Subscribe
Transcript
MayaSWE-agent reports 12.5 percent pass@1 on SWE-bench and 87.7 percent on HumanEvalFix — far above earlier non-interactive baselines — and the lever was not a bigger model. It was the interface the model had to work through.
LeoSo where did we leave issue resolution? We'd made it concrete with SWE-bench: an issue, a repository, an environment, a patch, and a fail-to-pass test.
MayaRight. And today SWE-agent asks what kind of interface helps a model actually move through that setup.
LeoAnd that gap shows up sharply.
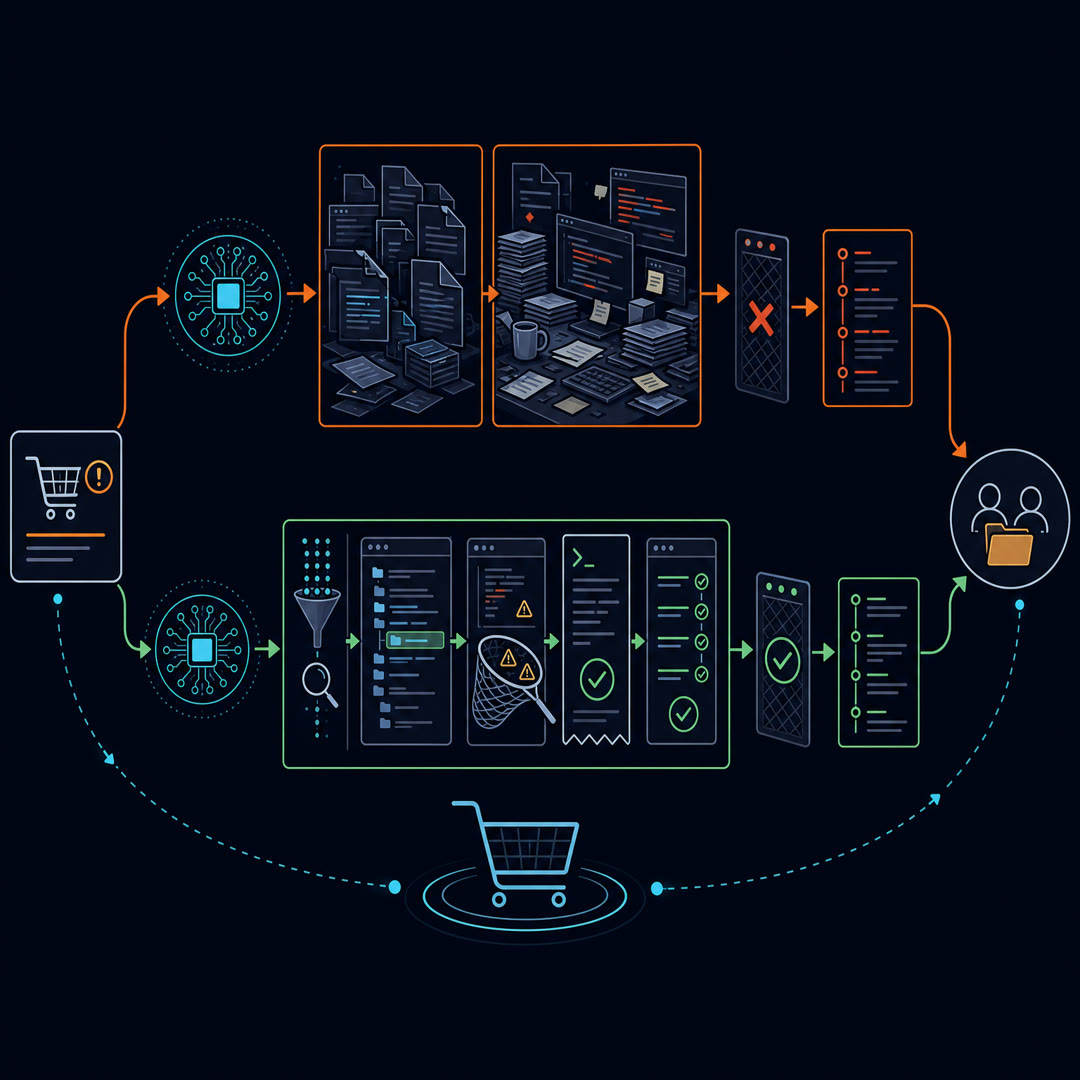
MayaTwo agents use the same base model on the same repository task. One gets lost in giant file dumps. The other moves through search, file views, edits, and tests with much less confusion.
LeoSame brain, different workbench.
MayaExactly. SWE-agent's key claim is that Agent-Computer Interfaces enable automated software engineering.
LeoSWE-agent is a system for letting language-model agents use a computer to solve software tasks, and its interface design is central to the result.

MayaRight. The SWE-agent paper argues that language-model agents are computer users with their own needs. They benefit from interfaces designed for how models read, decide, and act.
LeoThe first landmark is the LM-Centric Workbench.
MayaThe LM-Centric Workbench means the environment is shaped for the model, not simply copied from a human terminal session. A human can skim a file, use visual memory, and recover from a messy command. A language model needs structured, compact, explicit feedback.
LeoIn our express-checkout bug, that means the agent should get tools that help it search validation paths and inspect relevant code without flooding its context.
MayaExactly. The second landmark is the File Viewer Window. SWE-agent's documentation describes a custom file viewer rather than just printing whole files. It can show manageable slices and support scrolling and searching within the file.
LeoFor the express-checkout bug, that window matters because the agent needs the relevant validation code, not an overwhelming dump of every checkout file.
MayaExactly. A tuned viewer can keep the agent near the evidence: the matching function, the surrounding validation pattern, and the small patch area. That does not solve the bug, but it lowers the chance that the model wanders away from the useful context.

LeoThat sounds mundane, but it changes the agent's reading behavior.
MayaYes. If the agent sees too much, it may miss the key line. If it sees too little, it may make assumptions. A file viewer is a context-control device.
LeoThe third landmark is the Search Funnel.
MayaThe Search Funnel helps the agent find candidate files. SWE-agent's docs describe a directory search command that lists matching files succinctly. The design choice matters: too much context around every match can confuse the model, while a concise list can support a cleaner next step.
LeoSo search is not only retrieval. It is presentation.
MayaExactly. The fourth landmark is the Edit Safety Catch. SWE-agent uses checks around edit commands, including syntax validation through a linter. If an edit is syntactically invalid, the interface can block it before it enters the workspace.
LeoThat does not prove the fix is right.
MayaCorrect. It catches a cheap class of mistakes early. In agentic systems, cheap early checks matter because one bad edit can distort later observations.
LeoThe fifth landmark is the Quiet Command Receipt.
MayaThis is one of my favorite details. The docs describe returning an explicit message when a command succeeds but produces no output. Silence is ambiguous to a model. A receipt removes that ambiguity.
LeoA human might know "no news is good news" for a command. The model may not.
MayaExactly. This is why interface details can look small and still matter.
LeoWhat did the paper report?
MayaThose headline numbers — the 12.5 percent and 87.7 percent — come straight from the arXiv abstract for their evaluation. But they're a snapshot from the paper, not a permanent ceiling. The durable lesson is that interface design can change agent behavior and measured performance.
LeoThis is the model weights versus harness debate in concrete form.
MayaYes. One interpretation is "better interface unlocked latent model capability." Another is "we built a specialized harness that fits this benchmark." Both readings have some truth.
LeoGive each side its strongest argument.
MayaThe harness-optimist argument is that software work is interactive. If the agent cannot see files well, edit safely, or interpret output, even a strong model will waste effort. The harness-skeptic argument is that interface tuning can overfit to a benchmark or make systems brittle outside the designed workflow.
LeoSo a mature team should measure both: the model and the workbench.
MayaExactly. Do not attribute all improvement to the model if the tools changed. Do not dismiss tool design as mere plumbing if it changes outcomes.
LeoWhat should builders take from SWE-agent?
MayaAudit the interface from the model's perspective. Can it search without drowning? Can it read files in useful slices? Can it edit with guardrails? Can it run tests and understand the result? Can the system log enough trajectory data to learn from mistakes?
LeoAnd for the checkout example, a good ACI would encourage the agent to search, compare paths, patch narrowly, and verify.
MayaYes. A bad ACI might dump thousands of lines, accept broken edits, hide command status, and then blame the model for acting confused.
LeoThis episode makes "the harness is part of capability" feel less abstract.
MayaThat is the key. SWE-agent is not only a tool; it is evidence that the interface between a model and a repo can be a research object.
LeoNext we look at Aider, where edit formats and repair after tests become the center of the story.
MayaOne more useful lens is cost of confusion. Every confusing interface moment forces the model to spend reasoning on the wrong problem. Is the command done? Did the edit apply? Which file contains the match? Did the linter fail because of my patch or because the repo was already broken?
LeoThose are not the user's software problem. They are interface tax.
MayaExactly. A good ACI reduces interface tax so the model can spend more effort on the actual engineering task. But it also records enough detail that we can audit what happened.
LeoIs there a risk that an interface becomes too helpful?
MayaYes. If the harness supplies too much task-specific guidance, we may be measuring the harness author's insight rather than the agent's ability. If it hides too much complexity, the agent may look reliable only in that controlled setup.
LeoSo evaluation should report the tool environment, not just the model name.
MayaExactly. When a result says "model X solved Y percent," we should ask what interface, what tools, what context retrieval, what edit mechanism, what tests, and what retry policy were used.
LeoThat is the attribution discipline from the overview.
MayaRight. SWE-agent makes that discipline unavoidable. It shows that the difference between a capable run and a confused run may live in the workbench.
LeoAnd if we want training data, the workbench also determines what gets logged.
MayaYes. ACI design shapes both behavior and data collection. It is a control surface and an observation surface at the same time.
LeoThat is a good bridge to Aider, because edit packaging is both an action and an observable artifact.
MayaExactly. Once the interface asks for a structured edit, the system can tell whether the agent failed at reasoning, failed at formatting, or failed after verification. Those are different engineering problems.
LeoAnd different training signals.
MayaIf two coding agents use the same model but different interfaces, what evidence would convince you that one interface is genuinely teaching better engineering behavior rather than only fitting one benchmark?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents