOkay, specialists in what, though?
MayaDifferent relationships entirely. In trained models you can watch one head track who-did-what-to-whom, another resolve pronouns, another just watch the neighboring word—
Leo—and that's not poetic license. The paper's appendix shows it: a head where "its" reaches back to exactly the noun it stands for. They drew the threads.
MayaThe committee's findings get stitched together, passed through a small per-word processing step, and that whole package is one layer.
LeoOne floor.
MayaStack six, with shortcut connections so nothing learned gets lost between floors, and each pass refines the blend — like successive drafts of a translation getting sharper.
LeoStation three. Because something is missing, and it bugged me the first time I read this. If everyone looks at everyone simultaneously, who remembers word order? "Dog bites man" and "man bites dog" contain identical words.
MayaThe Chord — my favorite patch in the paper. Before any lookup happens, every position in the sequence gets stamped with a unique pattern built from overlapping slow and fast waves. Think of each position as a chord. The same notes are available everywhere, but position three plays one combination and position eighty plays another.
LeoHuh. So they didn't learn the position signal — they composed it?
MayaThey tried both, actually. Learned position vectors scored essentially the same. They kept the waves hoping the pattern would stretch to sequences longer than anything seen in training. Honest engineering: run the test, report the tie, pick the option with better odds.
LeoOne more piece for completeness, because people forget the machine has two towers. One tower reads the source sentence. The other writes the translation, word by word — and while writing, it wears a blindfold to the future. Each new word may consult everything already written and the entire source, but nothing ahead of itself.
MayaWithout that blindfold there's no generation at all — the model would be copying answers off its own answer sheet.
LeoRight.
MayaAnd that's the whole machine. No recurrence anywhere in it. Lookups, a committee, a chord, a blindfold — stacked six high.
LeoNow the receipts, because this is where the 2017 version of me sat up. The benchmark was the W-M-T English-to-German translation bake-off, scored with a measure called BLEU — spelled B-L-E-U, said like the color. The big Transformer beat every published system, including ensembles of multiple models voting together, by more than two points. In translation terms, two points is not a nudge. It's a shove.
MayaMm-hm.
LeoBut here's the line that changed budgets. The base model trained in about twelve hours on eight GPUs. The big one in three and a half days. The systems it beat had trained for weeks.
MayaTwelve hours. [gasp] In an era when a training run was a calendar entry, not an overnight job.
LeoAnd the result traveled.
MayaTraveled where?
LeoThey pointed nearly the same architecture at English grammar parsing — building sentence-structure trees, a genuinely different task — and landed near the top with barely any tuning.
MayaThat's the sentence I'd underline in the whole paper. The translation score says good system. The parsing result whispers general machine.
LeoThe ablation table is quietly the best part, by the way. They removed pieces one at a time and watched the score. Shrink the committee to a single big head — almost a full point worse. Crank it to too many heads — also worse. Eight sat in the sweet spot. The committee isn't decoration; the table shows it earns its seat.
MayaI notice you went straight for the table.
LeoTables don't have a marketing department.
Maya[laugh] Fair. All right — strengths are on the record. Now poke it.
LeoHere's what the paper did not show, and the keynote version always skips this. It showed a better translator and a strong parser. It did not show chatbots.
MayaGo on.
LeoIt did not show that scaling this architecture buys you reasoning, or few-shot learning, or any of what came after. "Foundation of modern AI" is something practitioners discovered later, when BERT and GPT each picked up one tower of this design and scaled it. Credit the paper for the instrument, not the symphony.
MayaThat's worth keeping in two separate boxes — what the source showed, and what the field later built on top of it.
LeoAnd the second poke is the one we flagged at the Matchmaker. Every word attending to every word means doubling the document quadruples the work. Our law firm feels this the day the partners want a whole deal room in context — the assistant that was snappy on a fifty-page contract starts billing like a senior partner at a million tokens.
MayaAnd here's what I find genuinely admirable. The authors saw it. The paper's own closing section proposes restricted attention for long sequences as future work. The limitation that launched a hundred follow-up papers is written into the paper itself.
LeoIncluding next episode's. Kimi Linear, from 2025, is a direct descendant of that one future-work sentence — keep the quality, attack the cost.
MayaSo let's land this. The reason the paper still matters isn't nostalgia. The reading tower became BERT. The writing tower became GPT. The architecture under whatever assistant you talked to this morning is, with modest renovations, this diagram.
LeoWhich makes it the rare 2017 paper where reading the original is a working skill, not a history lesson.
MayaAnd the deepest lesson is the subtraction. The whole field assumed recurrence was the load-bearing wall, and attention was the trim. This team deleted the wall, kept the trim—
Leo—and the building stood up straighter. Cheaper, faster to train, better scores. The subtraction paid three times.
MayaSo here's the question to carry into your week: in the system you work on, which component does everyone treat as load-bearing simply because it has always been there — and what small experiment would tell you whether the building stands without it?
Source material
← Back to Mastering Language Models: From Architecture to Optimization