Subscribe
Transcript
MayaStart with an arithmetic problem, not a coding one. The whole public world has — give or take — a few thousand real, runnable bug-fixing tasks. Everybody training a coding agent is fishing from the same small pond. Now picture someone walking up and saying: forget catching real fish. I'll manufacture fifty thousand of them, from a hundred-plus codebases.
LeoFifty thousand against a pond of a couple thousand. That's not a bigger net, that's a fish factory.
MayaThat's the move. And the question that should itch you immediately is the one we'll spend the episode on: are factory fish the same fish?
LeoRight — a number that big only matters if the things you made are the things you wanted. Fifty thousand of the wrong task teaches fifty thousand wrong lessons.
MayaHold that exact worry. It's the spine of the whole thing.
LeoQuick orient, though. Last time we were standing at SWE-Gym — a cage of a couple thousand runnable bug tasks, and the fight was over two levers, fine-tuning the agent versus training a scout to pick its best swing.
MayaAnd today's source picks up the part SWE-Gym left on the table. SWE-Gym collected real tasks and got to a couple thousand. SWE-smith asks a different question — not how do I find more tasks, but how do I make them. Same lineage, by the way. This is the SWE-bench crew, John Yang and his collaborators, the people who built the original benchmark, now turning around to mass-produce its training food.
LeoThe people who set the exam are now running the cram school. [chuckle] Okay. So how do you manufacture a bug task? To me a "bug" is a thing that happens to you, not a thing you order by the gross.
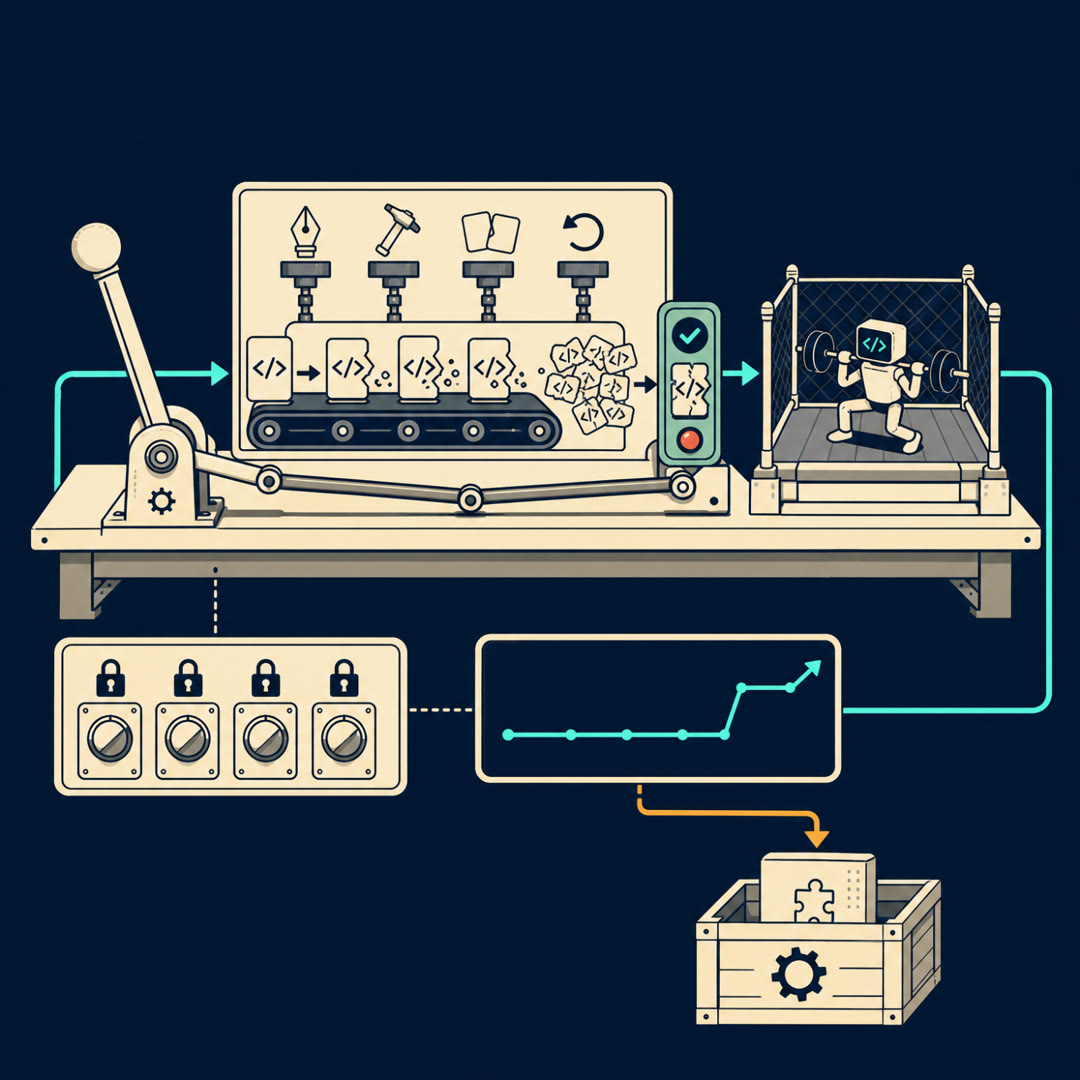
MayaThat's the inversion, and it's clever once it clicks. A bug task, stripped down, is just: working code, plus a small wound that makes a test go red, plus a way to check whether the wound got healed. SWE-smith's insight is — you don't need to wait for the wound. You can inflict it. Take code that passes its tests, break it on purpose, and now you've got a task: here's a repo, here's a failing test, fix it.
LeoHuh. Run the bug backwards.
MayaRun the bug backwards. And here's the part that surprised me — there isn't one way they break code. There are four. I want to walk them like four stations on a factory floor, because they're not interchangeable, and the differences are the whole debate later.
LeoName them. I'll keep score on which ones I trust.
MayaFirst station — the Rewrite Bench. You point a language model at one function and say: rewrite this from scratch, and introduce a flaw while you're at it. The model hands back a plausible-looking version that's subtly wrong.
LeoSo the saboteur is itself an LLM. A model writes the bug another model has to find.
MayaAnd that symmetry is going to matter. Second station, the Wrecking Crew. No language model at all. This one works on the code's skeleton directly — the syntax tree — and applies blunt, mechanical edits. Delete an `if` block. Flip a comparison. Drop a loop. A whole toolkit of little deterministic vandalisms.
LeoCheap and infinite.
MayaCheap, infinite, and dumb on purpose — no creativity, just structural damage. Third station, the Splicer. Take bugs you've already made and validated, and combine them — two wounds in the same file, three across one module — so the agent fixes a tangle, not a single thread.
LeoCompound fractures, so the tasks aren't too clean.
MayaExactly. And the fourth is the different animal — the Time Machine. Find a real pull request, a real human fix that closed a real issue, and undo it. Revert the human's change file by file, and the repo is back to its broken state with the genuine issue text attached.
LeoWait — okay, stop, because that fourth one is not like the other three. The first three are invented bugs. That last one is a real bug, just rewound. Those are completely different provenances and you slid them into the same list.
MayaI did, and you catching that is the episode. Hold it for two minutes, because I want the rest of the machine in place before we fight about it — and we are going to fight about it.
LeoFine. Finish the floor.
MayaSo whichever station made the wound, there's a gate every task has to pass, and it's the honest part. They run the tests. If the broken version doesn't actually turn a green test red, it's discarded. The only instances that survive are ones where something concrete clicks from pass to fail.
LeoSo the label's real even when the bug is fake. The breakage is verified by execution, not by somebody's say-so.
MayaThat's the load-bearing distinction. The origin of the bug can be synthetic. The failure is never synthetic — a real test really goes red. That's what keeps these from being fan-fiction.
LeoAlright, that earns my attention back. But manufacturing at this scale usually drowns you in storage. Last paper, every task basically needed its own built environment. Fifty thousand environments would be a server farm.
MayaAnd this is the quiet engineering win nobody puts on the poster. The old way — one frozen environment per task — runs you into terabytes fast, because every instance hauls its own Docker image. SWE-smith flips the unit: one environment per repository, not per task.
LeoSay why that works.
MayaBecause every bug they inject into a given repo lives in the same codebase with the same dependencies. Only a few lines of code change. So all thousand bugs you forge from one project share a single environment. A hundred-plus repos, two hundred-fifty-plus environments — and fifty thousand tasks ride on top.
LeoOh — that's the actual unlock.
MayaThe scale story sounds like "fifty thousand tasks." The enabling story is "we stopped paying per task and started paying per repo." Cheap enough that fifty thousand stops being absurd.
LeoOkay. Now I want the fight, because I've been holding it. You've got two families of bug under one roof. Let me draw the line hard and you take the other side.
MayaTake your side first. Make it strong.
LeoMy side: the invented bugs are a liability dressed up as scale. The Wrecking Crew deletes an `if` block — the test goes red, but that's not a bug a person would ever ship. No engineer accidentally removes a whole conditional.
MayaSo the mechanical ones don't look like real mistakes.
LeoAnd the LM rewrite is worse in a sneaky way: a model invented that bug, so it carries a model's texture — the mistakes an LLM makes, not the ones a tired human makes late on a Friday. Train on forty-nine thousand of those and you've taught the agent to fix machine-shaped bugs. The real world hands it human-shaped ones.
MayaMy turn to defend it.
LeoAlright. [chuckle] Go.
MayaThe synthetic-bug defense is stronger than it sounds. The failure is real even when the origin isn't — every one passed an actual test gate, so the agent always practices genuine red-to-green repair.
LeoFine, but practicing real repair on fake wounds is still fake wounds.
MayaVariety beats authenticity at volume: a human-curated set is a few thousand bugs from eleven repos, narrow; fifty thousand injected bugs across a hundred-plus repos covers an enormous spread of code shapes the agent will actually meet. And the killer — you couldn't get human-shaped ones at this scale if you wanted to. They don't exist in sufficient number. The real choice isn't authentic-versus-synthetic. It's synthetic-at-scale versus almost-nothing.
Leo"Almost nothing" is doing a lot of lifting. Because the fourth station exists. The Time Machine is the human-shaped bug at scale — reverted real PRs. So why not make fifty thousand of those and skip the invented ones entirely?
Maya...And that's the concession I have to make. You're right that PR-mirroring is the most authentic source in the box. If I could get fifty thousand reverted-PR tasks, I might not bother with the Wrecking Crew at all.
LeoSo I win.
MayaYou win that point and then the pond drains on you. Reverting real PRs runs straight back into the original scarcity — there are only so many repositories with clean, issue-linked, single-purpose pull requests you can cleanly rewind. PR-mirroring is the highest-quality station and the lowest-throughput one. The invented bugs aren't there because they're better. They're there because they're the only thing that multiplies.
LeoHuh. So it's not quality versus scale as a slogan — it's a portfolio. The realistic-but-scarce source sets the ceiling on quality; the invented-but-infinite sources provide the volume underneath it.
MayaThat's the resolution, and it's not a draw — it's a division of labor. And here's what would settle the rest, the thing the paper can't fully answer alone: does an agent trained mostly on invented bugs actually transfer to the human-shaped exam? You measure that one way — train on the factory, test on the real benchmark, watch whether the score holds.
LeoWhich is the whole reason the benchmark stays sealed. You don't get to peek. Train synthetic, test real, see if the bridge holds your weight.
MayaAnd it does — that's the punchline. They trained an open agent model on this manufactured data and put it on the real SWE-bench Verified exam. Roughly two in five issues resolved. State of the art for an open model at the time. The factory fish swam in the real ocean.
LeoTwo in five from synthetic. That's the number that ends the argument.
MayaIt ends one argument. It proves invented bugs transfer well enough to top the open-source board. It does not prove they'd transfer as well as fifty thousand real ones would, if those existed — that comparison can't be run, because the real ones don't exist. So we're left honest: synthetic clears the bar we can measure, and the bar we'd love to measure is unbuildable.
LeoLet me walk our running bug through the factory, because I want it concrete. The agent we've followed all topic — real repo, a failing test, a fix that has to actually run. Where does SWE-smith touch it?
MayaOn the training side, not the test side. Before this, that agent learned from a couple thousand real repair examples. After SWE-smith, tens of thousands — most of them wounds some station inflicted on healthy code, each one verified to really break a test. The agent that walks up to your dropped-bug ticket has simply practiced repair vastly more times, across a much wider spread of repositories, than it ever could on real tasks alone.
LeoSo the Monday consequence isn't a new trick for the agent. The training menu went from thin à la carte to all-you-can-eat — and the bill stayed small because of the one-image-per-repo thing.
MayaVolume that used to be impossible, made routine.
LeoThe topic trained me to ask this — what's the reusable artifact? Not the model. The thing that outlasts it.
MayaThe pipeline. The model they trained ages out in a year. But "point me at any Python repo and I'll stand up its environment and forge thousands of verified tasks" — that's a machine that keeps producing. SWE-Gym handed you a fixed cage. SWE-smith hands you the blueprint for building cages — point it at a new codebase tomorrow and it makes you a new gym by Friday.
LeoA bug foundry, not a bug collection.
MayaAnd that reframes scarcity permanently. The bottleneck was never "the world doesn't have enough bugs." It was "we couldn't manufacture verified ones cheaply." Solve the manufacturing and the pond stops being the constraint.
LeoLimitations, though — where's the bill on this one? Because "forge infinite tasks" sounds suspiciously free.
MayaTwo real ones. The provenance question we fought doesn't close — the bulk of the data is still invented bugs, and we don't know how much of the agent's skill is "fix real bugs" versus "recognize machine-injected ones." The transfer score is encouraging, not conclusive. And the one that haunts the whole topic: train on a hundred-plus public repos, test on a public benchmark, and you have to police overlap obsessively, or you've taught the agent to remember instead of reason.
LeoContamination. Same ghost as last episode — louder here, because the more tasks you manufacture, the more public code you've ingested.
MayaExactly the surface to watch.
LeoSay the spine back to me in one breath.
MayaThe pond of real bug tasks is tiny. SWE-smith manufactures fifty thousand from a hundred-plus repos by breaking working code four ways — language-model rewrites, mechanical syntax-tree edits, combined wounds, and reverted real pull requests — keeping only the breaks a real test confirms, and sharing one environment per repository so the scale stays affordable. Train an open agent on that flood and it tops the open-source board on the real exam.
LeoAnd the line I'm keeping is yours from the fight — the realistic source sets the ceiling, the infinite sources fill the room.
MayaThat's the one. The benchmark gave you a couple thousand bugs and called it a dataset. SWE-smith gave you a factory and called it a method — and the factory is the part you get to keep.
LeoSo here's what I'm turning over. If you can manufacture a near-infinite supply of verified-but-invented training tasks, the constraint stops being how many tasks you have — it becomes how faithfully your invented bugs resemble the real ones your agent will face. So where would you spend the next year: building a bigger factory, or building a better measuring stick for whether the factory's output actually looks like the real world?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents