Subscribe
Transcript
MayaLast episode used SWE-agent to show why the model's workbench matters.
LeoToday Aider puts another layer under the microscope: applied edits, test feedback, and second attempts.
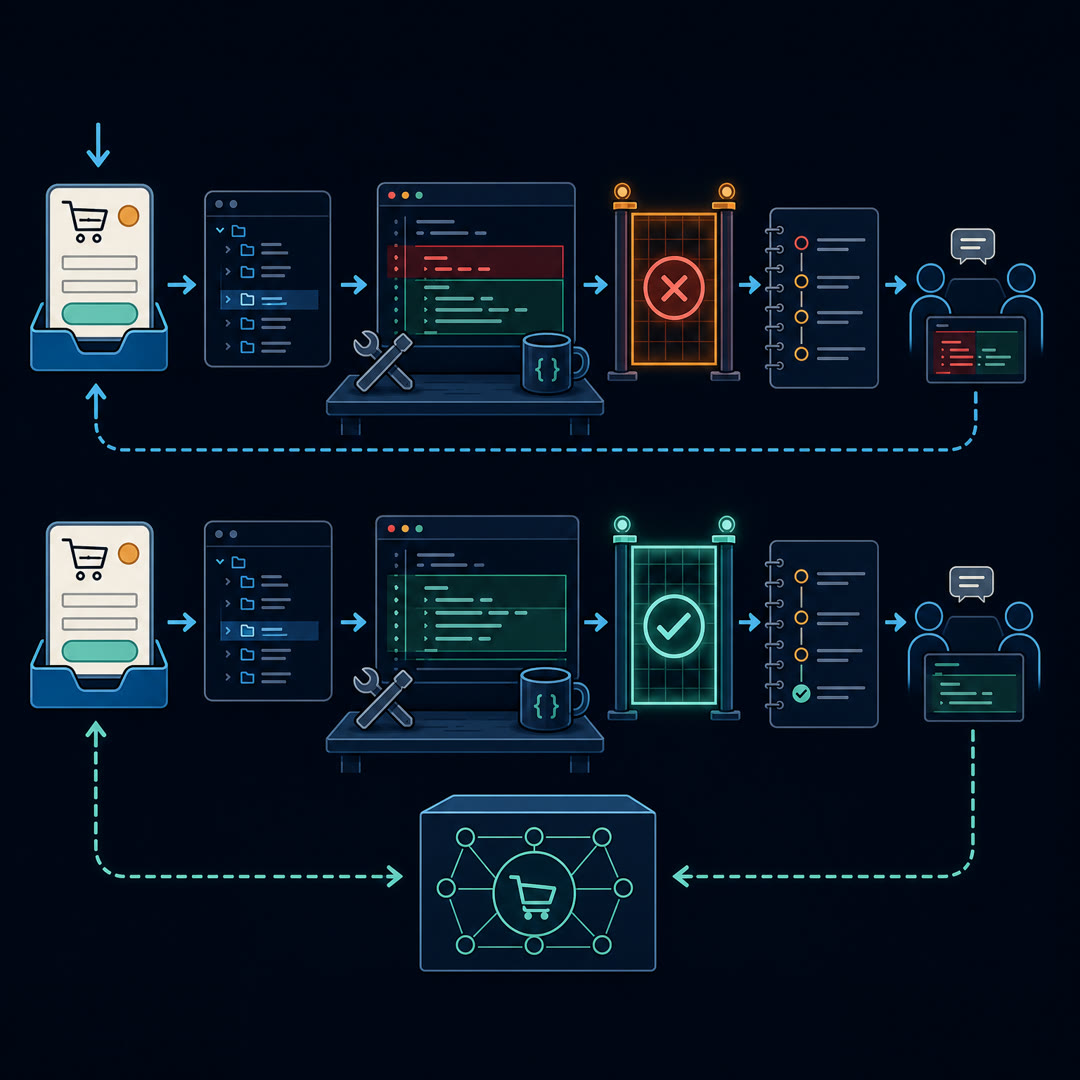
MayaA model writes the wrong code, a test fails, and the system sends back the error. The question is not only whether the model can code. It is whether it can repair its own first attempt.
LeoThat is a very practical kind of intelligence.
MayaExactly. That practical loop is the center of Aider's benchmark materials and leaderboards.
LeoPlain language: Aider is an open-source terminal pair-programming tool, and its benchmarks study whether models can make real edits that tools can apply and tests can judge.
MayaRight. The first landmark is the Edit Envelope.
LeoThe edit envelope is how the model packages its change?
MayaYes. A model can know what code should change but still fail if the edit format is hard to parse or apply. Aider's benchmark writeups emphasize edit formats because automated coding tools need to turn model text into actual file changes.
LeoSo "write the fix" and "deliver the fix in a usable shape" are separate abilities.
MayaExactly. The Aider benchmark documentation describes evaluating not only coding ability but also whether the model can format edits so the tool can save them to files.
LeoIn the express-checkout example, the model might explain the correct schema change, but if the patch cannot be applied cleanly, the workflow still fails.
MayaRight. The second landmark is the Test Echo. In Aider's benchmark writeup, tests provide feedback after an attempt. If tests fail, the model can receive error output and try again.
LeoThe express-checkout example makes that vivid: a failed backend validation test should send the model toward the shared schema, not toward another cosmetic form tweak.
MayaExactly. The quality of the repair is not measured only by whether the next test turns green. We also want to know whether the new attempt is narrower, better localized, and more faithful to the codebase's existing design.
LeoThe echo is not a full teacher. It is the environment saying, "This behavior did not match."
MayaExactly. Test output can be extremely helpful, but it can also be partial, noisy, or misleading if tests are weak.
LeoThe third landmark is the Repair Turn.
MayaThe Repair Turn is the second attempt after feedback. It is important because many human engineers do not solve every task on the first try either. They read failure output, update their hypothesis, and patch again.
LeoThis connects directly to trajectories.
MayaYes. A first attempt plus a repair attempt tells us more than a final result alone. Did the model understand the error? Did it change the right thing? Did it overfit to the test message?
LeoWhat does Aider's polyglot leaderboard add?
MayaIt broadens the lens beyond one language or one style of task. The leaderboard is useful because practical coding agents must handle many languages and frameworks. We should be careful not to freeze any current ranking into the script, because leaderboards change. The durable point is the evaluation shape: applied edits, tests, and model comparison.
LeoThe fourth landmark is the Language Spread.
MayaExactly. A coding assistant that only works in one familiar language may look strong in a narrow benchmark. A polyglot setting asks whether the workflow generalizes across syntax, libraries, and conventions.
LeoWhere do experts disagree about Aider-style benchmarks?
MayaOne side likes them because they are operational. The system must produce edits a tool can apply and pass tests. The strongest argument is that practical tools live or die by this kind of end-to-end reliability.
LeoAnd the skeptical side?
MayaThe skeptical side says edit-and-test benchmarks can still be narrower than repository issue resolution. The strongest argument is that passing unit tests in structured exercises does not prove the agent can localize a vague production bug, reason across architecture, or satisfy human review.
LeoSo Aider is not replacing SWE-bench. It is stressing a different muscle.
MayaExactly. SWE-bench stresses issue resolution in repositories. Aider stresses edit delivery, test feedback, model comparison, and repair behavior.
LeoWhat can training teams learn from it?
MayaThey should separate failure causes. Did the model choose the wrong algorithm? Did it misunderstand the task? Did it produce an edit the tool could not apply? Did it fail to use test feedback? Those are different labels.
LeoThe final patch alone would collapse those labels into "failed."
MayaRight. That is why agentic coding data needs trajectories and failure taxonomies. Aider-style runs can expose whether a model fails before editing, during edit packaging, after test feedback, or during repair.
LeoLet's make it concrete. The checkout agent patches frontend validation. Tests fail because backend validation is still missing. A strong repair turn reads the error and moves to the shared schema.
MayaA weak repair turn might just add a frontend special case, or worse, change the test expectation. The same failed test can produce disciplined recovery or test gaming.
LeoThat is a safety and reliability issue later in the series.
MayaExactly. The repair loop is powerful because it lets agents improve. It is risky because agents can learn to satisfy the local signal instead of the real intent.
LeoThe lesson is to record the repair, not just celebrate it.
MayaYes. Aider helps us see that coding capability includes the mechanics of editing and the discipline of responding to feedback.
LeoNext we move from benchmark workflow to product workflow with GitHub Copilot's cloud agent.
MayaBefore that, there is a useful distinction between repair and churn. Repair uses feedback to narrow the problem. Churn changes code because something failed, without a better hypothesis.
LeoThe logs can show the difference.
MayaExactly. A good repair turn says, "The failing assertion shows empty addresses are still accepted by the backend path, so I should inspect the shared schema." Churn says, "The test failed, so I will rewrite the form again."
LeoThat is a meaningful label for training.
MayaYes. A model-training team might want examples of disciplined repair and counterexamples of churn. But they need the trajectory to tell them which is which.
LeoAider's benchmark structure gives a clean version of that idea.
MayaRight. The model attempts an edit, receives test feedback, and has another chance. In larger agentic workflows, the same pattern repeats with more tools and more ambiguity.
LeoWhat should product builders take from Aider?
MayaMake edit delivery observable. If edits fail because of formatting, record that separately from logic failure. Make test feedback legible. If a second attempt improves the result, preserve that recovery as a valuable signal. If the agent changes unrelated files after a small failure, flag it.
LeoThat sounds like a bridge from benchmark to workflow.
MayaIt is. Aider reminds us that practical coding systems are judged at the boundary between model text and file system changes. The edit envelope is where language becomes software.
LeoAnd once language becomes software, verification and review have to take over.
MayaExactly. Aider's lens is valuable because it shows the moment where a model answer becomes an applied change, then meets a concrete signal from the environment.
LeoThat is the smallest visible loop of agentic coding.
MayaWhen a coding model fails its first attempt, what would you want the next turn to prove: better understanding of the task, better use of the tests, or better respect for the existing codebase?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents