Subscribe
Transcript
MayaIn the last three episodes we built the concepts: agentic work, Agent-Computer Interfaces, and trajectories.
LeoToday SWE-bench turns those concepts into a benchmark built from real GitHub issues and real repositories.
MayaA benchmark can ask a model to reverse a string, or it can drop the model into a real repository and say, "Here is the GitHub issue. Fix it."
LeoThat second one is SWE-bench.
MayaExactly. The full title asks whether language models can resolve real-world GitHub issues.
LeoPlain language version: SWE-bench tests whether AI systems can resolve real software issues in real codebases.
MayaYes. The paper and official benchmark page describe tasks built from GitHub issues and pull requests. The original dataset contains 2,294 task instances from 12 popular Python repositories. Each task gives the system an issue and a repository environment. The system edits the codebase, then tests check whether the issue appears resolved.
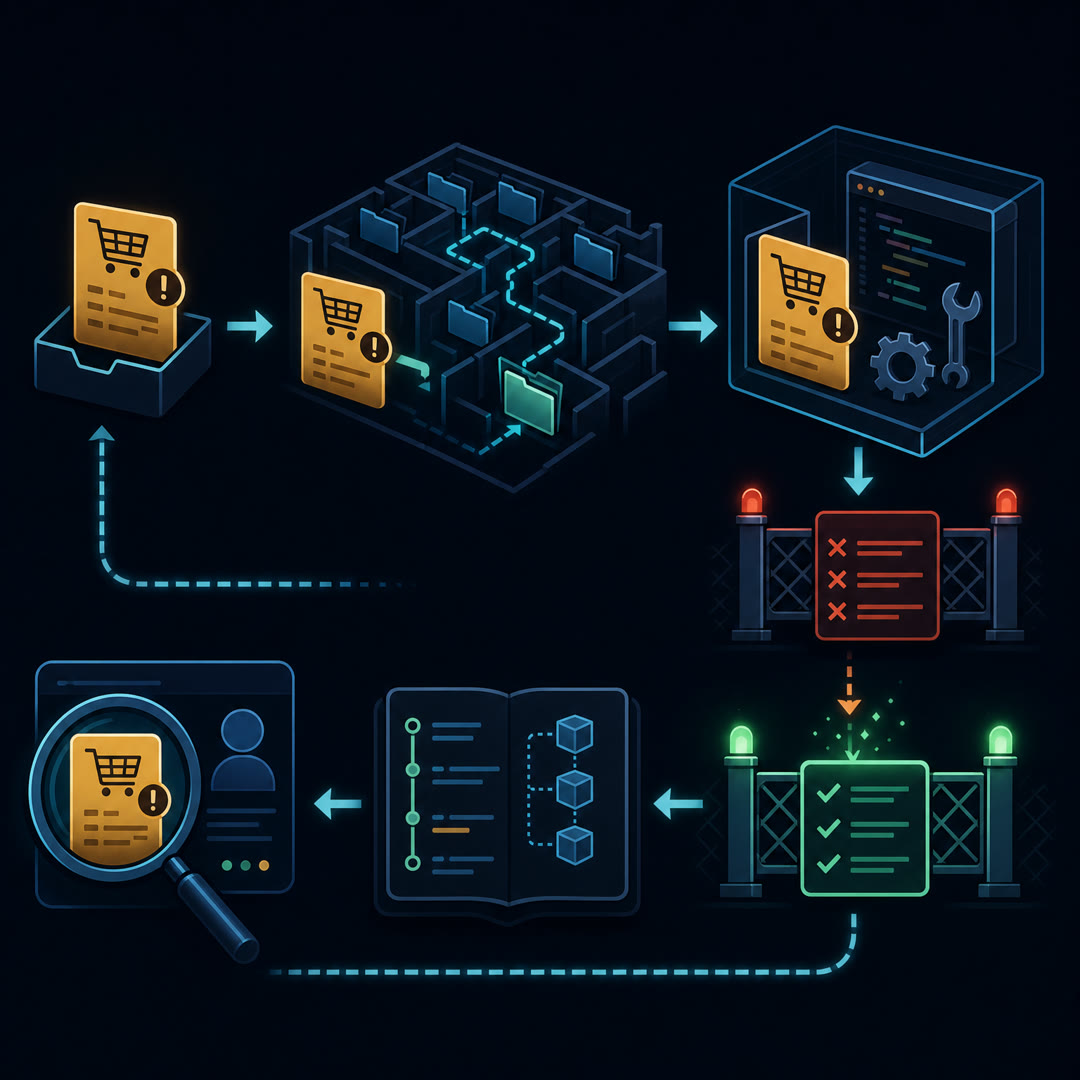
LeoThe first landmark is the Issue Door.
MayaThe Issue Door is the task description. It is not a neat programming exercise. It is a real issue report, with all the ambiguity that comes from human software projects.
LeoFor our express-checkout example, the issue might say, "Express checkout accepts blank addresses in production," but it might not identify the broken validator.
MayaExactly. A system has to infer where to look. That makes SWE-bench different from benchmarks where the relevant function is handed to the model.
LeoThe express-checkout case would only be a SWE-bench-like task if the system had to find the right repo path, not if the prompt handed it the validator.
MayaExactly. The benchmark pressure comes from uncertainty. The issue report gives the symptom, the repository gives the search space, and the tests give a partial signal. The agent has to connect those pieces without being told the implementation boundary.
LeoThe second landmark is the Repository Maze.
MayaThe Repository Maze is the codebase itself. Fixing a real issue may require navigating files, classes, tests, and dependencies. The paper emphasizes that resolving issues can require coordinated changes across multiple functions, classes, or files.
LeoSo the benchmark pressures repository-level reasoning.
MayaRight. A model that writes plausible code but cannot locate the right subsystem will struggle.
LeoThe third landmark is the Environment Box.
MayaThe Environment Box is the executable setup. The official SWE-bench page explains that task instances include an execution environment, often using Docker, with the repository installed at the relevant commit. That matters because code changes need to be tested where they actually run.
LeoThis is where agentic coding becomes more like software engineering. You cannot just answer; you have to interact with the environment.
MayaExactly. The fourth landmark is the Fail-to-Pass Gate. SWE-bench uses tests that fail before the pull request's changes and pass after the pull request is merged. An AI system's patch is evaluated by whether those fail-to-pass tests pass after its changes.
LeoThe gate is concrete. But it is still a gate, not the whole building.
MayaGood phrase. Fail-to-pass tests make evaluation scalable and objective, but they do not capture every dimension of software quality. A patch might pass the target tests while being overbroad, hard to maintain, or misaligned with the deeper intent.
LeoThat is the trade-off for this episode.
MayaYes. SWE-bench made repo-level issue resolution measurable, but test-based measurement can be incomplete. Later benchmarks and review methods try to cover more of the space.
LeoThe original paper also reported that early systems solved very little.
MayaRight. The arXiv abstract reports that the best-performing model in their original evaluation, Claude 2, solved 1.96 percent of issues. The important lesson is not that this number should be treated as today's capability. It is that the benchmark exposed how hard real issue resolution was compared with traditional code generation.
LeoIt created a before picture.
MayaExactly. Then agent systems and stronger models started pushing that picture forward.
LeoWhere does SWE-bench fit in the curriculum?
MayaIt anchors the move from "write code" to "resolve software work." It shows why tasks need a repo snapshot, environment, tests, and an outcome signal. It also shows why final outcome alone is not enough. If two agents both pass, we still want to know which one found the right files cleanly, which one made the smallest safe change, and which one got lucky.
LeoIn other words, SWE-bench gives us a scoreboard, but Topic 1 wants a work record too.
MayaExactly. The scoreboard says whether the fail-to-pass gate opened. The trajectory says how the agent approached the gate.
LeoWhat do experts disagree about with SWE-bench-style evaluation?
MayaOne side values public, reproducible benchmarks because they create shared comparison. Their strongest argument is that without a common testbed, everyone can cherry-pick success stories. The other side worries about benchmark saturation, contamination, and over-optimizing to test suites. Their strongest argument is that agents deployed in real products face fresh tasks, review constraints, safety rules, and messy production context.
LeoSo a good team uses SWE-bench as one lens, not the only lens.
MayaExactly. It is foundational because it made the problem concrete. It is not sufficient because software engineering is larger than passing a selected test set.
LeoWhat should a listener remember?
MayaSWE-bench reframed code evaluation around real issues, real repositories, executable environments, and fail-to-pass tests. It is one of the reasons agentic coding became a measurable field rather than a collection of demos.
LeoAnd it sets up SWE-agent, because once the task is interactive, the interface starts to matter.
MayaThere is also a subtle data lesson. SWE-bench tasks are not only prompts. They are tied to repository commits, environments, tests, and historical fixes. That makes them closer to replayable work than a static question-answer dataset.
LeoBut the replay is still bounded by the benchmark's design.
MayaExactly. The benchmark has to choose what counts as success. Fail-to-pass tests are a strong signal, but they are not the same as a full maintainer review. They may miss style, architecture, security, or broader regression risk.
LeoSo if a model optimizes too tightly to that gate, it may become good at opening that gate.
MayaRight. That is not an argument against the gate. It is an argument for knowing what the gate measures. A good benchmark tells you something specific. A bad interpretation turns that specific signal into a claim about all software engineering.
LeoWhat would a stronger evaluation package add?
MayaHidden tests, trajectory analysis, human review, code-quality rubrics, safety checks, and fresh private tasks. Each adds a different lens. The goal is not to make one perfect metric. The goal is to reduce blind spots.
LeoIn our checkout example, the fail-to-pass test might prove blank addresses are rejected. A reviewer might notice the error message is confusing or the patch duplicated validation logic.
MayaExactly. Those are different truths about the same patch.
LeoThat helps explain why SWE-bench belongs in Topic 1 and Topic 2 at the same time.
MayaYes. In Topic 1, it teaches what repo-level work looks like. In Topic 2, it becomes part of the evaluation conversation. Here we are using it as the foundation: real issue, real repo, environment, patch, test signal.
LeoThen SWE-agent asks what kind of interface helps the agent move through that setup.
MayaWhen a coding-agent benchmark reports that a task passed, what extra evidence would you want before trusting that patch in a production repository?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents