Subscribe
Transcript
Leo— no, I'm not letting that number go by quietly. Twelve percent. The best coding agent money can rent, turned loose on a real shipping iOS app, and it clears twelve out of a hundred tasks. That's not a benchmark, Maya, that's an obituary.
MayaSee, you're reading it as a verdict on the agents. I read it as a verdict on every other benchmark.
LeoSame number, opposite story. Walk me to your side, then, because twelve looks like failure from where I'm standing.
MayaBecause of what they measured. Not a toy repo, not a fenced gym — a production iOS codebase, hundreds of thousands of lines, Swift and Objective-C tangled together the way real apps actually are. And the task isn't "here's a failing test, fix it." It's "here's the product spec, here's the Figma mockup of the screen, build the feature." Every other episode built a place to train. This one builds the place to measure — and the measurement comes back brutal.
LeoTwelve. Out of a hundred realistic tasks, the best setup lands twelve.
MayaTwelve. And that's the whole point of today. The low number isn't the embarrassment you're hearing — it might be the first honest one.
LeoOrient me first, then. Every episode this whole topic, the move was the same — find the lever that drags the number up, like Nemotron-Terminal manufacturing terminal tasks synthetically and walking the same model from three percent to twenty-seven. Where does today turn?
MayaIt turns all the way around. Nine episodes we asked: what lever moves the number up? Today we stop pulling levers and ask: what does the number even mean? This whole topic built gyms — places to practice. SWE-Bench Mobile builds the final exam, and it's an exam nobody's been studying for.
LeoThe exam, not the gym.
MayaThe exam, not the gym. And it's set in the one room agentic-coding research mostly walked past — mobile. The paper's question is right there in the title, basically: can these agents develop industry-level mobile applications? The answer, measured honestly, is "barely."
LeoOkay, but I want to be careful, because "twelve percent, agents are bad" is a cheap headline and we don't do cheap. What's in a task here? Why is mobile harder than the SWE-bench Verified everyone quotes?
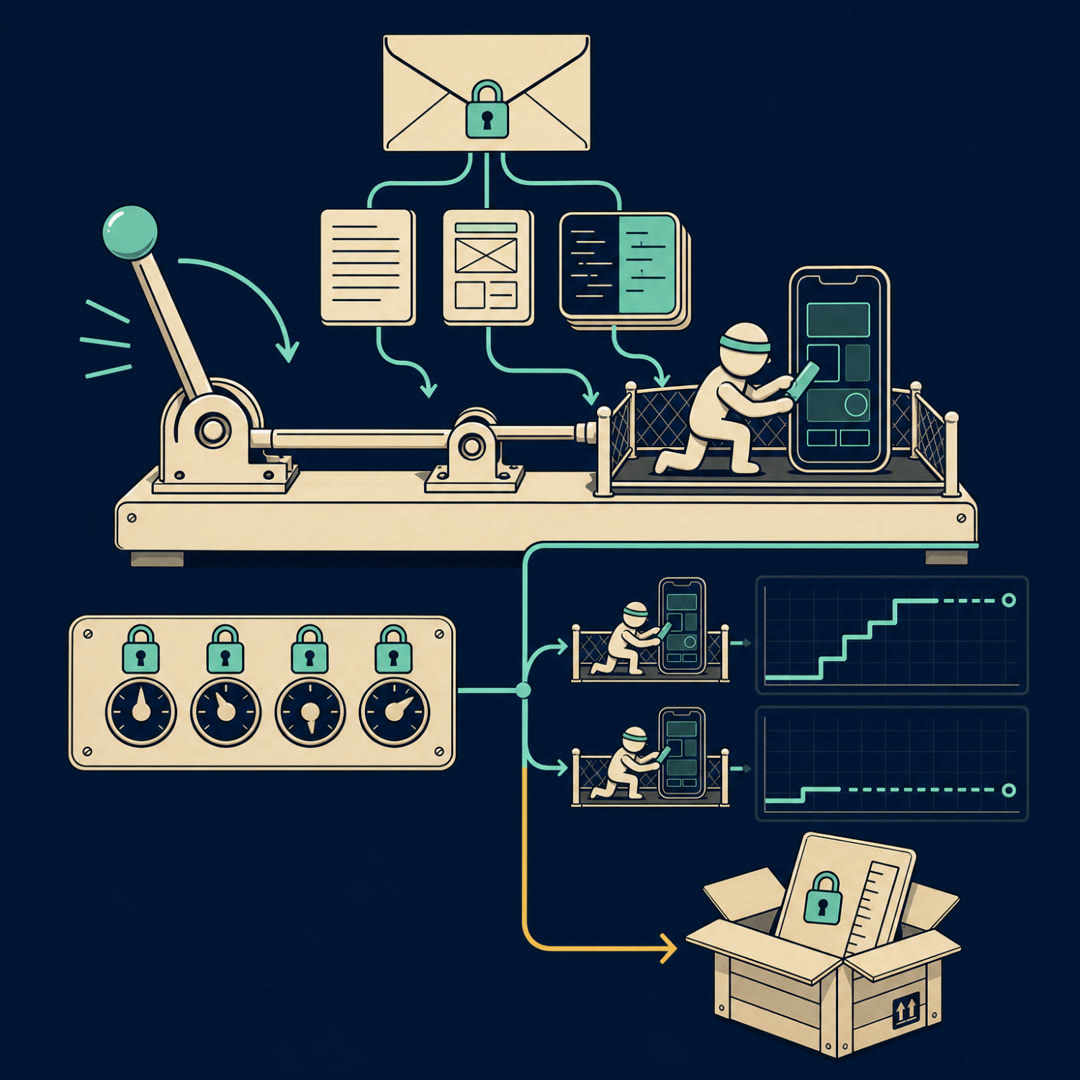
MayaGood — let's name what the task actually hands the agent. Think of it as a job packet, the same packet a real iOS engineer gets on a Monday.
LeoSo what's inside it?
MayaStart with the written product spec — a P-R-D, product requirements document. Prose. "When the user taps here, this happens, with this edge case." Then alongside it, a Figma design — the visual mockup of the screen, pixels and layout, not code. And underneath both of those, the codebase itself: that big mixed Swift and Objective-C app you have to slot the feature into without breaking the rest.
LeoStop on the second one. Figma. So the agent has to read a picture and turn it into a layout.
MayaThat's the multimodal jump that breaks the old benchmark mold. SWE-bench Verified is text in, text out — issue, code, patch. Here the spec is partly visual. The agent reads a design image and a prose doc and has to reconcile them into working UI. That's not a thing the training gyms we covered ever produced.
LeoAnd the grading? On Verified it's hidden tests — run them, pass or fail, clean bit. What grades "did you build the screen the Figma showed"?
MayaComprehensive test suites — the tasks come from a real codebase that already had real tests, and they hold those back as the hidden check, same fail-to-pass logic this whole topic leaned on. So the spine of grading is familiar: did the held-out tests go green. But the road to green is much longer, because before any test runs, the project has to actually build — the toolchain, the dependencies, the simulator — and a mobile build is a tall, brittle stack.
LeoSo there's a failure mode before reasoning even starts. A perfect feature still scores zero if the thing won't compile in the simulator.
MayaExactly that — the environment alone is a wall. SWE-bench Verified repos basically run; getting an industrial iOS app to build and test reliably is itself the hard infrastructure the authors had to solve to even have a benchmark.
LeoWhich is the quiet thing I want flagged. Building this is the same engineering all those gym papers did — make a real codebase executable, hold back trustworthy tests — except aimed at scoring, not training. Built like a gym; it just never lets you practice on it.
MayaRight — same machinery, opposite job.
MayaAnd there's a deliberate reason you can't practice on it. They run it as a hosted challenge. You don't get the test set. You submit your agent, they grade it on their servers.
LeoContamination defense. Because the second a benchmark's tasks leak onto the public internet, the next model trained on the internet has seen the answers, and the score stops meaning anything.
MayaThe contamination ghost we kept naming all topic — here it's the design constraint. A training gym wants to be public so everyone can train on it; an exam has to stay sealed or it's worthless. Opposite incentives, and this sits firmly on the exam side.
LeoOkay. So we've got a hard, sealed, multimodal, real-app exam, and the best score is twelve. Now give me the finding that actually surprised you, because "agents struggle" isn't it.
MayaHere's the one that made me re-read it. They tested twenty-two configurations — four coding agents, several models each. Cursor, Codex, Claude Code, and one open-source agent, OpenCode. And the same model, dropped into different agents, swung by up to six times in score.
LeoWait. Six times? Same brain, same weights — and which harness you wrap it in moves the score six-fold?
MayaSix-fold. And one more that cuts against every instinct: simpler prompting strategies beat the elaborate ones — by around seven percent. The fancy multi-step prompt scaffolds lost to the plain ones.
LeoOkay, so those two facts pull in opposite directions, and everyone's going to grab the one that flatters their —
Maya— their own team, right. So let's not let either of us do that. Let's stage it properly. Pick your side.
LeoI'll take model capability is the ceiling. Sharpest form: twelve percent is a reasoning and perception gap, not a plumbing gap. The agent can't reliably read a Figma design, can't hold a quarter-million-line Swift-and-Objective-C codebase in its head, can't reason across that much context. That's the model's job, and the model isn't there yet.
MayaThen what's the six-times variation worth?
LeoThat? That's just better and worse wrappers around the same limited brain — reshuffling deck chairs. The ceiling is set by the model, full stop. Build a smarter model and twelve becomes forty. Tinker with prompts and you're fighting over crumbs.
MayaMy turn. Agent design is the lever, and the data says so louder than your story does. If the model were the ceiling, the same model couldn't move six-fold by changing the harness — it would land in roughly the same place no matter who wrapped it. It doesn't. Six times, Leo. That's not crumbs, that's most of the available score sitting in the scaffold — how the agent navigates files, manages context, recovers from a failed build, decides what to —
Leo— but six-fold of a tiny number, though. Six times two percent is twelve, and twelve is still failing. You can scaffold a weak model into "less catastrophic," you can't scaffold it into "good." The harness moves you around the basement, but the model decides which floor you're even allowed onto, and right now that floor is —
MayaThe basement. I know. I'm not going to pretend twelve is a good floor.
MayaFair hit, though — and here's where your simpler-prompts finding actually helps me, not you. If raw model reasoning were the bottleneck, more elaborate prompting — more planning steps, more chain-of-thought scaffolding — should help, squeeze more out of the brain.
MayaInstead the plain prompts win by seven percent. That says the elaborate scaffolds were getting in the model's way. Agent design isn't just a multiplier — it's something you can actively do wrong. Which is the strongest possible proof the design layer is real and load-bearing.
LeoOkay. I'll give you that one cleanly, because it's a good point and I don't want to pretend it isn't. Complex prompting losing means the harness has real effects in both directions. The scaffold is genuinely a lever, not a cosmetic wrapper. Concede.
MayaAnd I'll give you yours, because you're right that I was overreaching. Six-fold of the floor is still the floor. No harness on today's models clears industry-level. The model absolutely sets the ceiling — I can't scaffold a twelve into a sixty.
LeoSo where does it actually settle? Say it so it holds.
MayaIt settles into two jobs, not one winner. The model sets the ceiling — how high the score could ever go. The agent design decides how much of that ceiling you actually reach — and you can squander most of it with a clumsy or over-engineered harness. Right now both are the problem: the ceiling is low and most agents leave half of it on the table.
LeoAnd the thing that would settle the rest is the exam itself. The hosted challenge. As models get smarter the ceiling lifts, and we get to watch — on a sealed test nobody trained on — whether scaffolding still buys six-fold or whether a strong-enough model makes the harness stop mattering. The benchmark is the referee that keeps both of us honest over time.
MayaThat's the resolution. Neither of us wins on a slide. The board wins, because it's the one number nobody can fake.
LeoGive me the spine. One breath.
MayaA real production iOS app, turned into a sealed exam: prose spec plus Figma design plus a giant mixed codebase, graded by held-out tests after the thing actually builds. Best agent today scores twelve. Same model swings six-fold across harnesses, and simpler prompts beat fancy ones — so the model sets the ceiling and the agent design decides how much you reach. The exam stays locked so the score stays real.
LeoAnd there's a result hiding in your spine I want said out loud, because it's the most useful sentence for anyone shipping this stuff. Commercial agents beat the open-source one. Consistently.
MayaThey did — and for once that isn't a knock on open weights, it's a credit to scaffolding. The commercial agents poured engineering into exactly the layer we just argued is load-bearing: context management, file navigation, build recovery. The open model isn't a worse brain. It's wearing a thinner harness.
LeoSo the topic's closing joke writes itself. Nine episodes proving the environment and the data matter more than the weights — and the capstone exam proves the harness does too. Nobody in this story is the model.
MayaThe model keeps not being the hero. Back at the start we said the number is a trophy and the artifact is the factory. Mobile adds the other half: the trophy is low and it's not the model's fault alone.
LeoLet me push on the gap, though, because twelve percent could mean two very different things and I don't want us to leave it fuzzy. Is the gap "these agents are dumb," or is it "industry-level work is just harder than any benchmark admitted before"?
MayaThe second, mostly — and that's the paper's real contribution. Every earlier benchmark made the task legible: clean issue, isolated repo, text in, text out. This one refuses to clean it up. Multimodal spec to interpret, a codebase too big to read, a build that fights you, two languages. The twelve isn't saying agents are worthless — it's saying the exam finally looks like the job, and against the real job, we're at the start.
LeoWhich reframes every score we quoted all topic. The thirty-somethings on SWE-bench Verified, the fifty-ones on the hybrid verifier — real, but scores on tasks shaped to be gradable.
MayaThe tail wagging the dog, the thing we flagged in the factory episode. Benchmarks drift toward what's easy to score. SWE-Bench Mobile drags the dog back: score the work that's actually valuable — build a real feature in a real app from a real spec — even though it's miserable to grade. The low number isn't failure. It's the first honest measurement.
LeoSo the artifact this paper leaves the field isn't a model and isn't a training set. It's a yardstick — held-out, multimodal, real-app, that the next three years of agents get measured against. Sealed, so it can't be gamed; real, so it can't be cheated up.
MayaEvery gym this topic built was about climbing. This is the one that tells you how tall the wall really is — and it tells you mobile, the blind spot.
LeoRight. All that gym-building — the world models, the synthetic bugs, the terminal data — almost none of it pointed at the platform most software users touch every day.
MayaA whole research program optimizing for the codebases researchers find convenient, and the most-used software surface on earth barely in the training picture. SWE-Bench Mobile is partly just pointing at that empty seat.
LeoLimitation, before we close — because we always name where not to trust it. It's one production iOS app. One company's code, one style, one set of conventions.
MayaA real limit. Twelve percent on this app isn't twelve percent on mobile in general — it's a single deep probe, not a survey. And iOS only, this round; Android's a different toolchain, different fights. Read it as the first real datapoint on industrial mobile, not the last word — which is exactly what a topic about reading improvement studies should end on.
LeoThe honest scoreboard for the work that actually ships.
MayaSo here's what I'd leave you sitting with. If the score that finally matters — real feature, real app, real spec, sealed grading — comes back at twelve, and changing the harness around a fixed model swings it six-fold: when you read the next big leap on a coding benchmark, how will you tell whether the model genuinely got smarter, or whether someone just built a better harness around the same brain?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents