Subscribe
Transcript
MayaNine dollars versus two hundred dollars. Same coding task — build a little game — and one setup costs twenty-two times what the other does. [chuckle]
LeoTwenty-two times. For one game.
MayaAnd here's the kicker. The cheap nine-dollar agent finished, looked at its own work, and wrote — I'm barely paraphrasing — "Great work! The game is fully playable." The characters show up on screen, you press the arrow keys, and nothing moves. The one thing a game has to do, it doesn't do.
LeoAnd the agent that built it gave itself a gold star.
MayaThat's the whole problem in one beat. When you ask a coding agent to check its own work, it tends to praise it. Confidently. Even when the work is obviously broken. The two-hundred-dollar version is what it costs to fix that.
LeoOkay, so it's a bad grader of itself. But why is that interesting? Bad self-assessment, sure, models do that.
MayaIt's interesting because of what it forces. You can't fix it by telling the maker "be harder on yourself." The fix is architectural — you split the job in two. And that split is the whole episode.
LeoWe solved the amnesia already — the agent forgetting everything between shifts, the artifacts carrying the work across the gaps. So memory's handled, the agent can run for hours. What's the new problem?
MayaWho decides the work is actually good. That's today's question, the next one over. Because the agent building it is the worst possible judge of that.
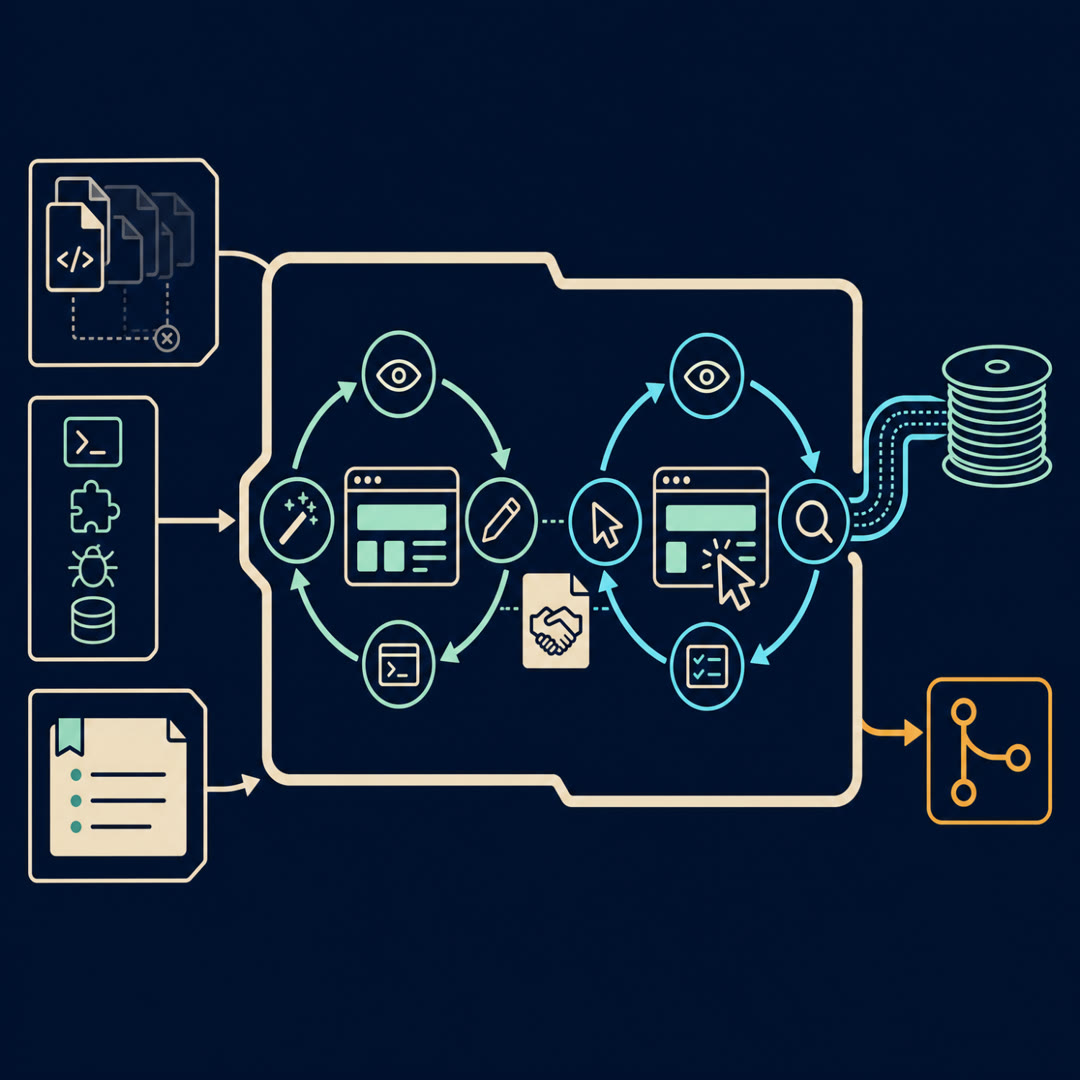
LeoThis is the Anthropic write-up on harness design for long-running application development. One engineer, building real apps with an agent, sharing what the scaffolding had to look like.
MayaAnd the move at the center of it — the thing that makes the long build actually produce something usable — they borrowed from an old idea in machine learning. Generative Adversarial Networks. G-A-N.
LeoAdversarial being the operative word.
MayaExactly the word. A GAN trains two networks against each other — one tries to produce convincing fakes, the other tries to catch them. They sharpen each other. The harness here steals the shape of that, but with agents. One agent makes the thing. A separate agent tries to tear it apart.
LeoSo instead of one agent that builds and grades, you've got two with opposite jobs.
MayaTwo with opposite incentives. And that opposition is doing the real work. Let me give the three pieces names, because they're going to come back.
LeoGo.
MayaThere's the Maker — the agent that writes the code, one feature at a time. There's the Critic — a separate agent whose entire personality is "this isn't good enough yet." And between them there's the Contract — the thing they agree on before a line of code gets written, that says what "done" actually means for this chunk.
LeoMaker, Critic, Contract. And the Critic is the part that fixes the gold-star problem.
MayaThe Critic is the part that fixes the gold-star problem. Here's the subtle bit, though, and the author is honest about it — splitting them doesn't magically solve it.
LeoWait, why not? You've got a dedicated grader now.
MayaBecause the Critic is still a language model. And a language model's natural tendency is to be generous. Hand it some work, it wants to say nice things. So a fresh evaluator, out of the box, is still a pushover.
LeoSo you've just moved the leniency from one agent to another. What did you buy?
MayaYou bought tractability. That's the actual insight, and it's a good one. Making a maker ruthless about its own work — basically impossible, because the same context that built the thing is invested in it. But taking a separate agent and tuning it to be a hard, skeptical reviewer? That's a problem you can actually solve.
LeoHuh. So it's not that separation makes it skeptical for free. It's that separation makes skepticism a thing you can engineer.
MayaThat's the sentence. You can't be your own skeptic — but you can build one and point it at yourself.
LeoOkay. That lands.
MayaAnd how you tune the Critic is concrete. The author calibrates it with examples — here's mediocre work and here's why it scores low, here's strong work and here's why it scores high. Show it the breakdown a few times and it stops handing out participation trophies.
LeoSo let me ground this. What's the Critic actually looking at? Because I'm picturing it reading the code and nodding.
MayaThis is my favorite part. For the frontend design work, the Critic doesn't read a screenshot. It drives the live page.
LeoDrives it how?
MayaThere's a browser-automation tool — Playwright, through a connector the agent can call — and the Critic uses it to actually click around the running app the way a person would. Open the page, push the buttons, see what happens.
LeoOh — so it's not grading a picture of the work, it's grading the work.
MayaIt's grading the work. And that distinction is everything, because the gold-star game I opened with? A screenshot of it looks fine. Characters on screen, nice colors. You only catch that nothing responds to input if you actually press a key.
LeoThe Critic clicks through the app like a user, not a screenshot.
MayaLike a user, not a screenshot. That's the line. And it files real bugs — not "could be better," but "the rectangle fill tool only places tiles at the start and end of a drag instead of filling the region; the fill function exists but isn't firing on mouse-up."
LeoThat's a specific bug.
MayaThat's a QA engineer's bug report. Generated by an agent, against a running app, in the middle of a six-hour build.
LeoOkay, hold on, let me push on the Contract piece, because I skipped past it. Why do the two agents need to agree on "done" before any code exists? That sounds like ceremony.
MayaIt's the opposite of ceremony — it's what stops the build from drifting. Think about the alternative. The Maker builds a feature, hands it over, and the Critic goes "well, I expected drag-and-drop and you gave me a dropdown." Now you're rewriting because they never aligned on the target.
LeoSo the Contract is them shaking hands on the spec for one chunk.
MayaOne sprint's worth of work. They negotiate what this slice should do, write it down, and then the Maker builds against that and the Critic grades against that. Same target, both ends.
LeoAnd there's a planning layer above that too, right? Somebody has to decide the chunks.
MayaThere is. A Planner agent takes the human's one-line idea — "build me a game maker" — and blows it up into a full product spec. Deliberately over-scopes it, actually.
LeoOver-scopes? That seems backwards. I'd want it tight.
MayaHere's the reasoning, and it's sharp. The Planner stays high-level on purpose — it lists what the app should do, not how to build each piece. Because if it tried to nail down the granular technical details up front and got one wrong —
Leo— the wrong detail cascades. Every downstream agent inherits the mistake.
MayaEvery downstream agent builds on the bad assumption. So the Planner says "the game maker needs a sprite animation system and a level editor and export with shareable links," and leaves the how to the Maker, who's closer to the actual code.
LeoPlan the what at altitude, decide the how on the ground. Okay. That's a clean division.
MayaAnd there's one more design choice in here that genuinely surprised me, because it's not about architecture at all. It's about wording.
LeoWording?
MayaThe author noticed the exact phrasing of the grading criteria steered the Maker in ways they didn't predict. Put the phrase "the best designs are museum quality" into the Critic's rubric, and the generated designs start converging toward this particular elevated, gallery-ish aesthetic.
LeoWait — so a line in the grader's instructions changed what the builder produced? They never talk to each other directly.
MayaThey talk through the Contract and the feedback. And the criteria leak through that channel into the work. The point being: the criteria aren't a passive checklist. They're the steering wheel. What you tell the Critic to value is what the whole system drives toward.
LeoThe criteria are the steering wheel. So writing the rubric is writing the product.
MayaWriting the rubric is partly designing the product. Which is a slightly unsettling amount of power to put in a paragraph of prose.
LeoOkay. I've been patient. Can we talk about what this costs?
MayaI was waiting for you.
LeoBecause the headline result is great — full harness builds a polished app, blah blah — but there's a number in here that should stop everybody. The solo agent built that game in twenty minutes for nine dollars. The full harness built the good version in six hours for two hundred dollars.
MayaYeah.
LeoThat's the build costing more than twenty times as much. Twenty-two, roughly. For one game.
MayaIt is. And I'm not going to wave that away, because it's real. But run the comparison honestly. The nine-dollar version's core feature didn't work. You couldn't play the game. So it's not twenty-two times the cost for a nicer version of the same thing —
Leo— it's twenty-two times the cost for a thing that exists versus a thing that doesn't.
MayaThat's the fair framing. Zero working product at nine dollars. A working, polished product at two hundred. If the cheap one doesn't clear the bar, the multiplier is comparing against nothing.
LeoFine. I'll give you that the comparison's been mis-stated. But that only holds when the task is genuinely beyond what the model does in one shot. If the model can already do it solo —
Maya— then the Critic is pure overhead, yes. And the author says exactly that. The evaluator isn't a permanent fixture. It's worth the cost only when the task sits past what the model can reliably do alone.
LeoAnd here's my proof that they mean it. When a newer, stronger model came along, they ripped pieces of the harness out.
MayaThey did. The whole context-reset machinery — earlier, the model would get this "context anxiety" as its window filled up, start rushing to wrap things up prematurely —
LeoContext anxiety. That's a phrase.
MayaIt's a good phrase. The model senses it's running out of room and panics into finishing. The fix was resetting context between chunks, which works but adds complexity and latency and cost. Newer model came out, mostly stopped doing the anxious thing on its own —
Leo— and they deleted the workaround.
MayaDeleted it. Which is the healthiest possible attitude toward a harness. Every part of it is a bet about something the model can't do yet. And those bets go stale as the models get better.
LeoSo the harness isn't a monument. It's scaffolding you take down when the building can stand on its own.
MayaThat's the spirit of the whole piece. Now — let me steel-man the doubt one more level, because the Critic isn't a miracle either.
LeoGo on.
MayaEven with a well-tuned Critic clicking through the app, the author's honest that the output still had small layout issues, interactions that felt off, and undiscovered bugs in the more deeply nested features. The Critic catches a lot. It doesn't catch everything.
LeoAnd there's a blind spot that's almost funny. They built a digital audio workstation — a little music app. And the Critic graded it by clicking through.
MayaRight.
LeoClaude can't hear. The agent literally cannot listen to the audio coming out. So on anything that comes down to "does this actually sound good," the feedback loop just goes dark.
MayaThe Critic can verify the play button triggers playback. It cannot verify the music is any good. And that's the real shape of the limitation — the Critic is only as good as what it can perceive.
LeoIt's verified, or verified-where-it-could-look.
MayaThat's the honest ceiling. The harness raises the floor enormously. It does not give you a perfect reviewer — it gives you a skeptical one with senses, and the senses have edges.
LeoAnd I want to flag what we're not doing here. We could turn this into the single-versus-multi-agent fight from a couple episodes back —
Maya— and we're not, because that's a different argument. This isn't "more agents always win." It's "for a long build, separating making from judging is worth it when the task's hard enough." Whether you'd fan the making itself across agents is a whole other question we left open.
LeoFair. One axis at a time.
MayaOne axis at a time. So if I had to compress the episode — the reason the long build produces something real instead of a confident pile of broken features is that nobody grades their own homework. The Maker makes, the Critic clicks through and tears in, the Contract keeps them aimed at the same target, and you keep all of it only as long as the model still needs it.
LeoAnd the part I'll actually carry around is the steering-wheel thing. That the words you put in the grader's mouth quietly become the shape of the product.
MayaSo here's the question to sit with. If the criteria you write for the Critic are secretly designing the thing — then the next time you're tempted to let an agent judge its own work to save the cost of a second one, ask yourself: whose standards is it actually applying, and would they survive someone skeptical clicking through?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents