Transcript
MayaLast time we read the 2017 paper cover to cover — the parallel lookup that deleted recurrence, and the confession on its final page that everyone-looking-at-everyone gets brutal as sequences grow.
LeoToday's paper is that confession grown up and holding a benchmark table. Kimi Linear, from the Kimi Team at Moonshot AI, late 2025. The claim: the first architecture where mostly-linear attention beats full attention in a fair fight.
MayaBefore any math, picture a person. A risk officer on a trading floor, standing at one whiteboard. The board never grows. A new price arrives — she doesn't add a line. She finds the stale entry, erases exactly that cell, writes the correction in its place.
LeoSame board all day.
MayaSame board all year. And the columns fade on different schedules — intraday positions wiped within the hour, counterparty limits up for months. She isn't remembering everything. She's curating what deserves the space.
LeoAnd the paper's bet is that a language model's memory can mostly run like her board. Fixed size. Self-correcting. Forgetting on purpose, column by column.
MayaMostly — with a proper archive down the hall, consulted on one floor in every four. That ratio is half the story; we'll get there.
LeoFirst, why she's needed. The 2017 machine works — we spent an episode on why.
MayaWorks, and pays rent forever. Every word a transformer generates consults a stored key and value for every word before it. That store is the key-value cache — the kay-vee cache, as you'll hear it said. It grows with every token, and at generation time it's what your GPU memory is actually full of.
LeoPut our law firm back in the room. The contracts assistant held up fine on a fifty-page agreement. Now the partners want the whole deal room in context — a million tokens — and they want an agent, not a reader. Drafting, checking precedents, running for hours.
MayaWhich is the regime this paper opens with: models becoming agents, reinforcement learning stretching them across long trajectories — the cost center migrating from training to inference. The model decodes for pages now, not paragraphs.
LeoAnd in that world the cache is the rent — due on every token, for every concurrent matter, forever. So. The board. How does a fixed grid replace an archive?
MayaThe Board — landmark one. Linear attention keeps one fixed-size grid of numbers, a memory state, updated as each word streams past, instead of a store that grows. A thousand tokens in or a million: same grid, same cost per step.
LeoWhich sounds suspiciously like the recurrent network we spent last episode deleting.
Maya[chuckle] Structurally, it is one — and that's no longer the insult it used to be. The 2017 move was: stop compressing history, look everything up. This family says: compress again, but compress well.
LeoExcept linear attention has been declared the future roughly annually since 2020, and it kept losing to plain softmax attention. Not just on long documents. On short ones.
MayaBecause the naive board only adds. Every word stamps its key-value association on top of everything already written. Nothing is erased, old associations interfere with new ones, and recall turns to mush.
LeoA whiteboard nobody erases is a gray board.
MayaSo the first repair is the Eraser — the delta rule, which predates this paper. Before writing, check what the board already says for this key. If it's stale, subtract the old association and write the corrected one. Overwrite, don't pile.
LeoThe risk officer erasing the dead price instead of scribbling next to it.
MayaAnd the formalism is lovely — the memory takes a tiny error-correction step toward "this key now maps to that value." It learns while it remembers.
LeoStill prior art. DeltaNet had the eraser; Gated DeltaNet added fading on top — a forget gate, so stale entries decay even without a correction. What did this team add?
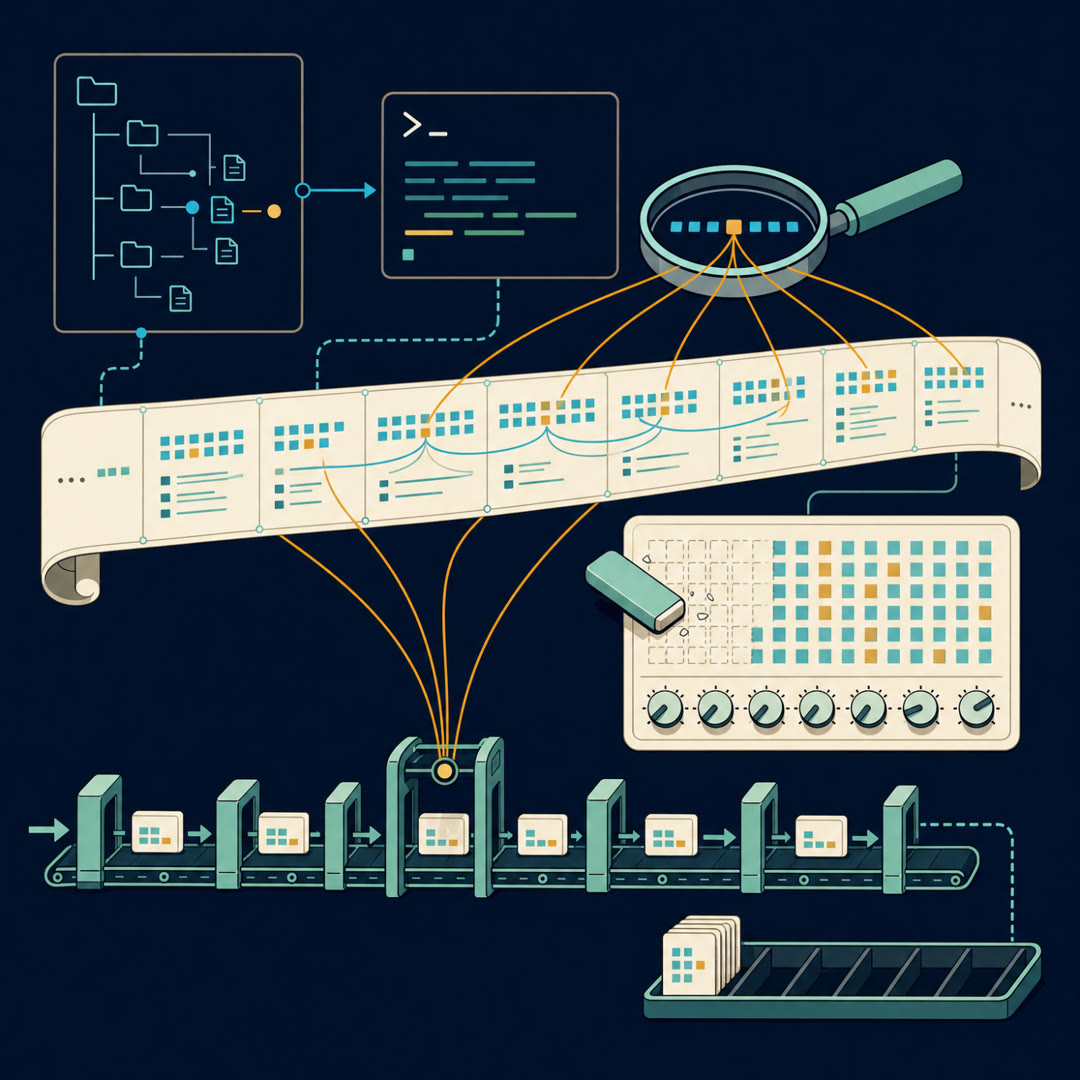
MayaThe Knobs. This is the paper's heart, so let me go slowly. Gated DeltaNet's fading is one master dial per attention head — everything that head holds fades at one shared rate. Kimi Delta Attention — K-D-A from here on — gives every feature channel its own dial, each learning its own forgetting rate from the data, at every step.
LeoThe columns of her whiteboard — except the model tunes the schedules itself.
MayaAnd one master dial must split the difference between a channel that should evaporate in three words and a neighbor carrying the document's subject for thousands — it does both jobs badly. Per-channel dials do both well.
LeoOkay, here's my reflex. Fine-grained gating isn't free — fancier per-channel math is exactly what looks expressive on paper and then crawls on real hardware. Kernels are where linear-attention dreams go to die.
MayaWhich the authors clearly knew — half the paper is the kernel. The textbook version of this math is slow and numerically twitchy at low precision. They constrain it to a special case faithful to the delta rule, and the resulting chunk-by-chunk algorithm runs roughly twice as fast as the general recipe.
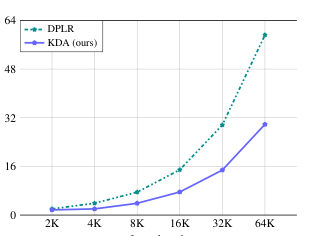
LeoTwice. Huh.
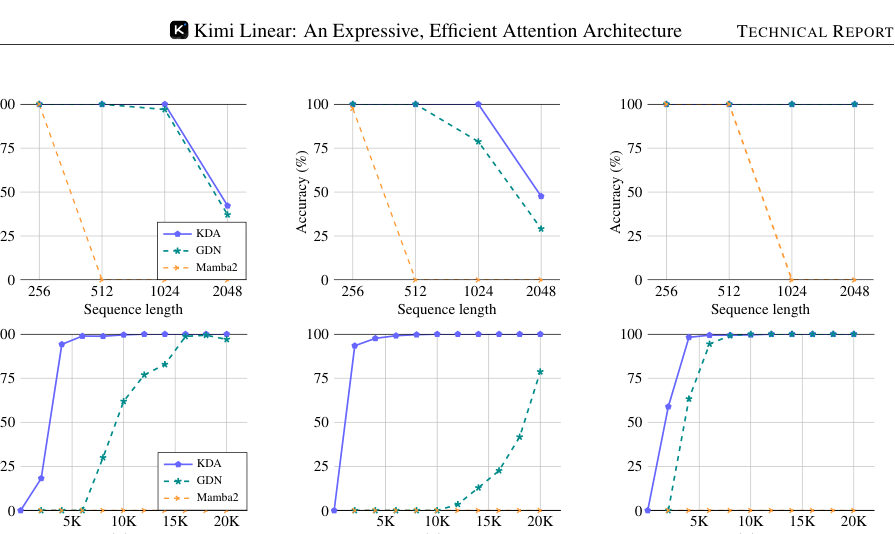
MayaThey also road-test the cell on toy tasks built to embarrass fixed-size memories — reproducing a sequence backwards, recalling several planted key-value pairs, tracking dozens of little stacks.
LeoWhere the per-channel knobs converge faster than the master dial, and the decay-only boards — fading, no eraser — fail outright. I appreciated that detail. It locates which ingredient wins.
MayaSo that's the new memory cell. Now the part I flagged at the top — the Floorplan.
LeoThe archive down the hall.
MayaBecause even a brilliant fixed board has a ceiling. Some questions are needle-in-a-haystack: retrieve one exact clause, verbatim, from eight hundred pages. Compression — any compression — eventually loses that bet, and the authors say so plainly.
LeoThe firm's nightmare case. "Quote me the indemnity carve-out from the disclosure schedule." Approximately right is wrong.
MayaSo Kimi Linear doesn't abolish full attention — it rations it. Three K-D-A floors, then one floor of genuine all-pairs attention — the memory-thrifty variant from the DeepSeek lineage, multi-head latent attention — then three more. Three to one, the whole way up.
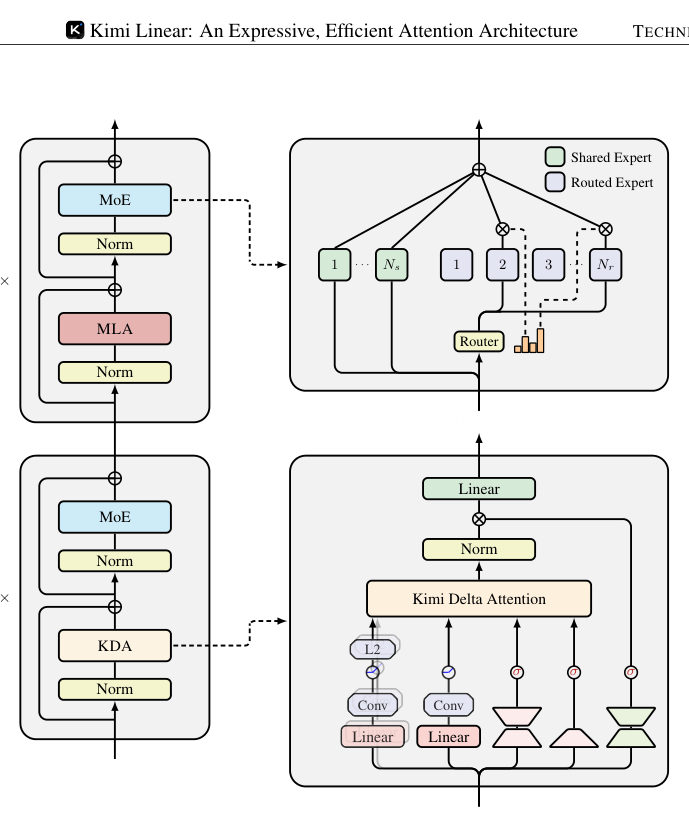
LeoAnd the ratio wasn't picked by vibes. The ablation runs the alternatives: all-full-attention does worse, seven-to-one and fifteen-to-one slide, one-to-one matches quality but costs more to serve. Three-to-one sat at the optimum.
MayaSit with that first clause.
MayaThe all-full-attention baseline lost. The configuration the field treats as the gold standard was not the best configuration in the study.
LeoWe'll fight about that in a minute.
Maya[chuckle] We will. One more design choice — the strangest, and my favorite. Those full-attention floors carry no position signal at all. Remember the wave-stamp from last episode, the chord that let order survive the parallel lookup? These layers don't have one.
LeoNothing? Word soup?
MayaNothing explicit — because the K-D-A floors already encode order. If memories fade as words stream by, recent is loud, distant is faint, and the geometry of when is woven into the state itself—
Leo—so the forgetting is the position signal. The fading does the chord's old job.
MayaAnd it simplifies long-context engineering, too — stretch the window and there are no wave frequencies to retune.
LeoDeployment people just sat up.
MayaThen the floorplan pays its bill: only one floor in four keeps a kay-vee cache at all, so the cache shrinks by up to seventy-five percent.
LeoAll right. The numbers. Then I get my fight.
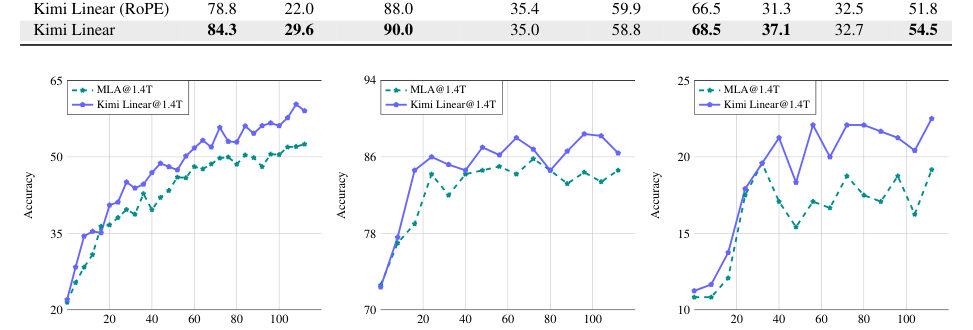
MayaMatched runs — one point four trillion training tokens, identical recipe, three contenders: full attention, the strongest prior hybrid, and Kimi Linear. It wins the short-context exams — nearly four points clear on the hard knowledge benchmark. Wins the long-context stress test. Wins the reinforcement-learning-style evaluations. And at a million tokens, each output token arrives roughly six times faster.
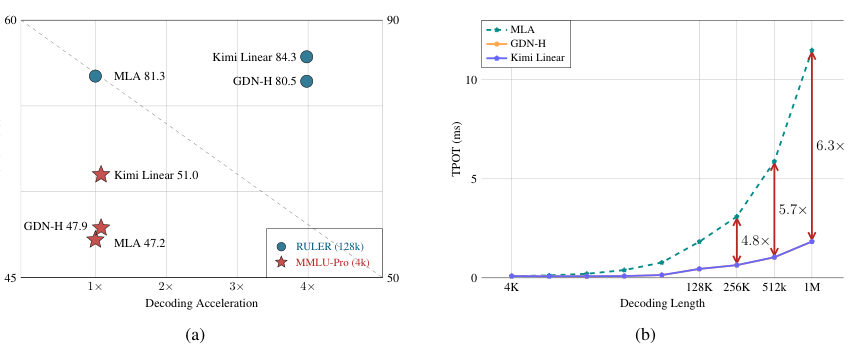
LeoSix.
MayaFor the firm: the deal-room agent answers in seconds instead of half a minute, and the cache savings let one GPU hold several matters at once.
LeoOkay, the fight. I have watched this movie. Every linear-attention paper for five years has beaten full attention somewhere — in-house, on the authors' benchmarks, at the authors' scale — and the win evaporates when someone outside the lab runs it hard. Forty-eight billion total parameters, three billion active, is not frontier scale. And — "beats full attention"? They kept full attention! One floor in four! That's not beating the archive, that's keeping it on retainer!
MayaOn retainer at a quarter of the cost — and the retainer is the point! The claim was never "compression solves exact recall." The claim is the inversion: make the cheap floors expressive enough, and full attention stops being the thing you maximize and becomes the thing you ration. And the fight was staged fairly — same data, same recipe, same size, no strawman—
Leo—fairly by their own referee. Authors pick the benchmarks. Authors run the baselines.
MayaWho then published the kernels, the checkpoints, the serving integration. Falsifiable by anyone with a cluster — the opposite of a demo video.
LeoSo here's what I concede, and where I hold. The throughput claim survives — six-fold at a million tokens isn't a benchmark, it's an architecture property; it follows from what a fixed-size state is. And the fairness design is real. Shipping the artifacts is how you earn belief.
MayaBut?
LeoTheir own scaling-law fit shows the efficiency edge at small scale is modest — comfortably above one, nowhere near two. And quality at frontier scale is exactly the question these experiments cannot answer yet.
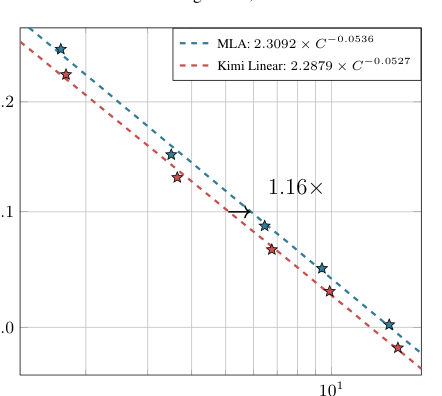
MayaFair — and here's the mirror concession. Pure linear attention still can't do verbatim retrieval at distance; the paper says so itself, and the hybrid is that concession drawn as a floorplan. So the honest reading isn't "linear attention won." It's narrower, and still remarkable: at this scale, on this suite, the quality tax for going three-quarters linear is gone — and it went negative.
LeoAnd what settles the rest is boring and slow. Other labs, bigger runs, recall workloads designed by people who want it to fail. The argument doesn't end in this paper. It ends in replication.
MayaAgreed. And notice where that leaves the topic. The 2017 authors called restricted attention future work on their own final page. Eight years later, the strongest answer yet doesn't replace their machine — it mixes it: three floors of disciplined forgetting for every floor of total recall.
Leo[chuckle] The field's answer to "attention is all you need" turning out to be: about a quarter of it, plus a very good eraser.
MayaTopic one closes here — the machine, its source, now the counterproposal. Next, the series climbs a level: not how these models are wired, but what it costs to grow them.
LeoSo the question to walk away with. Your systems remember by default too — logs, caches, histories, kept because keeping is easy. If you had to design the forgetting on purpose — what fades in an hour, what holds for a year — what would you erase first, and what would that finally let you afford?
Source material
← Back to Mastering Language Models: From Architecture to Optimization