Subscribe
Transcript
MayaAsk one good researcher a hard, open-ended question — "who are all the board members of the companies in this index, and how do they overlap?" — and watch what they do. They don't read one page at a time, in order. They spin up six browser tabs at once, skim, throw four away, and chase the two that look alive.
LeoRight, that's just how anybody researches.
MayaIt is. So here's the thing that should be obvious but wasn't, for a while: if that's how the work actually wants to be done, why are we making one agent do it one tab at a time?
LeoHuh.
MayaThat's the whole question today. What happens when you stop running one agent through a long search, and instead stand up a little team of them — one that plans, several that go look — all working at once.
LeoAnd today's source is Anthropic's writeup on exactly that — how they built the multi-agent system behind their Research feature. The engineering blog post, not a paper. Real production lessons.
MayaLast time we watched Codex take a bounded task into a sealed room and come back holding receipts — one agent, one task, one transcript. Today's source flips the camera the other way: what if the job is too big and too branchy for one room, and you need a crew that splits up?
LeoSo the through-line for the whole topic is still our one car on the lift, the payments service that's quietly dropping one transaction in a thousand. But today the question isn't "how does one mechanic work." It's "when do you call in the whole crew, and when does the crew just get in each other's way."
MayaExactly the tension. And I'll tell you up front — the most honest thing in this whole post is that the answer is "it depends," and they're specific about what it depends on.
LeoOkay. Before we get to "it depends," give me the shape. What did they actually build?
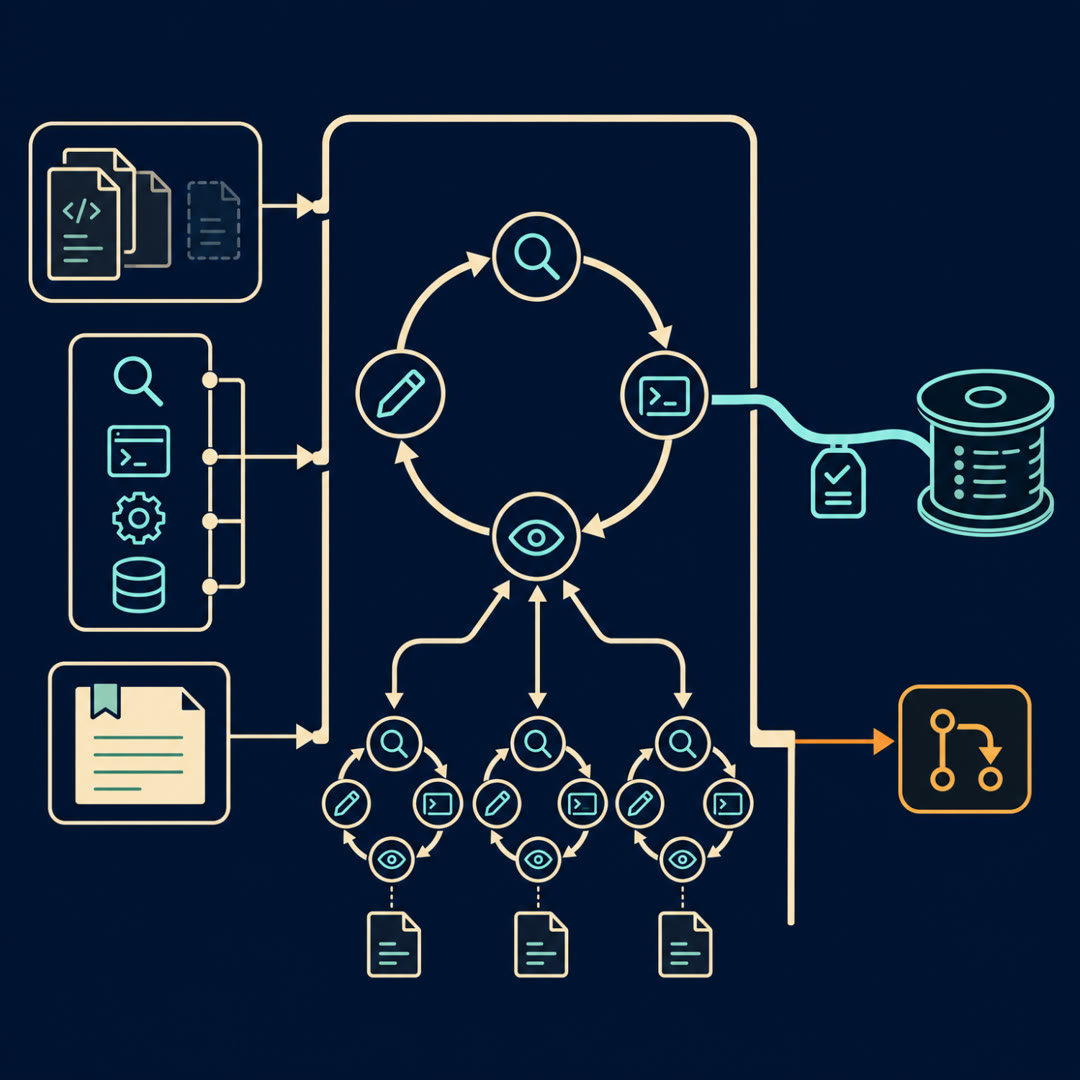
MayaLet me give you three moving parts and a name for each, so they're easy to hold while we talk. There's the one who decides — the Planner. There's the ones who go look — the Scouts. And there's the one who checks the footnotes at the end — the Fact-Checker.
LeoPlanner, Scouts, Fact-Checker.
MayaThe Planner is a single lead agent. You give it the big question. It doesn't go search. It thinks about strategy, breaks the question into pieces, and then spawns the Scouts.
LeoHow many scouts?
MayaDepends on the question — hold that, because the "how many" turns out to be one of the most important knobs in the whole system. The Scouts are subagents. Each one gets its own piece, its own separate context window, its own set of tools, and goes off and searches in parallel. Not one after another — at the same time.
LeoAnd each scout has its own context window. So they're not all crammed onto one desk fighting for space.
MayaThat's the heart of why this works, and I want to slow down on it. A single agent doing a huge research task has one context window — one desk. Every page it reads piles up on that desk until there's no room to think. Give each Scout its own desk, and each one can read deeply in its own lane and bring back just the distilled finding. The Planner never has to hold all the raw pages at once.
LeoSo the separate context windows aren't a side effect of having multiple agents. They're the actual point.
MayaThey're the actual point. The post says it directly — subagents with separate contexts let the system explore different aspects simultaneously and compress what they find before it ever reaches the lead. Parallel breadth plus compression. That's the move.
LeoAnd the Fact-Checker?
MayaA specialized agent — they call it the citation agent — that runs near the end. Once the Planner has synthesized an answer, the citation agent goes back through and attaches every claim to the source it actually came from. So the output isn't just an essay, it's an essay where each sentence can point to where it learned that.
LeoOkay. I want the number, though. Because "we built a team of agents" is a vibe. Did the team actually beat the solo version?
MayaIt did, and the gap is not subtle. On their internal research eval, the multi-agent setup — a stronger model as the Planner, lighter models as the Scouts — outperformed a single agent running the strongest model alone by ninety percent.
LeoNinety. The team of a big planner plus smaller scouts beat one copy of the big model working solo. By ninety percent.
MayaBy about ninety percent on that eval. And the reason why is the part I find genuinely surprising — it's almost embarrassingly mechanical.
LeoGo.
MayaThey went looking for what predicted a good research result. And the single biggest factor — they could measure this — was just how many tokens the system spent. Token usage alone explained around eighty percent of the variance in performance. Add in how many tool calls it made and which model it used, and you're at ninety-five percent.
LeoWait. Hold on. You're telling me the best predictor of a good answer was basically how much the thing spent thinking and searching?
MayaThat's what the data said.
LeoThat can't be the whole story. "Spend more, do better" is the kind of finding that's true right up until it's a disaster.
MayaYou're right, and that's the right instinct. So let me say what it actually means, because the framing matters. It's not "spending tokens makes you smart." It's that hard, open-ended research questions genuinely need a lot of separate looking — and a single agent on a single context window hits a ceiling on how much looking it can do before its desk overflows. Multi-agent is a way to spend way more total effort without any one agent drowning.
LeoSo the architecture isn't the magic. The architecture is what lets you pour in the effort the task needed all along.
MayaThat's the cleaner way to say it. And here's the cost of that, plainly: these systems are token-hungry. The post says agents already use roughly four times the tokens of a normal chat, and a multi-agent system uses around fifteen times the tokens of a chat.
LeoFifteen times. [gasp] That's not a tweak, that's a different budget.
MayaFifteen times. So this only makes economic sense when the answer is valuable enough to justify the burn. Which is the perfect bridge to the fight we have to have.
LeoOh good, a fight.
MayaThe good kind. Because here's the trap. We just spent ten minutes on a system that crushed the solo agent by ninety percent. The lazy lesson is "multi-agent good, single-agent old news, spin up scouts for everything."
LeoAnd I do not believe that for a second.
MayaGood. Take the other side, then, for real. I'll argue multi-agent is the right shape; you argue it's the wrong shape for most of what our listeners actually do. And we're both going to use what's in this post, not strawmen.
LeoHappy to. Here's my case. That ninety-percent win was on research — breadth-first, go-find-things, lots of independent lookups that don't talk to each other. The board-members question. That is the best possible case for fanning out. Now bring it back to our car on the lift. Fixing the payments bug isn't breadth-first. It's one tangled thread — read the code, form a theory, change a line, see what breaks, revise. Every step depends on the one before it.
MayaMm.
LeoAnd this post — the multi-agent post — actually agrees with me. It says straight out that multi-agent systems are a bad fit for tasks where all the agents need to share the same context, and for tasks with lots of dependencies between the pieces. It literally names coding as the harder case, because most coding work doesn't break into truly parallel chunks.
MayaThat's a fair hit, and I'm not going to dodge it. But you're smuggling in an assumption — that the whole job is one tangled thread. It isn't. Even on our payments bug, there's a phase that's pure breadth. "Find every place this transaction code path is touched across forty files." "Pull the last six incident reports that mention dropped writes." "Check how three other services handle this same retry." That's scout work. Independent, parallel, no shared desk needed.
LeoFine. The investigation phase fans out. I'll give you that — and it's a real concession, because that's genuinely a chunk of the work.
MayaBut—
LeoBut the fix doesn't. The moment you're actually editing the code, you need one agent holding the whole picture, because change A breaks assumption B three files over. Five scouts each editing in their own sealed context is how you get five patches that individually pass and together corrupt the build.
MayaAnd there I fully concede. That's exactly right, and it's the same place we landed in the overview — many eyes during the looking, one hand on the final change. The post's own line is that minor failures get catastrophic when agents run long and stateful, and the more independent writers you have, the more ways that goes wrong.
LeoSo where does that actually leave us? Because it sounds like we just agreed.
MayaWe mostly did, and that's the honest resolution — it's not "multi-agent versus single-agent," it's "match the topology to the task." Let me try to draw the line cleanly. Fan out when the work is wide and separable and the pieces don't need to see each other — search, reproduction, gathering, review. Keep it single and sequential when the work is deep and entangled and every step reads the last one — the actual patch.
LeoAnd the tiebreaker, when you're not sure?
MayaCost and value. Fifteen times the tokens. If the answer is worth a lot and the work is parallel, fan out. If it's a cheap task or a tangled one, one agent is not a downgrade — it's the right tool.
LeoOkay. That I'll sign.
MayaSo let's say you've decided fanning out is right. The post is full of hard-won lessons on making it not fall apart, and a few of them genuinely changed how I think about prompting.
LeoGive me the one that surprised you most.
MayaThe delegation problem. When the Planner spawns Scouts, the obvious failure is it gives them vague orders. "Go research the energy sector." And then two Scouts do the same search, a third wanders off into something unrelated, and you've paid for redundant work.
LeoBecause the scouts can't see each other. Each one only knows what its planner told it.
MayaExactly — so the instruction is everything. They found the Planner has to hand each Scout a real spec: a clear objective, the output format it expects back, which tools and sources to use, and hard boundaries on scope. The post's phrase is basically "teach the orchestrator how to delegate." A scout is only as good as its briefing.
LeoThat's the same lesson as the Codex episode, weirdly. The definition of done.
MayaIt's the same lesson one level up. There you brief an agent. Here you teach an agent to brief other agents.
LeoManagement all the way down. [chuckle]
MayaManagement all the way down. And here's my favorite finding in that vein — they had agents improve their own tools. They let an agent look at a tool with a bad description, watch other agents fail using it, and rewrite the description. The rewritten tools cut task completion time for the next agents by about forty percent.
LeoWait, the agent wrote a better instruction manual for the next agent than the humans did?
MayaFor those tools, yes. Which tells you how much of this is just interface design — an agent reading a confusing tool description goes down the wrong path the same way a person would.
LeoOkay, one more, then I want to hit the part everybody skips. How do you even know it's working? You've got a non-deterministic team of agents — run it twice, you get two different paths.
MayaThat's the real production wall, and they're candid about it. You can't grade these the way you grade a function with a fixed right answer. They leaned on a couple of things. First off, they stopped grading every step and started grading the end state. Did it reach a correct final answer, regardless of the path it took to get there?
LeoBecause there are a hundred valid research paths to the same true answer.
MayaRight. And then for the quality you can't reduce to a checkbox, they brought in a model as a judge. One agent reads the final report against a rubric — are the claims accurate, do the citations actually back them, did it cover everything asked, did it prefer primary sources.
LeoA model grading another model's homework. I always flinch at that.
MayaYou should flinch a little. Which is why they keep humans in the loop for the edge cases — the post is blunt that human testers catch failure modes the automated evals miss entirely, like an agent quietly preferring sketchy sources, or hallucinating a citation that looks perfect.
LeoThat's the one that scares me. A confident, well-formatted, fully-cited answer where one of the citations is just invented.
MayaWhich is exactly why the Fact-Checker exists as its own agent at the end. The citation step isn't decoration — it's the thing standing between "fluent" and "true."
LeoAnd the unglamorous production stuff? Because "works in the demo" and "works for real users all day" are different planets.
MayaThey are, and the post's closing line is the one I'd tattoo on a junior engineer: the last mile becomes most of the journey. A couple of concrete things. These agents are stateful and long-running, so a small error early doesn't just fail — it compounds, because the agent keeps building on the broken step.
LeoSo you can't just retry from the top like a normal request.
MayaYou can't, which forces real engineering — letting an agent resume from where it broke instead of restarting. And debugging is wild, because the runs are non-deterministic. Their answer is heavy tracing — record the agent's decisions so you can reconstruct why it went sideways, without snooping on the actual user content.
LeoTrace the decision, not the conversation. That's the observability thread from the overview showing up for real.
MayaIt's the flywheel we promised. And one more I loved — how do you ship a new version while agents are mid-flight on hour-long tasks? You can't just swap the engine under a running car.
LeoRight, it's still driving.
MayaSo they do gradual rollouts — they call them rainbow deployments — easing traffic from the old version to the new one while both keep running, so nobody's in-progress research gets guillotined by a deploy.
LeoRainbow deployments. [chuckle] Okay, that's a good name.
MayaSo pull it together. The win was real — ninety percent on research — but it came from spending far more effort in parallel, not from the cleverness of having many agents for its own sake.
LeoAnd the discipline is knowing which shape the task wants. Fan out for the wide, separable looking. One hand for the deep, entangled fixing. And budget for the fact that the parallel version costs fifteen times as much.
MayaThat's the whole episode. The architecture doesn't make the work smart. It just lets you spend the effort the work actually needed — when the work is the kind that splits.
LeoSo here's what I'm sitting with. Think about the last genuinely hard problem you handed to an AI. If you had to split it into a planner and a few scouts — where exactly would the seam fall, and which part of it would refuse to be split?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents