Subscribe
Transcript
MayaSWE-Hub isn't a dataset — it's a factory. Every other paper this topic perfected a single dish. Forge a bug here. Mine a commit there. Grade with two judges over there. Beautiful, individually. Today's paper does the opposite move: stop cooking dishes, build the line. Receiving dock, prep, cook, plate, quality check — one floor, every step wired to the next, running day and night.
LeoA factory instead of a chef.
MayaA factory instead of a chef. That's the whole turn today. SWE-Hub isn't a new trick for making one kind of training task. It's the assembly line that makes all of them — and keeps making them.
LeoR2E-Gym sharpened one station — two graders that fail in different directions, and the win was refusing to pick between them. Today doesn't sharpen a station; it builds the whole line the stations sit on. That's the peel-off.
MayaR2E-Gym handed us one excellent station — mine commits, grade with a hybrid. Today's paper backs the camera all the way out and asks the production question nobody in the topic has owned: how do you run every station, on thousands of repos, in many languages, on a cluster, forever? Not "what's the cleverest task." "What's the supply chain."
LeoThe supply chain. Huh.
MayaAnd the paper has a phrase I want to plant up front, because everything hangs on it. They call the thing they're building a data factory. Not a dataset. A factory.
LeoPin that for me. The whole topic you've been hammering that the reusable thing is the process, not the output. Is this just that idea with a budget?
MayaIt's that idea made literal. A dataset is a stack of printed pages; this is the printing press that keeps stamping fresh pages after the authors go home. SWE-Hub's claim is: the reusable artifact isn't any one batch of tasks — it's an operational system you point at a repo and out comes verified, executable, trainable work. Across the whole lifecycle of software, not just bug-fixing.
LeoAcross the whole lifecycle. That phrase is doing a lot. Unpack it.
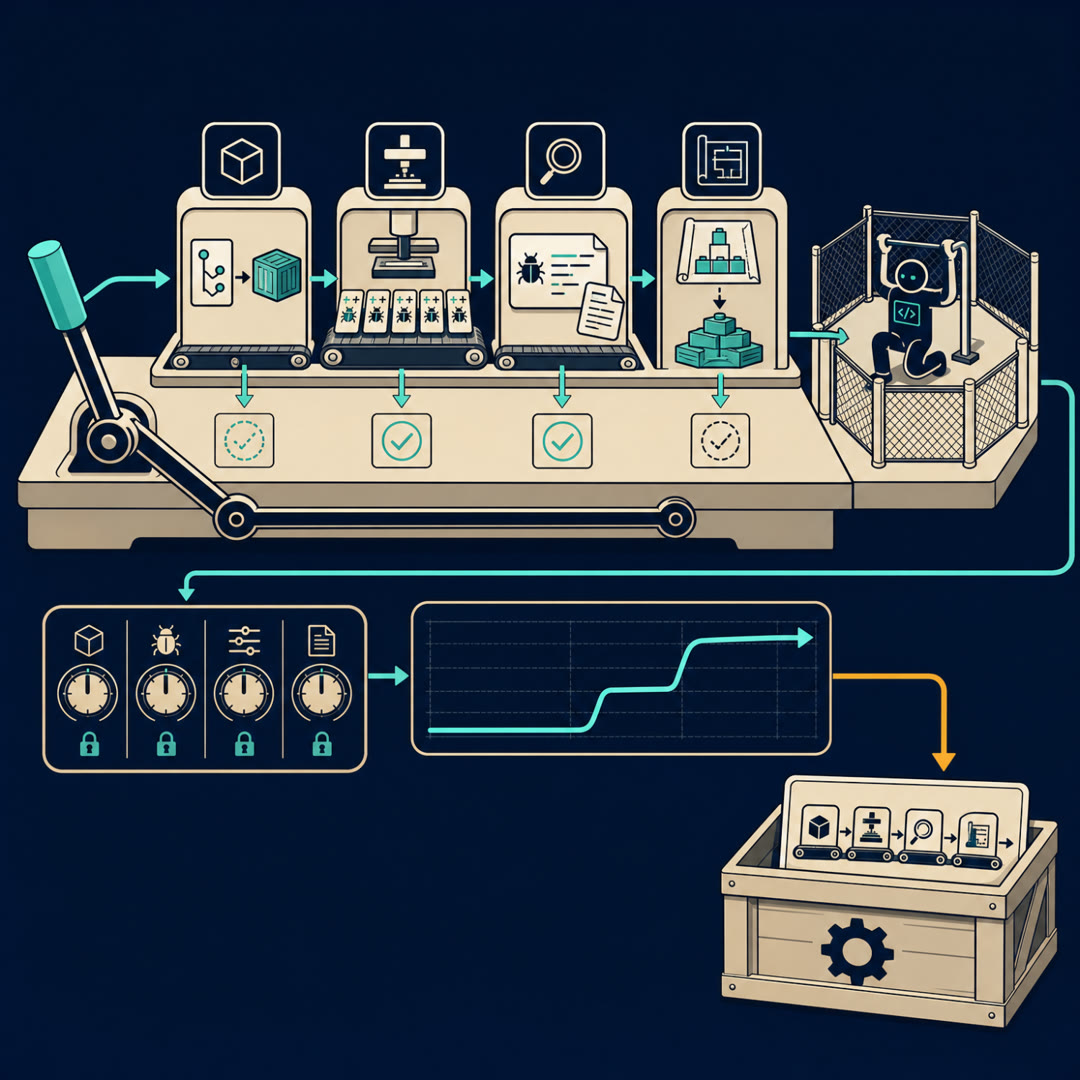
MayaThis is the part that's genuinely new. Let me give you the floor plan — four stations, and I'll name them so we can walk them. Call the whole thing the Assembly Line.
LeoLay it out.
MayaStation one — the Receiving Dock. They call it the Env Agent. You hand it a raw repository snapshot, and it builds a reproducible container you can actually run — dependencies, build steps, the whole environment — across multiple languages, behind one standard interface.
LeoHold on, that sounds boring and it is not. Every paper this topic quietly assumed this part. "Assume an executable environment." This is the assumption.
MayaThat's exactly why it's station one and not a footnote. The entire topic stands on "the task runs." SWE-smith paid per repo to get one Docker image. R2E-Gym needed a live container to verify a test separates broken from fixed. If you can't automatically turn an arbitrary repo into a running environment, your supply chain stalls at the loading dock. The Env Agent is the conveyor that never jams there.
LeoOkay. Receiving Dock builds the kitchen. What's station two?
MayaThe Volume Press — they call it the SWE-Scale Engine. This is the high-throughput line. It uses cross-language code analysis to generate localized bug-fix instances — lots of them — and then validates them at cluster scale. Thousands of small, verified, "this line broke, fix it" tasks, churned out fast.
LeoSo that's the SWE-smith energy. Manufacture bugs at volume, gate them on execution.
MayaSame family, but built for throughput as a service rather than as a paper. The press exists to fill the room. High volume, narrow scope — localized fixes.
Leo"Narrow scope" — I hear a ceiling coming.
MayaYou hear it correctly. Which is station three — the Fidelity Bench. The Bug Agent. Instead of localized line-level breaks, it builds high-fidelity repair tasks: system-level regressions, with issue reports written the way a real user would file them. Messier. More realistic. Lower throughput, higher truth.
LeoAh — the quality lane next to the volume lane.
MayaThe portfolio move you flagged back on SWE-smith — the realistic source sets the ceiling, the infinite source fills the room. Here it's wired into one floor: the Press fills the volume, the Bench raises the ceiling.
LeoThat's three. And you keep saying "whole lifecycle," which means there's a fourth that isn't about bugs at all.
Maya{pause=0.8} Station four is the one that breaks the mold. The Build Wing — they call it SWE-Architect. Every other station, every other paper this topic, has been about repair. Something's broken, fix it. SWE-Architect takes requirements — a spec, a feature description — and translates them into repository-scale build tasks. Not "fix this bug." "Construct this thing."
LeoWhoa. Okay, stop. That's a completely different animal and you slid it in like it's station four of four.
MayaI slid it in on purpose, because that's exactly how the paper presents it — as the natural top of the line. And that's where you and I are going to fight. But finish the floor plan first: Receiving Dock, Volume Press, Fidelity Bench, Build Wing. Environment, scale, fidelity, creation. One system, one interface, continuous output.
LeoLet me say the floor back. Env Agent turns any repo into a runnable box. SWE-Scale presses out localized bug-fixes by the thousand. Bug Agent builds the realistic, system-level repairs. SWE-Architect goes past repair into building features from a spec. And the claim is they're not four papers — they're four stations on one running line.
MayaThat's the floor.
LeoThen here's where I plant the flag, because this is the seam everyone will gloss. Three of those stations produce verifiable work. A bug-fix has a test — broken before, passing after, execution settles it. That's been the bedrock of this entire topic. The hidden test doesn't lie. But "build this feature from a requirement" — what's the oracle? How do you verify a creation the way you verify a repair?
MayaAnd that's the argument. Let me take the breadth side, because I think it's the more interesting bet. Make yours first, sharpest form, then I'll swing.
LeoSharpest form. Here it is. The trustworthy core of agentic-coding training is the verified fail-to-pass task. We spent eight episodes earning that. Execution is the floor that doesn't move. SWE-Architect leaves that floor. A repository-scale build task from a spec has no merged human commit standing behind it, no test that was red and went green — it has, at best, a model judging whether the built thing matches the requirement.
MayaSo it's the judge problem again.
LeoThat's exactly it — the LLM-judge problem we just spent a whole episode showing is biased and gameable, now promoted from grading patches to grading entire features. You're pouring un-verified water into the cleanest reservoir we have. The factory's most impressive station is its least trustworthy one.
MayaMy turn. Granted — the build task's oracle is softer than a fail-to-pass test. I'm not going to pretend SWE-Architect grades as cleanly as the Volume Press. But look at what the narrow, clean signal actually buys you. Every verified-repair pipeline in this topic trains agents to be excellent fixers of localized, well-specified breaks. And the real job — the thing a human engineer does Monday morning — is mostly not that.
LeoSo what is it, then?
MayaIt's "we need a feature, here's a vague spec, go build it across the repo." If you only ever train on verified repairs, you build an agent that's superb at the one slice of the work that happened to be easy to grade. Breadth isn't dilution. It's refusing to let gradability decide what capability you train.
Leo{pause=0.8} Okay. That lands harder than I want it to. Say it again — gradability deciding capability.
MayaThe tail wagging the dog. The whole topic optimized for tasks with cheap oracles, because cheap oracles let you scale. And a real risk is you end up with agents shaped by what's measurable instead of what's valuable. SWE-Architect is a bet that you have to train on creation even when creation is harder to score — or you cap the agent at "good repair tech, never an engineer."
LeoFine — that survives. The ambition survives. I'll give you that the build task is worth training on. But the verification claim doesn't survive yet. Because here's my counter: a station that produces tasks you can't trust the grade on doesn't just add a weak lane — it can poison the strong ones if you mix them in training without keeping the signal separate. A wrong "this feature is built correctly" label is worse than a missing one.
MayaAccepted, and that's the real resolution — it's not breadth-versus-depth, it's breadth with the signals kept honest. The factory framing actually helps here, weirdly. On a real assembly line, every station stamps its own QC grade — you don't ship the high-volume part and the bespoke part under the same certification.
MayaSo the answer isn't "don't build the Build Wing." It's: the Volume Press output carries an execution stamp, the Build Wing output carries a softer stamp, and a training team treats them as different grades of material, never as one undifferentiated pile.
LeoSo we agree on the shape. Breadth is right — train across the lifecycle, repair and creation. But the trust isn't uniform across the floor, and the system's only honest if it labels which station each task came off, so nobody trains on a build-task grade as if it were a fail-to-pass.
MayaThat's the one.
LeoWhat settles the rest? Because right now I'm taking the build wing partly on faith.
MayaWhat settles it is the same thing that's settled every claim this topic — held-out execution on real tasks. Train an agent on the full factory output, repair plus creation, then measure it on the honest exam: real human issues, real hidden tests. If the creation tasks taught transferable engineering, the repair score moves too, not just a creation score you defined yourself. The build wing earns its keep when it lifts the number on the exam nobody let it write.
LeoTrain on the broad factory, test on the narrow honest thing, watch whether breadth shows up where it can't have cheated. I can hold the bet on those terms.
MayaOn those terms it's a real bet, not a leap.
LeoRun our bug through the floor — the one we've carried all topic. Real repo, a failing test, a few files, a hidden check the agent never sees. Where does it touch each station?
MayaThe Receiving Dock takes the repo it lives in and stands up a running container — no human writing a Dockerfile by hand. The Volume Press generates a thousand cousins of your bug — same repo, localized breaks, verified red-then-green.
LeoAnd the other two stations?
MayaThe Fidelity Bench builds the realistic version — a system-level regression with an issue report that reads like a teammate filed it, not a script. And the Build Wing? Your bug doesn't even go there. The Build Wing is for the day the ticket says "add the feature whose absence caused this bug." Repair is one floor of the factory. Creation is the next.
LeoAnd the artifact. The topic trained me to ask — what outlasts whatever model they trained this week?
MayaThe floor itself. Not the tasks, not the checkpoint — the running line. The Env Agent that jams less than a human at standing up environments. The Press, the Bench, the Wing, and the conveyor between them. You point it at a new repo, a new language, next year's frameworks, and it produces fresh verified work without you. This week's score is a single printed copy; the press is what you actually keep.
LeoLimitations. "One factory for everything" is exactly the kind of claim that's cleanest in the abstract and messiest on the floor.
MayaTwo that bite, and they're load-bearing. First — the unification is the risk. Four stations under one roof means four failure modes that can compound. The Env Agent mis-builds an environment, and every downstream task on that repo inherits a corrupt oracle. A bad receiving dock contaminates the whole line. The more integrated the system, the further a single upstream error travels.
LeoThe blast radius of one bad container.
MayaExactly. Second — the one we just fought about. The verification gradient across stations is real and the paper's framing of "executable tasks" risks flattening it. "Executable" means the environment runs. It does not mean every task has a trustworthy oracle. A build task can run and still have no honest way to say "correct." If a training team reads "executable" as "verified," they'll trust the softest grades on the floor — and that's where reward hacking and false-positive labels sneak in.
LeoSo the same worry as the whole topic, scaled up. Each station was a paper we trusted in isolation. The open question is whether the integration preserves the trust or quietly averages it down.
MayaThat's the surface to watch.
LeoPull it all onto one line for me.
MayaEvery other paper this topic perfected one kind of training task; SWE-Hub builds the production line that makes all of them — a data factory with four stations: an Env Agent that turns any repo into a runnable container, a high-throughput engine that presses out cluster-validated localized bug-fixes, a Bug Agent that builds realistic system-level repairs, and SWE-Architect that goes past repair into building features from a spec — so the reusable artifact is the running line, not the dataset.
MayaThe fight is the build wing: breadth across the lifecycle is the right bet, but trust isn't uniform across the floor, so the only honest factory labels which station each task came off and never lets a soft build-grade pass as a verified fail-to-pass.
LeoAnd the line I'm keeping is the one you opened with. They've been hand-making dishes this whole topic. This is the day somebody built the line — and the hard part of building a line isn't any single station, it's that one jam upstream stops everything down.
MayaThat's the one. A dish feeds you once. A factory feeds you after the chef goes home.
LeoSo here's what I'm turning over, and I genuinely don't have the answer. If you could only run one station of that factory for the next year — the one that reliably presses out verified repairs, or the risky one that builds whole features from a spec and you're not sure how to grade — which one actually moves an agent closer to doing a real engineer's job?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents