Subscribe
Transcript
MayaWhy does a model that can write you a flawless shell script freeze the moment you put it at a live terminal and say: go do that, on this machine, now? Ask it to explain how to find every large log file, compress them, clear the old ones — clean answer, every flag correct. But sit it down to actually run it, and it types one command, the output isn't what it expected, and it just... stalls. Same model. Knew the recipe cold. Can't run the stove.
LeoNot a knowing problem, then.
MayaIt's a doing problem. And that gap — between knowing the command and being able to drive the machine through a real task — that's the whole subject today. The terminal is where code stops being text you write and becomes an action you take. Type, read what came back, react, type again. Nobody learns that from reading.
LeoSo where did we leave the agent? With SWE-Hub — the data factory, four stations, the fight over whether a "build a feature" task can ever be graded like a bug-fix. Where does today peel off from that?
MayaSWE-Hub was a factory for software-engineering tasks — fix this, build that, inside a repo. Nemotron-Terminal narrows to one muscle the whole topic danced around: the terminal itself. And it does something none of the others did — builds all its training tasks synthetically. No mining real repos. Top to bottom, it manufactures the curriculum.
LeoHuh. Fully synthetic.
MayaFully synthetic. And it hangs the whole result on a line you coined back in the overview, Leo — without knowing this paper would be the one to prove it.
LeoTerminal capability is a data-engineering problem wearing a machine-learning costume.
MayaThat line, with receipts. The authors basically say: nobody published how you build the data that makes a terminal agent good — the top systems did it behind closed doors. So they did it in the open and measured every choice.
LeoAnd "terminal capability" isn't "can it use Linux." It's whether the model can behave like an agent at a command line — run a command, read the output, pick the next move from what it saw, recover when something errors out. A loop, not a one-shot.
MayaExactly. Single-shot code generation is "write the recipe." Terminal capability is "stand at the stove and adjust as it cooks." Multi-turn, stateful, and the world talks back at every step.
LeoAnd the headline — does the data engineering actually move that needle? Give me a number I can hold.
MayaThe one that made me sit up. A thirty-two-billion-parameter base model. On Terminal-Bench — the exam for this skill — it scores around three percent. Barely registers. Train it on their engineered data, same model, no size change. It jumps to twenty-seven.
LeoThree to twenty-seven. On the same model.
MayaSame weights to start. The only thing that changed is the data it saw. And the smaller models climb the same way — the eight-billion from basically nothing to around thirteen, the fourteen to around twenty. The punchline: the trained thirty-two-billion matches systems much larger than it.
LeoThe topic's thesis, made literal. The leaderboard number is the trophy — but the lever that moved it wasn't a bigger brain. It was the kitchen the data came from.
MayaThe lever was the data.
LeoThen take me into the kitchen. How do you manufacture a terminal task? Because a bug-fix task, I get — there's a real broken thing, a real test. What's a synthetic terminal task even made of?
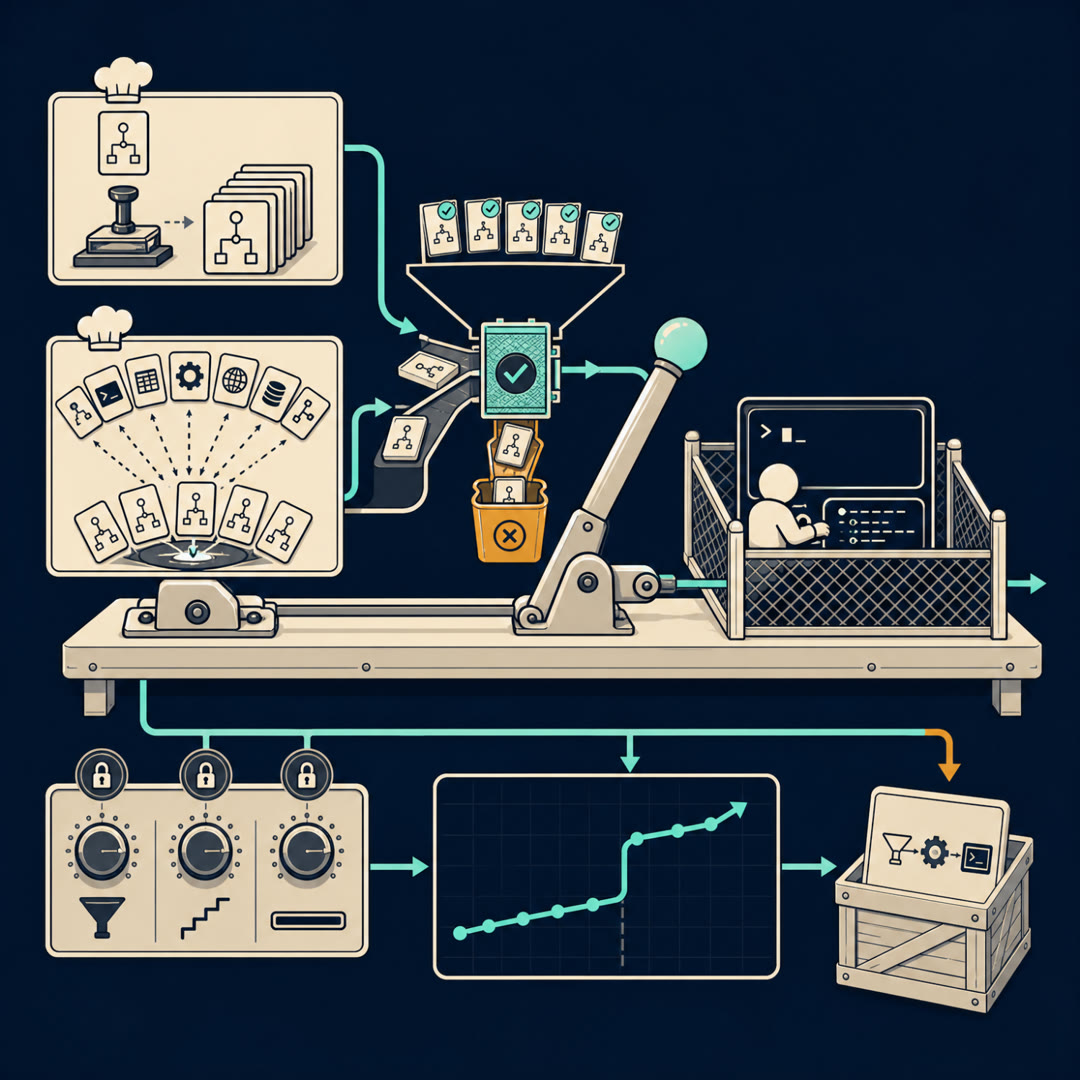
MayaNow we're at the heart of it. The paper splits its task-making in two — I'll name them so we can argue later. There are two kitchens. There's the Seed Kitchen — seed-based generation. You start from a real reference task, a concrete terminal job, and generate variations around it. New filenames, new directory layouts, new constraints, but anchored to a real example as the seed.
LeoThe seed keeps it honest, then. A real shape of work, just multiplied.
MayaRight. Then there's the other one — the Skill Kitchen, skill-based construction. You don't start from a task at all. You start from a capability — "manipulate file permissions," "parse and filter logs," "manage processes" — and synthesize fresh tasks to exercise that skill, whether or not a real seed ever existed.
LeoWait. So one starts from a real thing and varies it, the other starts from a category and invents things to fill it. Those are genuinely different bets.
MayaCompletely different bets — and exactly where you and I are going to fight, because the paper uses both, but a practitioner has to decide which to lean on, and they pull in opposite directions.
LeoBefore we fight — the part I always ask. How do they know a synthetic task is any good? You can generate a million terminal tasks. Most generated anything is garbage. What's the gate?
MayaHere's the data-engineering half, where the real work lives — not in generation, in selection. Three dials the data engineer is turning. The Filter — they don't keep what they generate; they filter hard. A task has to be solvable, well-formed, verifiable. Out go the broken ones, the ambiguous ones, the ones with no clean success condition.
LeoThrow most of it away.
MayaThrow most of it away. The Ladder — curriculum. You don't open with the hardest multi-step marathon; you stage difficulty so the model climbs instead of drowning. And the Horizon — long-context training. Terminal transcripts get long: command, output, command, output, page after page. If the model can't hold a long history, it loses the thread halfway through. So they train the long horizon on purpose.
LeoSay those three back. Filter — keep only clean, verifiable tasks. Ladder — stage easy to hard. Horizon — long transcripts so it doesn't lose the plot. And those dials are the actual paper, more than the generation trick.
MayaThat's the honest reading. The generator gives you raw ore. The dials are the smelting. Skip them and you have a pile of synthetic noise that looks like terminal data and teaches almost nothing.
LeoOkay. Now the fight, because I've been holding it. Seed Kitchen versus Skill Kitchen. Make your side first — you take Skill, I can tell you want it. Sharpest form, then I swing.
MayaSharpest form. Skill-based wins because real tasks don't cover the space. Vary only real reference tasks — the Seed Kitchen — and you can only teach skills that already showed up in your seeds, and that set is small and lopsided, clustered on common stuff with whole regions empty.
LeoSo how does skill-based reach the empty regions?
MayaSkill-based says: here's a map of terminal capabilities, generate tasks in the corners no seed ever touched. Coverage by design, not by luck. The model matching things twice its size isn't more of the same — it's the skill map filling the gaps.
LeoMy turn. Skill-based is also how you build a model brilliant at a synthetic dialect of the terminal and shaky at the real one. Generate from a named skill with no real seed, and the generator invents what it thinks that skill looks like — and that's subtly, systematically off from real work.
MayaOff how, concretely?
LeoTidy when reality is messy. Error messages too clean, layouts too sensible, failures too cooperative. Train on that and you ace your own synthetic exam, then stumble the second a real machine hands you an ugly stack trace. The Seed Kitchen keeps one foot nailed to the floor.
Maya{pause=0.8} That lands. The synthetic-dialect risk is real — and worse for terminal work than for code, because the terminal's whole character is unpredictable real-world mess. Permissions you didn't expect. A tool printing to the wrong stream. So I'll concede the sharp version: skill-based generation, ungated, drifts into a dialect.
LeoAnd I'll concede mine. Seed-only doesn't scale to coverage. Real terminal examples are lopsided and scarce. Purist about anchoring everything to a real seed, and I run out of seeds long before I run out of skills the agent needs — capped at "whatever happened to be in my reference set."
MayaHere's where it settles — and this is not the portfolio we drew on SWE-smith; that was where a bug came from. This is where a whole task comes from, a different axis. Seed buys fidelity — tethered to real shapes of work. Skill buys coverage — it reaches the corners. You don't pick. Seed keeps the distribution honest, skill reaches what seeds never will, and you run both through the same three dials — because the Filter stops the Skill Kitchen shipping its dialect.
LeoMeaning the filter is the referee between the two kitchens.
MayaThe filter is the referee. Coverage from skill, fidelity from seed, and a hard gate that throws out anything from either kitchen that doesn't behave like real, verifiable terminal work. That's the recipe — and the three-to-twenty-seven jump is the evidence.
LeoWhat would settle which kitchen matters more? Right now we've got a clean truce and no scoreboard between them.
MayaThe honest test is the one this topic keeps returning to — held-out real terminal tasks training never touched. Terminal-Bench is built from real-feeling work, not their generator. So synthetic-trained models jumping there, on an exam the generator didn't write, is the strongest sign the dialect didn't swallow them. The clean experiment nobody's shown: train seed-only, skill-only, both, same dials, see which gap to real-task performance is smallest. Until then we know the blend works. We don't know the mix.
LeoRun our bug through it. The one we've carried all topic — real repo, a failing test, a few files, a hidden check. Where does terminal capability even touch that?
MayaBeautiful question, because it shows what this paper's for. Your bug-fix needs the agent to drive first. Clone the repo, run the failing test, read the output, parse the traceback, edit, re-run, read again — all at the terminal. Every paper this topic gave the agent a gym to fix the bug in. This one trains the hands that operate the gym. Without it, the agent writes a perfect patch and still can't apply and confirm it, because it can't reliably run the loop.
LeoThen this isn't a competitor to SWE-Gym or SWE-Hub. It's the layer underneath. The motor skills.
MayaThe motor skills. Yes.
LeoAnd the artifact. The topic trained me to ask — what outlasts the checkpoint they shipped this week?
MayaTwo things. The dataset they release in the open — Terminal-Corpus, the engineered tasks. And more durably, the recipe for the pipeline — Terminal-Task-Gen, generator plus three dials, spelled out so you could rebuild it. A dataset ages; next year's terminal tools won't be in it. The pipeline you point at new skills, new tools, and it makes fresh data without you. The model is the trophy. The generator-plus-filter is the factory — to borrow last episode's word.
LeoLimitations. "We solved terminal data with synthetic generation" is exactly the claim that's cleanest in the abstract.
MayaA couple of them bite. The big one's the one we fought about — a truce doesn't dissolve it. Everything is synthetic, and the filter is your only defense against the dialect — but a filter is itself a model with blind spots. If generator and filter share the same wrong idea of a terminal task, the dialect sails through the gate.
LeoAnd the headline number itself?
MayaThey check against a real benchmark, which is right — but twenty-seven percent also means it fails most real terminal tasks. Long way to go.
LeoA lot of room above twenty-seven.
MayaA lot of room. And the other one — these are Terminal-Bench numbers. One benchmark, one definition of "terminal task." Strong evidence the method works, but terminal capability in the wild is broader and meaner than any one exam — weird shells, broken tools, side effects that don't undo. Proven on the slice the benchmark measures. The rest is a bet.
LeoIt's the lit corner of a dark kitchen, then. We trust the engineered data because it lifts a real held-out number. We just can't see how far that real number generalizes past the edge of the light its own benchmark casts.
MayaThat's the surface to watch.
LeoPlate it up. The whole dish in one serving.
MayaA model can know every command and still freeze at a real prompt, because terminal capability is doing, not knowing — and Nemotron-Terminal manufactures that skill with data engineering instead of a bigger model: generate tasks two ways, seed-based for fidelity, skill-based for coverage, run both through three dials — filter for quality, ladder the difficulty, train the long horizon.
MayaAnd the payoff: a thirty-two-billion model goes three to twenty-seven on a real exam and matches models much larger. The fight is which kitchen carries the load, and the filter's the referee keeping the synthetic dialect off the floor.
LeoAnd the line I'm keeping is the one you opened with. You can read your way to knowing a command. You cannot read your way to terminal skill — you have to drive. This is the paper that finally wrote down how to teach the driving.
MayaThat's the one. The model that froze at the prompt didn't need more knowledge. It needed practice it had never been given — and now there's a factory that gives it.
LeoSo here's what I'm turning over, and I don't have a clean answer. If a synthetic pipeline can teach a model to drive a terminal well enough to match models twice its size — how much of any hard agent skill is really a data-engineering problem we just haven't sat down and engineered yet, and how much genuinely needs a bigger model?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents