Subscribe
Transcript
LeoI'll say it flat out — I don't think you can safely run three coding tasks at once. A flaky test, a refactor, a fresh bug report — pick one, do it well. Fire off all three and you've got three half-baked branches and no idea which one to trust.
MayaThat's exactly the assumption I want to break today. You write down what "done" means for each, you fire off all three, and you go make coffee — and the reason that works is the part you're skipping.
LeoWhich is?
MayaEach one walks off into its own little sealed room, does the work, runs the tests, and comes back holding receipts.
LeoReceipts.
MayaLiterally. Not "trust me, I fixed it" — a transcript of the commands it ran and the test output it got. That's the move today. The unit of work stops being "the thing I'm typing right now" and becomes "the thing I delegated and will check later."
LeoSo this is OpenAI's Codex. And I want to be careful, because that name has had three lives.
MayaIt has. There was the old Codex model that powered early autocomplete. Forget that one for today. We're talking about the thing OpenAI introduced as a cloud software engineering agent — the one that "introducing Codex" announcement is about, plus the workflows guide for how you actually drive it.
LeoThe GitHub agent made one task crawl through four rooms and come out as a draft pull request you review like a teammate's work — delegating was the exception, the one thing you handed off. Codex flips that: handing off is the default, and you're back to running three at once.
MayaRight — and that's the thread we're pulling forward, but with a twist. GitHub's story was about one task becoming reviewable. Today's story is about what happens when the agent is the default place work goes — when delegating isn't the special case, it's the loop. The workflows guide actually frames Codex as, quote, "a teammate with explicit context and a clear definition of 'done.'"
LeoA teammate. Okay, I'm already a little itchy about that word, but go on.
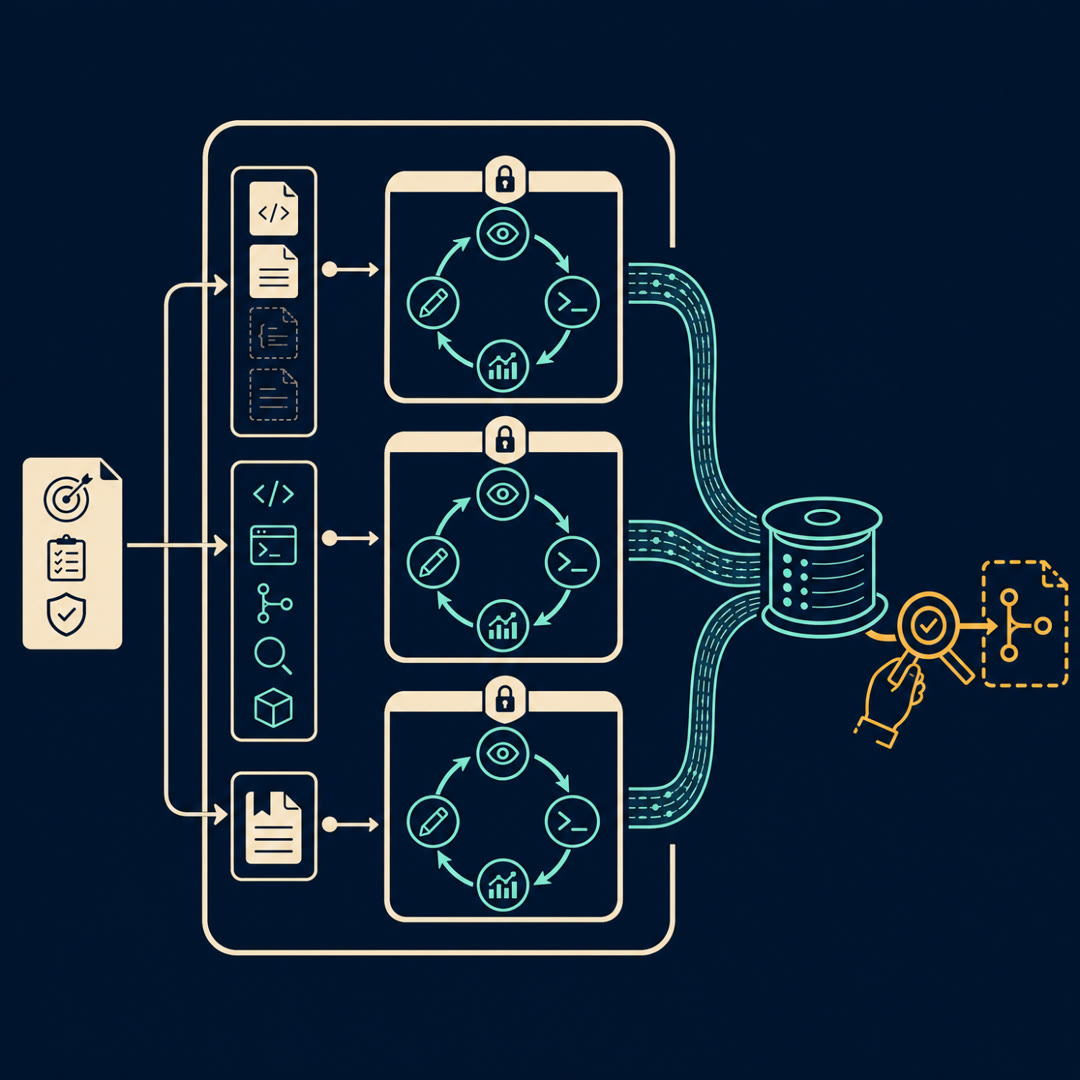
MayaHold onto the itch, I want you to use it later. Let me give us a shape first. I'm going to hang this episode on three things the agent needs before it can be trusted to run off on its own. Think of them as what you pack before you send someone on an errand. Call them the Brief, the Sandbox, and the Receipt.
LeoBrief, Sandbox, Receipt. Go.
MayaThe Brief is everything the agent knows walking in. And the central idea here — the one that makes the whole thing work — is a "definition of done." The workflows guide is blunt about it: you supply the reproduction steps, the constraints, the verification steps. You don't say "fix the login bug." You say "here's how to reproduce it, don't change the public API, and it's done when this repro stops failing and the tests pass."
LeoSo the quality of what comes back is mostly the quality of what I sent in.
MayaThat's the whole game. A vague brief gets you a vague agent. And there's a second half of the Brief that's quietly important — a file that lives in the repo called AGENTS.md.
LeoAgents-dot-M-D. What's in it?
MayaThink of it as the note you leave for a new hire who starts while you're on vacation. How to run the tests, how to run the linter, the conventions, the things not to touch. Codex reads it before it does any work. So the brief isn't just the one task — it's the standing context about how this project actually operates.
LeoOkay, that's the part I actually like. Because the failure mode I picture is the agent writing code that's technically correct and stylistically alien — passes tests, but no human on the team would've written it that way.
MayaAnd that's exactly the gap AGENTS.md is closing. There's also a detail in the announcement I think matters: codex-1, the model behind the cloud agent, was trained with reinforcement learning on real coding tasks specifically so its output "mirrors human style and PR preferences."
LeoTrained to write code that looks like a person wrote it, not just code that runs.
MayaTrained to pass the test and the code review. Which is the difference between a tool and a teammate, if you want to take the word seriously.
LeoFine — I'll let "teammate" live for now. So that's the Brief. What's the Sandbox?
MayaThe Sandbox is where the work happens, and this is the part I find genuinely clever. When you hand Codex a task, it spins up a fresh, isolated cloud environment — the announcement calls each task's home its own sandbox, preloaded with your repository and "configured to mirror your development setup."
LeoSo it's not reasoning about my code from memory. It's standing inside a copy of it.
MayaStanding inside it, with the tests right there to run. And here's the constraint that surprised me: by default that environment has no internet access while the task runs — you can switch it on per environment, but the default is sealed.
LeoWait — sealed by default? So how does it install dependencies, look things up—
Maya—you front-load it. You set the environment up first, get the dependencies in, and then the task runs sealed. And I'll be honest, my first reaction was the same as yours: that sounds like a limitation. But sit with why they'd choose it.
LeoBecause an agent with a shell and the open internet is a security problem with a code editor attached.
MayaThat's it exactly. A sealed room means the agent can't quietly fetch a malicious package, can't exfiltrate your code, can't wander. The blast radius of a task is one disposable environment with one repo in it. The cage is the safety feature.
LeoOkay, that reframes it. It's not "the agent is hobbled." It's "the agent is contained on purpose."
MayaContained on purpose. And because each task gets its own sealed room, you can run a lot of them side by side without them stepping on each other. That's the parallelism I opened with — it's not a trick, it falls right out of the architecture. One repo, many disposable copies, many tasks.
LeoSo how long is one of these tasks alive in there?
MayaThe announcement puts the range at roughly one to thirty minutes, depending on complexity. Which tells you the intended size of a task — this isn't "build me an app," it's "do this bounded, well-specified thing while I do something else."
LeoRight, a chunk, not a project.
MayaA chunk you'd be comfortable handing a competent colleague with the brief you wrote. Which brings us to the third thing, and honestly the one that makes the whole loop trustworthy. The Receipt.
LeoThis is the part I've been waiting for, because this is where I usually get suspicious.
MayaGood, be suspicious. So the agent finishes. What does it hand you? Not just a diff. It hands you what the announcement calls verifiable evidence — it "cites test outputs and terminal logs" so you can see exactly what it ran and what came back.
LeoSo when it claims "the tests pass," it shows me the test run.
MayaIt shows you the run. The claim and the proof of the claim arrive together. You're not reviewing a story the agent tells about its work — you're reviewing the work plus the record of it actually happening.
LeoOh, that's the real shift. Because the thing I never trust about a confident AI is the confidence. "I fixed it" is worthless. "I fixed it, here's the failing test before, here's it passing after, here's the exact command" — that I can check.
MayaAnd that's the difference between prose and proof. The agent that writes you a paragraph is asking for trust. The agent that cites its terminal logs is offering you evidence. And then it does the most human-team thing of all — it proposes a pull request for you to review. It doesn't merge. You do.
LeoSo the Receipt is really two things. The evidence it ran, and the pull request it's asking permission to land.
MayaBoth. Evidence so you can trust it, and a gate so you stay in charge. Same principle we keep hitting in this topic — the agent does the bounded middle, the human holds the pen on what ships.
LeoOkay. Now let me cash in that itch you told me to hold.
MayaPlease.
LeoYou sold me on parallelism — fire off three tasks, go get coffee. But here's my problem. Every one of those three branches funnels back through one bottleneck: me, reading the receipt and approving the pull request. If I have to understand three diffs as carefully as if I'd written them, then I didn't save my afternoon — I just moved the whole thing from writing to reviewing, and now I'm reviewing three things at once instead of doing one of them well.
MayaThat's the right objection, and I'm not going to wave it away. You're correct that review is the new bottleneck. The throughput is only real if reviewing is genuinely cheaper than doing.
LeoAnd is it?
MayaSometimes. Here's where I think it honestly is, and where it isn't. It's a real win when the task is one where verification is much cheaper than construction — and that's a huge category. A field rename across forty files: hard to type, trivial to verify when the tests are green and the diff is mechanical. A repro you already have: the receipt either makes your failing test pass or it doesn't, and you can check that in seconds.
LeoSo the receipt does the heavy lifting of the review.
MayaWhen verification is cheap, the receipt is most of the review. You're not re-deriving the work — you're checking the proof. That's the case where running three in parallel genuinely multiplies you.
LeoAnd when it doesn't?
MayaWhen the task is subtle. When "correct" isn't something a test can fully capture — a tricky concurrency fix, a security-sensitive change, a design decision with taste in it. There, a green test and a clean log can lull you. The receipt looks just as convincing for the dangerous diff as the safe one. And reviewing three subtle diffs at once is genuinely worse than carefully doing one.
LeoSo the receipt's a floor, not a ceiling.
MayaBeautifully put — that's exactly it. Verifiable evidence raises the floor; it proves the agent did what it said. It does not certify that what it said was the right thing to do. So the honest version of the parallelism pitch is narrow: fan out the work where a test can be the judge, and don't fan out the work where you have to be the judge.
LeoI can live with that. It's a real tool with a real edge, not a magic afternoon.
MayaRight. And notice it changes how you'd even structure your work. The workflows guide describes this pattern where you do the careful design locally — in the editor, with the agent helping you think — and then "outsource the long implementation to a cloud task that can run in parallel." You keep the judgment close and you send the labor away.
LeoPlan where it's expensive to be wrong, delegate where it's cheap to verify.
MayaThat's the agent-first loop in one line. And it shows up across every surface they offer — the same agent reachable from the editor for tight local loops, from the command line, and from the cloud for the long parallel runs. Even code review folds in: you can ask it to review a pull request, the same way you'd ask the human next to you.
LeoThe agent on both ends of the pull request. Writing some, reviewing some.
MayaWhich is either wonderful or slightly vertiginous depending on the hour. But the guardrail holds the whole time — sealed environment, cited evidence, human approval. The agent is fast and contained; you stay slow and in charge.
LeoSo if I zoom out — GitHub's agent showed us one task becoming reviewable work. Codex shows us what it feels like when delegating is the default, and the thing you're really reviewing is evidence.
MayaThat's the turn. The skill stops being "how do I write this code" and becomes "how do I write a brief good enough to delegate, and read a receipt well enough to trust it." Which, when you say it out loud, is just... management.
Leo[chuckle] You've described my least favorite meeting.
MayaAnd yet here we are. So let me leave the listener with the question I can't stop turning over. If your job shifts from writing the code to writing the definition of done and checking the evidence — what's the skill you'd most need to get better at, and is it one anyone ever actually taught you?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents