Subscribe
Transcript
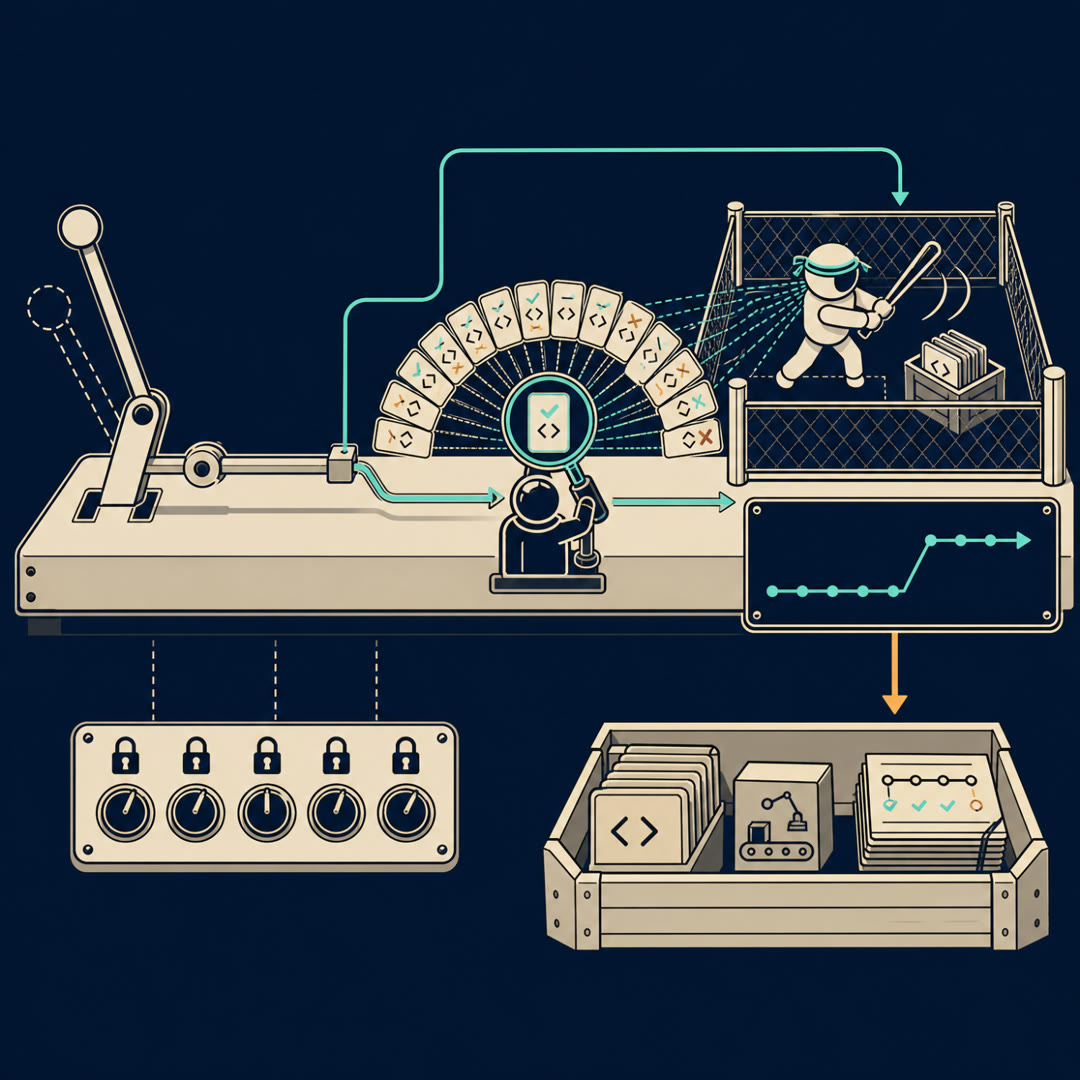
MayaHere's a setup I want you to sit with. One coding agent, one bug, sixteen tries. Not one attempt and done — the agent takes a swing at the same ticket sixteen separate times, and sixteen different patches come back. Some compile and fail. Some break things. A couple actually fix it. Now: out of those sixteen, how does the team pick the one to ship?
LeoAnd they can't run the hidden test to find out. That's the whole catch — if they could just run the real check, there's no problem.
MayaThat's the corner. Hidden test is locked. They've got sixteen sealed envelopes and they have to bet on one without opening it.
LeoSo the obvious move is, what — pick the one the agent felt most confident about?
MayaThat's the obvious move and it's mediocre. The agent's confidence is roughly noise. What this study does instead is train a second model whose entire job is to look at a finished attempt and guess: did this one actually work? A judge for the sixteen envelopes.
LeoA grader that never saw the answer key, trained to smell a winner.
MayaAnd the headline of the whole episode is that the grader is where a chunk of the gain lives. Not a smarter agent — a smarter way to pick among a dumber agent's tries.
LeoOkay, that's a hook.
MayaQuick orient first. Last episode we had the world model on the workbench — we autopsied where its in-head simulation breaks. We were inside the agent's head.
LeoToday we back all the way out. No internal simulation, no traces of variable state. Just: agent goes into a real repo, flails, comes out with a patch. Did it work, yes or no.
MayaRight. And the source is a paper called SWE-Gym — training software-engineering agents and verifiers. The "and" is the episode. Most studies in this topic pull one lever. This one pulls two from the same bench, and the interesting fight is which one mattered.
LeoTwo levers. Hold that, because I'm going to want to separate them. But start me on the gym itself. What did they actually build?
MayaSo — remember the worry we had way back, that there are only a few thousand real, runnable bug tasks in the whole public world? SWE-Gym is somebody going and assembling a real one of those. Real Python repositories, real issues, and — this is the load-bearing word — executable.
LeoDefine executable here, because that word does a lot of quiet work.
MayaIt means every task ships with a codebase you can actually run, the dependencies already stood up, the unit tests wired in, and the problem written out in plain English. Twenty-four hundred-odd of these. Not descriptions of bugs — bugs you can attempt, where something concrete clicks at the end and says pass or fail.
LeoSo it's a batting cage, not a photo album.
MayaThat's exactly the line. A pile of GitHub issues is a photo album — you can look, you can't swing. The gym is the cage: the agent steps in, takes the pitch, and the machine tells it whether it connected.
LeoAnd without the cage you can't do the thing this paper does, which is — let me guess — let the agent swing thousands of times and keep the swings.
MayaNow you're ahead of me. Yeah. The agent runs the tasks over and over through a harness — they use OpenHands, the open agent scaffolding — and every attempt leaves a full trajectory. The searching, the file opens, the commands, the failed test, the retry, the final diff. And crucially, the gym can stamp each one: resolved, or not.
LeoBecause the test actually runs. So the label's free.
MayaThe label's free and it's honest. Nobody hand-graded these. The environment graded them. Which gives you a mountain of trajectories, each tagged with ground truth.
LeoOkay, here's where I plant the flag, because this is the part everyone fast-forwards. You've got this mountain of labeled tries. There are two completely different things you can do with it, and the paper does both, and I do not want them blurred.
MayaLay them out.
LeoLever one: take the trajectories where the agent succeeded and fine-tune the agent on those. Teach it, by example, "this is what a winning attempt looks like." You're changing the athlete.
MayaThe agent gets better at swinging.
LeoLever two: take all of them — wins and losses — and train a separate model to tell them apart. You're not touching the agent at all. You're building a scout who watches finished swings and calls the homers. So which one moved the number?
MayaAnd this is the genuine split in the paper, so let's actually fight it rather than narrate it. I'll take the agent side. You take the verifier side.
LeoDeal. Go.
MayaThe agent side is the honest, durable improvement. Fine-tune the model on its own successful runs and the base capability goes up — they report gains up to around nineteen points absolute on the hard benchmark, before any clever selection. That's the agent genuinely getting better at software engineering. It's not a trick. The athlete is stronger when it leaves the gym than when it walked in, full stop.
LeoNineteen points is real, I'm not waving it off. But here's my problem with crowning the agent. Fine-tuning a single attempt has a ceiling, and you hit it fast — there are only so many good trajectories, and the agent's still going to whiff most tickets on the first try. The verifier is where it gets interesting, because it doesn't fix the agent — it fixes the picking.
MayaMake the case.
LeoThe system that hits state of the art for open-weight agents — the thirty-two on Verified, the twenty-six on Lite — that is not the fine-tuned agent alone. That's the agent taking many swings and the verifier choosing among them. Best of sixteen. The agent stays mediocre per-swing. The verifier turns sixteen mediocre swings into one good answer. The lift from picking beats the lift from a single better attempt.
MayaCareful, though — you're standing on the agent to make that point. The verifier's choosing among sixteen swings from the fine-tuned agent. A scout picking the best of sixteen terrible swings still ships a terrible patch. You need the athlete good enough that the right answer is in the sixteen for the scout to find it.
Leo...Yeah. That's fair. The verifier can only select what the agent generated. If the fix never appears in any of the sixteen, no grader on earth pulls it out.
MayaSo it's not agent or verifier.
LeoNo. I'll move. It's a relay. The agent's job is to make sure a correct patch lands somewhere in the batch. The verifier's job is to find it. And here's where I land that's not a draw — because both jobs matter, but they scale differently, and that's the actual finding.
MayaSay it.
LeoMaking the agent better is bounded by how many good trajectories you can collect. But the verifier path scales on a second axis the agent path doesn't touch — how many times you let it try at test time. And the paper's sharpest observation is that neither curve has flattened. More training trajectories: still climbing. More swings per ticket at inference: still climbing.
MayaThat's the part that should make a training lead sit up. Most levers in this field hit a wall — you double the data, you get a sliver. Here, both knobs are still paying out. They didn't find the ceiling. They ran out of budget before they ran out of gains.
LeoSo the resolution is: it's two levers, they compound, and the new one — pay compute at test time, let the verifier pick — is the one with room left.
MayaAnd notice what the verifier really is, mechanically, because it's subtle. It's outcome-based. It doesn't grade the agent's reasoning step by step, doesn't check if the search was smart. It looks at a whole finished trajectory and predicts one thing: would the hidden test pass?
LeoIt's learning to imitate the locked test from the outside.
MayaThat's the cleanest way to say it. The hidden test is sealed, so they train a model to approximate the verdict the sealed test would give. It's a stand-in judge — wrong sometimes, but right often enough that best-of-sixteen with it crushes best-of-sixteen with a coin flip.
LeoHuh. A learned echo of the test you're not allowed to run.
MayaNow walk our ticket through it, because this is where it gets concrete. The dropped-bug ticket — failing test, a few files, a fix that has to run.
LeoRight. The agent we've followed all topic. Pre-SWE-Gym, it gets one swing and one swing only.
MayaOne swing, ship it, pray. After SWE-Gym, two things changed. The agent itself was fine-tuned on a heap of successful repair runs, so its single swing is better. And then at decision time, you don't take one swing — you take sixteen, and the verifier ranks them, and you ship its top pick.
LeoSo the Monday change is almost a workflow change, not a model change. Stop trusting the first patch. Generate a batch, score the batch, ship the winner.
MayaThat's the practitioner takeaway, and it's cheaper than it sounds — you're spending inference compute, not retraining. Sixteen tries and a scout can beat one try from a model that cost ten times more to build.
LeoLet me push on the artifact, though, because the topic trained me to. What's the reusable thing here? The agent? The verifier?
MayaNeither, and this is the satisfying part. The most reusable output is the gym plus the labeled trajectories. Twenty-four hundred executable tasks, and a mountain of attempts each stamped resolved-or-not by a real test. That's not a model you have to trust — it's raw material anybody can retrain on. The agent ages out. The athlete moves on.
LeoThe cage stays bolted to the floor.
MayaAnd the trajectories are double-duty, which is the elegant bit. The successful ones train the agent. All of them — wins and losses together — train the verifier. The losses aren't waste. The verifier literally can't learn what failure looks like without them.
LeoYou need the strikeouts to teach the scout. Throw the strikeouts away and your grader's only ever seen home runs — it'll call everything a home run.
MayaThe failures earn their keep twice over here. Not as a lesson the agent imitates — as the negative half a judge needs to judge.
LeoAlright, limitations. Where does this stop being free lunch? Because "just take sixteen swings" has a bill attached.
MayaIt does, and the paper's honest about the shape of it. Best-of-N is linear in compute — sixteen swings cost roughly sixteen times one swing. That's fine in a lab measuring a benchmark. In production, on every ticket, all day, that's a real invoice.
LeoAnd the verifier's a stand-in, not the real test. So it has its own error rate — it'll sometimes crown a patch that doesn't actually fix the bug.
MayaBoth true. The verifier is an approximation of a sealed test, so it inherits a gap. And there's the quieter contamination worry that haunts everything in this topic — train on public repositories, evaluate on a public benchmark, and you have to watch that the agent didn't just recognize the bug.
LeoBut the scaling point survives all of that?
MayaThat's what makes it a real finding rather than a one-off score. Even granting the costs, the two curves were still rising. The honest version is: we don't yet know how good this gets, because nobody's hit the wall. The ceiling's an open question, not a reported number.
LeoLet me say the spine back in one breath. SWE-Gym is a cage of twenty-four hundred runnable bug tasks. Run an agent in it and you get trajectories the environment can grade for free. The wins fine-tune the agent — one lever. Every attempt, win or loss, trains an outcome verifier that picks the best of many swings at test time — the second lever. And both still scale.
MayaThat's it. And the line I'd leave you with: the agent is the swing, but the verifier is the eye — and this topic keeps teaching the same lesson in new clothes. The reusable thing was never the athlete. It was the cage, and the record of every swing taken in it.
LeoHere's what I'm turning over, then. If a learned grader can pick a winner out of sixteen tries better than the agent can pick its own — what does that tell you about where the real bottleneck in coding agents actually is: generating a good answer, or recognizing one?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents