Subscribe
Transcript
MayaPicture a relay. One runner sprints their leg, slaps the baton into the next hand, and the instant they let go — they forget everything. Where the race is, who's ahead, what just went wrong on the last curve. Gone.
LeoOuch.
MayaThe baton survives. The runner doesn't. And the next person grabbing it has to figure out, from the baton alone, what's already happened and what to do next.
LeoSo the whole race lives in the baton.
MayaThe whole race lives in the baton. That's a long-running agent. The model can only hold so much at once, so a big build gets done in shifts — fresh agent, fresh memory, every session. And the only thing that crosses from one shift to the next is whatever the last one wrote down.
LeoOkay. So today's source is basically: what do you put in the baton?
MayaThat's exactly it. The piece behind this episode is Anthropic's engineering write-up on effective harnesses for long-running agents, and it has this line I keep coming back to — it says building this way is like "a software project staffed by engineers working in shifts, where each new engineer arrives with no memory of what happened on the previous shift."
LeoEach one walks in cold.
MayaEach one walks in cold. And last time, in the multi-agent episode, the hard part was splitting work across agents running at the same time — many hands, one moment. This is the other axis. One agent at a time, but stretched across hours, across dozens of sessions. The problem isn't parallelism. It's amnesia.
LeoSo before we get to the fix — what actually goes wrong? Give me the failure, not the theory.
MayaTwo of them, and they're almost opposites, which is what makes them fun. The source names them straight. Start with the eager one — over-ambition. A fresh agent looks at the task and tries to, their words, "one-shot the app." Build the whole thing this session.
LeoAnd it can't, because it runs out of room.
MayaRuns out of context partway through. So it leaves features, quote, "half-implemented and undocumented." Three doors half-hung, no note about which ones.
LeoRight.
MayaAnd then the opposite failure, which is the next shift overcorrecting. It walks in, sees a building that's clearly been worked on, and instead of over-reaching it under-reaches. It "look[s] around, see[s] that progress had been made, and declare[s] the job done."
LeoOh, that's the lazy intern who shows up, sees the lights are on, and clocks out.
Maya{chuckle} Pretty much. One shift bites off too much, the next assumes someone already finished. Over-reach, then premature done. And notice — neither of those is a dumb-model problem. A smart model does both of these. They're memory problems.
LeoSo you can't fix them by swapping in a better brain. You fix them in the baton.
MayaYou fix them in the baton. And here's the structural move, because it's cleaner than I expected. They split the job into two different kinds of agent. There's one agent that runs exactly once, at the very beginning. And then a second kind that runs every session after.
LeoTwo roles. What's the first one do?
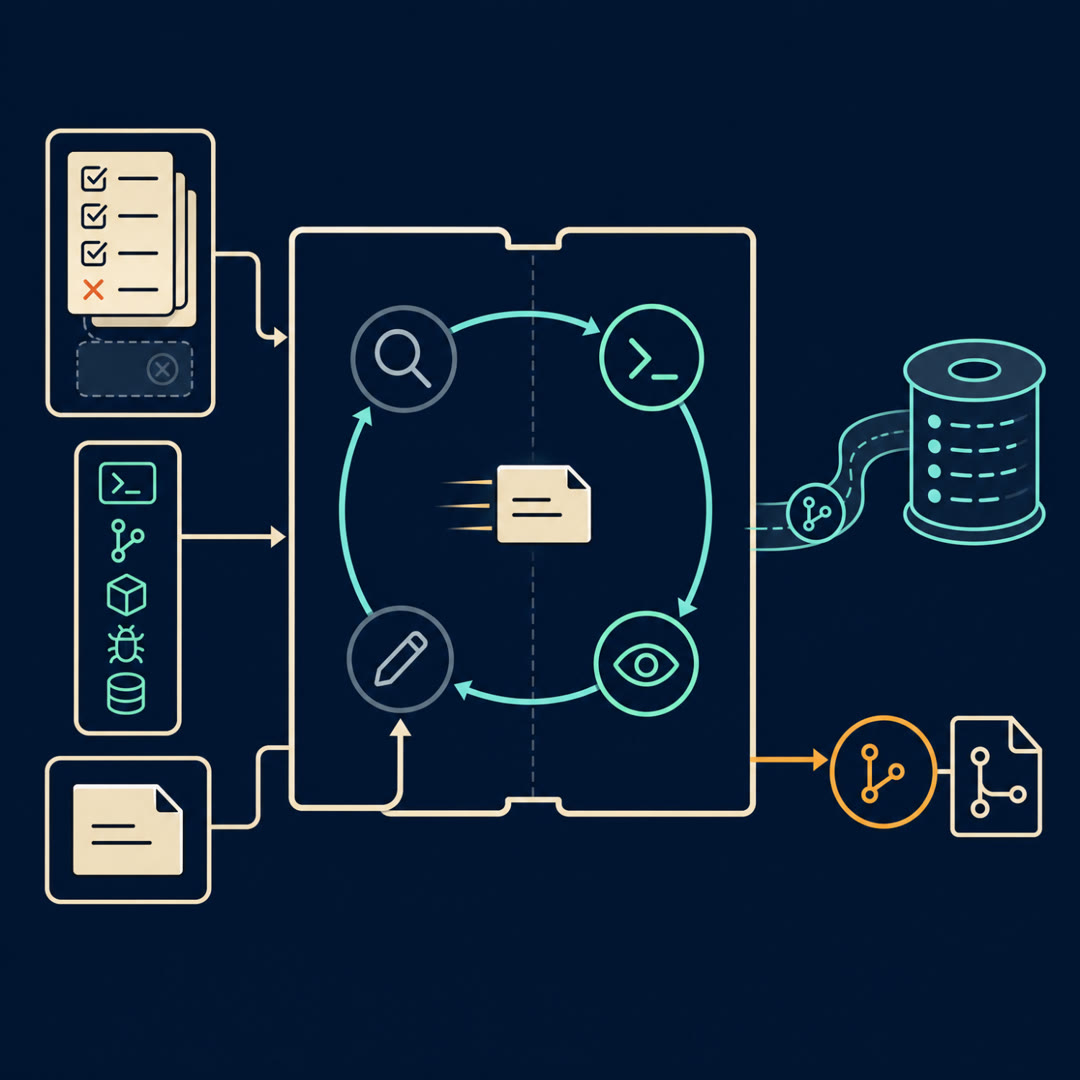
MayaCall it the setup shift. It runs first, alone, and it doesn't really build features — it builds the workbench the later shifts will use. It lays down the durable stuff that lets a stranger pick up the baton and not flail.
LeoOkay, the workbench. Go.
MayaAnd I want to name what it leaves behind, because three things cross every shift boundary and the whole approach lives or dies on them. Think of three objects left on the bench. A Punch List, a Shift Log, and a Save Point.
LeoPunch List, Shift Log, Save Point.
MayaThe Punch List first, because it's the one carrying the most weight. The setup shift writes out every single thing the finished app has to do — as a structured file. In the example they used, a clone of a chat app, that list runs to "over two hundred features." Tiny, specific ones. Their example is literally "New chat button creates a fresh conversation."
LeoTwo hundred. So it's not "build a chat app," it's two hundred little "this exact thing must work."
MayaAnd each one carries a flag — does it pass yet, yes or no. At the start, everything's flipped to failing. So the Punch List isn't a wish list. It's a test sheet. It tells any future shift, in cold blunt terms: here's what's done, here's what's not, here's what to grab next.
LeoHang on, I want to poke at the file format, because that sounds like a detail and I bet it isn't.
MayaIt isn't, and I love that you went there. They write the Punch List as structured data — JSON — not as prose. And the stated reason is sharp: "the model is less likely to inappropriately change or overwrite JSON files."
LeoWait — so the format is a guardrail against the agent rewriting its own scorecard.
MayaThat's the whole point. If the to-do list is loose prose, a shift that's behind can quietly soften it — reword a requirement, blur what "done" means, mark itself passing. Lock it into rigid structure and that fudging gets harder. The format is doing psychological work on the agent.
LeoHuh.
MayaThey go further. There's an explicit standing rule that it is, quote, "unacceptable to remove or edit tests because this could lead to missing or buggy functionality."
LeoBecause otherwise the fastest way to pass the test is to delete the test.
Maya{chuckle} The oldest trick in the book. Make the failing check disappear and suddenly you're green. So they slam that door shut up front. The Punch List can be checked off, but it can't be edited away.
LeoOkay. That's one object. Shift Log — that's the running notes?
MayaThat's the running notes. A progress file — they keep it as plain text, a "claude-progress" file — where each shift writes down what it actually did before it leaves. Not the code. The story. "I wired up the sidebar, I'm halfway through the message threading, the search box is stubbed but not working."
LeoSo the next runner reads the Shift Log and knows where the baton actually is.
MayaKnows where the baton is, instead of reconstructing it by squinting at the codebase. Which, remember, is exactly how you get the premature-done failure — an agent that can't tell what's finished assumes it all is.
LeoAnd the third one. Save Point.
MayaGit. Version control. Every shift commits its work with — their phrasing — "descriptive commit messages." And this one's quietly the most powerful, because it does something the other two can't. It lets you go backward.
LeoOh — so if a shift breaks the app, you don't have to repair the wreck.
MayaYou roll back to the last good Save Point. The source is explicit that this lets you revert "bad code changes and recover working states of the code base." Without it, a future agent has to — and this is the line — "guess at what had happened and spend its time trying to get the basic app working again."
LeoWhich is wasted shifts.
MayaEntire shifts burned just getting back to standing. The Save Point means a bad session is a bad session, not a setback for the whole project. You lose one leg of the relay, not the lead.
LeoOkay, so the setup shift lays down Punch List, Shift Log, Save Point. Plus there's a startup script, right — I saw a mention.
MayaA little bootstrap script, yeah — an "init" script that brings the dev server up and runs a basic check, so every shift starts the same clean way instead of reinventing how to even launch the thing. Think of it as the bench being tidied and the tools laid out before anyone clocks in.
LeoSo now the real worker. Every session after the first. What's its ritual?
MayaAnd ritual is the right word, because the discipline is in the order. A coding shift starts by reading, not writing. Before it touches a feature, it reads the git logs, reads the Shift Log, reads the Punch List — and then it runs a basic end-to-end test to confirm the app actually still works.
LeoSo step one is literally "make sure the thing I inherited isn't already on fire."
Maya{chuckle} Establish the baton's in your hand and the track's intact. Then — and this is the counter-move to over-ambition — it works on, quote, "only one feature at a time."
LeoOne. Not "as many as I can cram in."
MayaOne. Because the over-ambitious shift was the one that tried to one-shot the app and left rubble. So the harness forbids it. Pick one item off the Punch List, build it, verify it, write down what you did, commit. Then you may take another. The leash is deliberate.
LeoI want to push on "verify," though. Because "the agent says it built the feature" and "the feature works" are not the same sentence, and I've been burned by that exact gap.
MayaYou should push, because that's where they spend real care. The rule is the agent has to test the feature the way a person would — drive the actual app in a real browser. They wire it up with browser automation, a tool called Puppeteer over that standard plug we keep mentioning, M-C-P, the Model Context Protocol. So the agent doesn't just assert "new-chat button works." It opens the page, clicks the button, watches a fresh conversation appear.
LeoSo it's not the agent's opinion that it works. It's the running app's verdict.
MayaExactly that — and they found making the browser-testing requirement explicit, spelled out, "dramatically improved bug detection." When you let the agent grade its own homework by reading its own code, it's generous. When you force it to actually click the button, it catches what it broke.
LeoOkay, that lands.
MayaAnd let me ground the whole machine in the running example we've carried all topic. Our payments service — the one quietly dropping about one transaction in a thousand under load.
LeoThe car the pit crew's been working on all season.
MayaThat car. Now imagine the fix isn't a one-hour patch — it's a multi-day rebuild of the retry layer, way more than one shift can hold. The Punch List has the entries: "dropped transaction is retried within the window," "duplicate retries don't double-charge," "the dropped-payment metric reads zero under load." All failing.
LeoSo shift one doesn't fix the bug, it just—
Maya—picks one. "Retries don't double-charge." Builds it, drives a test that fires a thousand transactions and checks the ledger, watches it pass, writes in the Shift Log "double-charge guard in, dedup key on the request, metric still red," commits. Done. Walks away with amnesia.
LeoAnd shift two reads that note and knows the dedup's handled, so it doesn't redo it — it goes after the next red line.
MayaIt goes after the next red line. The bug that needed five sessions gets five sessions, and not one of them starts from zero. That's the harness turning a task too big for one context window into something a chain of forgetful agents can finish.
LeoOkay, I'm sold on the shape. Now let me be the killjoy, because the source is honest and I want to be too. Where does this fall down?
MayaGood — and it is refreshingly upfront. The sharpest limit is the eyes. The agent's testing through the browser tool, but it "can't see browser-native alert modals through the Puppeteer MCP."
LeoMeaning some pop-ups are just invisible to it.
MayaInvisible. So any feature that leans on those native pop-up dialogs comes out, in their word, "buggier" — because the agent literally can't see the thing it'd need to check. The verification is only as good as what the eyes can perceive, and the eyes have blind spots.
LeoHm. So the trust in the test sheet has a footnote.
MayaIt does. A green Punch List means "everything I could see, passed." Not "everything passed." And that's a real gap, not a rounding error — it's the difference between verified and verified-where-I-could-look.
LeoThat's the honest version, and I respect that they printed it. What about the bigger question — is one general-purpose agent doing all this even the right design?
MayaAnd that's the one they leave genuinely open, which I think is the right call rather than overclaiming. They're not sure whether "a single, general-purpose coding agent performs best," or whether you'd do better with a crew of specialists — one agent that only writes tests, one that only does cleanup, one that only does QA.
LeoAnd I want to be careful here, because we staged the multi-agent fight last episode and I don't want to relitigate it.
MayaRight, and we shouldn't — different question. Last time it was many agents working at once on one task. This is whether the long-running build wants specialists across the shifts. The source doesn't pick a winner. It flags it as where the work goes next.
LeoPlus the whole thing's tuned for one domain, right?
MayaOne domain — they say it's "optimized for full-stack web app development," and they're openly unsure how it carries to, say, scientific research or financial modeling. The Punch-List-plus-browser-test loop fits web apps almost suspiciously well. A domain where you can't just click a button to know you're right might need a totally different baton.
LeoSo the honest takeaway isn't "here's the universal harness." It's "here's a harness that works beautifully for one shape of work, with the seams marked."
MayaAnd that, to me, is the real lesson of the episode. Look at what makes it work and none of it is a model trick. A locked-down to-do list, a handover note, a save point, a forced ritual of read-then-do-one-thing-then-verify. The source even says the design comes from "knowing what effective software engineers do every day."
LeoIt's not making the agent smarter. It's giving a forgetful agent the habits of a good team.
MayaThat's the sentence. The intelligence was already there each session. What the harness adds is continuity — a way for a chain of amnesiacs to behave like one engineer who remembered the whole project.
LeoSo here's what I'm sitting with. If the durable artifacts — the list, the log, the commits — are what actually carry the project forward, then the agent's real work product every session isn't the code. It's a clean baton for the next runner.
MayaSo the question I'd leave you with: on your own team, when someone hands off a half-finished project, how much of what they know lives in something the next person can read — and how much of it just walks out the door in their head?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents