Subscribe
Transcript
MayaA junior associate at a law firm gets a two-hundred-page contract at nine in the morning. He reads it the only way he knows — front to back, carrying everything forward in his head. By page eighty he hits a clause that says "as defined above," and the definition, back on page three, has gone blurry.
LeoBeen there.
Maya[chuckle] Now watch the partner. She unclips the binder, spreads all two hundred pages across the conference table, and when she hits that clause on page eighty she just — looks. Straight at page three.
LeoAnd that look — page eighty to page three in one move, no relay in between — is the whole revolution we're covering today.
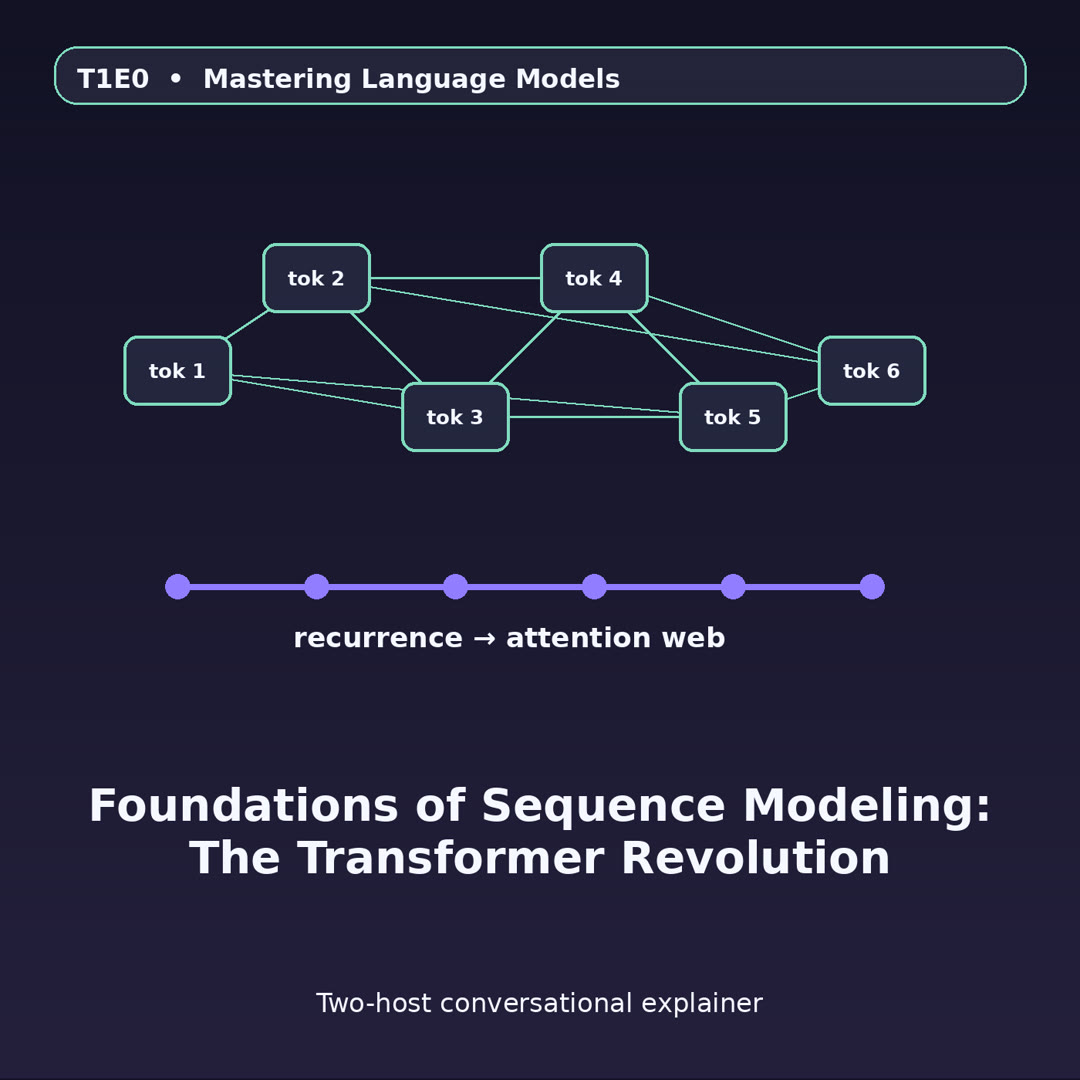
MayaThat's self-attention. One idea: let every word in a sequence look directly at every other word, all at once. It sounds almost too simple, and it rebuilt the field.
LeoLast episode we walked the seven stops of this series, architecture through optimization. Today, the first stop: the Transformer, and the 2017 paper that started everything — "Attention Is All You Need."
MayaPlus a much newer paper — Kimi Linear, from late 2025 — because this foundation is being renovated while we stand on it. This overview hands you the topic's working parts; the next two episodes go deep on each paper.
LeoOne team rides with us the whole way: a firm building a contracts-review assistant. Their wish list is the topic in miniature. Connect a clause on page three to a definition on page eighty. Train on millions of documents in reasonable time. And once the partners want whole deal rooms in context — a million tokens — keep the cost per question sane.
MayaLong-range connections, parallel training, affordable serving. Hold those three; this whole topic is a fight over them.
LeoSo start before 2017. What was the machine doing wrong?
MayaCall that era the Relay. The dominant tools were recurrent neural networks — R-N-Ns. A recurrent network reads like our junior associate: one word at a time, compressing everything it has seen into a single running summary it carries forward.
LeoOne summary. Fixed size. So a two-hundred-page contract gets squeezed through a keyhole?
MayaA keyhole re-packed at every word. Each step hands a rewritten note to the next, and page three has to survive thousands of consecutive rewrites to still matter on page eighty.
LeoMm. It rarely survives.
MayaIt rarely survives. Researchers bolted gates and memory cells onto the relay — the L-S-T-M family — and it helped. But the deeper problem wasn't the note. It was the relay itself.
LeoRight — here's what bothered builders even when accuracy was fine. Step five hundred can't start until step four ninety-nine finishes. You've got a rack of GPUs, chips happiest doing thousands of things at once, standing in line.
MayaSo the Relay charges two tolls. Long-range information decays, which hurts quality. And nothing runs in parallel, which caps how big you can train.
LeoThe second toll turned out to be the killer. Hmm — attention itself wasn't new in 2017 though, right?
MayaIt existed as a patch. Translation systems already let the output peek back at the input — attention as a side dish on a recurrent spine. The 2017 move, from Vaswani and colleagues at Google, was the audacious part: throw away the spine, keep only the peeking.
LeoHence the title. "Attention Is All You Need" isn't a description — it's a dare.
MayaSo now the Table — the partner's conference table. In a Transformer, every word questions the entire sequence at once. Each word computes— okay, here's the cleaner way in. Each word publishes three things. A query: what am I looking for. A key: what do I contain. And a value: what I hand over if you pick me.
LeoSo the clause on page eighty broadcasts "looking for the definition of material adverse change," every other token holds up its key, and whoever matches gets… what, votes?
MayaWeighted votes. The match scores become weights, and the word pulls in a blend of values, mostly from the best matches. Page eighty reaches page three in one hop. Not three thousand relay steps. One.
LeoOne hop.
MayaAnd the lookup runs many times in parallel — multiple heads, each learning a different relationship. One tracks who-did-what-to-whom, another definitions, another which pronoun points where.
LeoOkay, the builder objection — I had it on first read. If every word looks at every word simultaneously, nothing knows its position. "The vendor pays the client" and "the client pays the vendor" become the same bag of words.
MayaThe paper's fix: stamp each word with a position signal before it reaches the table — a mathematical timestamp blended into the word's representation. Order goes in as data, not as processing sequence.
LeoAnd that's the unlock. No relay, so the whole sequence computes at once and the hardware runs flat out. The original paper trained its best translation model in about three and a half days on eight GPUs and beat systems that had burned far more compute. That's not just a quality story — that's a throughput story.
MayaIt's both, and the field noticed. Within two years essentially every serious language model was a Transformer. Pre-training at scale only became thinkable because training parallelized.
LeoBefore the fight — and there's a real one — the shared ground. The mental models both camps agree on.
MayaThe one I'd tattoo on the field: attention is content-based lookup. Stop picturing a brain; picture a soft database query. Each token asks, the whole context answers, relevance sets the weights — and architecture design starts to read as database engineering.
LeoThen the budget one: training cost and serving cost are two different bills. The Transformer made training cheap per unit of quality. At serving time it pays a different price, which we're about to meet. Serious people never confuse the two budgets.
MayaThat holds — and the third sits underneath both. Architectures win by fitting hardware, not by being clever. The Transformer didn't beat recurrence on elegance; it won because wide, parallel matrix math is exactly what GPUs sell. Every architecture debate since is secretly a hardware debate.
LeoSecretly? Openly.
Maya[chuckle] Fair. Which brings us to the fine print on the Table.
LeoThe Bill.
MayaThe Bill. If every token attends to every token, the work grows with the square of the sequence length. Double the contract, four times the attention computation.
LeoAnd the sneakier line item lands at serving time. To generate each new word, the model keeps every previous token's keys and values parked in GPU memory — the kay-vee cache, K-V for key-value. It swells with every token of context, so at a million tokens—
Maya—the cache is the product. That's what you're really renting GPUs to hold.
LeoThe wall our law firm hits. One contract, fine. The whole deal room — a million tokens — and the kay-vee cache decides how few users fit on each GPU. Agentic workloads, models thinking in long tool-calling loops, only stretch the context further.
MayaWhich is where serious people split. Real camps, real evidence — let's argue it properly. I'll take exact attention.
LeoThen I'm taking the linear side. Go.
MayaFull softmax attention — the exact, every-token-to-every-token kind — is the only mechanism ever proven at frontier quality. Every model that has defined the state of the art rode on it. And its recall is exact: when the answer lives in one clause on page three, exact attention puts its full weight right there. Approximations smear.
LeoApproximations did smear — five years ago. Look at this topic's second source, the Kimi Linear paper. Its linear layer, Kimi Delta Attention, keeps a fixed-size memory and updates it with fine-grained, channel-by-channel forgetting. Not compress-and-pray — a learned rule for what to keep and what to fade. Head-to-head, matched training, it beats the full-attention baseline — while cutting the kay-vee cache up to seventy-five percent and decoding up to six times faster at a million tokens.
MayaIn their evaluations, at the scales they trained. And notice what the wider field did when attention got expensive — it didn't approximate, it optimized. FlashAttention made exact attention dramatically faster without changing a single output. Engineers kept exactness and attacked the constant factors.
LeoBecause back then they could afford to! FlashAttention speeds up the arithmetic. It does not shrink the cache, and it does not repeal the square. At a million tokens the bill isn't a constant factor — it's the shape of the curve.
MayaHmm. Fine — the cost argument survives. The cache is a wall, not a tuning problem. But here's what I won't concede. Even Kimi Linear doesn't trust pure linear attention. Read the architecture: every fourth attention layer is still full attention. Three to one. They kept exact lookup in the loop because some retrieval simply needs it.
LeoThat concession I'll hand right back — the hybrid is the honest headline, not "linear kills attention." Their own design admits some exact attention is load-bearing. The paper's real result is that it's a far smaller share than anyone assumed.
MayaSo here's where the evidence stands. Exact attention is the proven default at the frontier. Expressive linear attention has shown, below the frontier, that you can swap out most of it and lose nothing they could measure. What settles it is the experiment nobody has published: a frontier-class model, hybrid versus full, on the hardest recall benchmarks.
LeoOur law firm doesn't have to wait for that paper, though. At their scale the hybrid math already works — deal-room context, a quarter of the cache, multiples of the throughput. A bet they can take today.
MayaThat's the topic in one frame. Next episode we sit with the 2017 paper itself — the Table in full detail: multi-head attention, the encoder-decoder design, and the limits the authors themselves flagged.
LeoThen Kimi Linear gets the same treatment — what delta-rule memory actually does, how the hybrid is wired, and how far those claims stretch outside their benchmarks.
MayaBefore the closing question, let's pin the vocabulary this topic runs on.
LeoRecurrence means processing a sequence one step at a time, carrying a single running summary forward.
MayaSelf-attention means every token directly scoring its relevance to every other token and blending what it finds.
LeoQuery, key, and value mean the three roles each token plays in that lookup — what it seeks, what it advertises, what it hands over when chosen.
MayaParallelization means computing across the whole sequence at once — the property that made large-scale pre-training affordable.
LeoQuadratic cost means work that grows with the square of the sequence length — double the document, four times the computation.
MayaThe kay-vee cache means the stored keys and values for every previous token, kept in memory while generating — the thing that swells with long context.
LeoAnd linear attention means designs that replace the all-pairs lookup with a fixed-size memory updated as the model reads — constant cost per token, with the recall trade-offs we just argued.
Maya2017 paid a quadratic price so every token could see everything, and 2025 is busy negotiating that price back down. So carry this into the deep dives: when you read a long document yourself, how much of it do you need exact recall of — and how much could live in a lossy running summary without ever changing your conclusion?
Source material
← Back to Mastering Language Models: From Architecture to Optimization