Transcript
MayaAn interpreter takes a posting in Lisbon. Portuguese all day, every day — meetings, contracts, dinner parties. Ten years in, she's brilliant at it. And then one weekend, on the phone with her sister back home, she catches herself groping for an ordinary word in her own first language.
LeoOh, that's real.
MayaVery real — linguists call it first-language attrition. And the unsettling part is how quiet it is. She still sounds fluent. Nothing crashed. The new practice just kept writing over the old, a little at a time, and nobody scheduled the loss.
LeoThat phone call is today's episode. Train a model hard on new material and its old abilities fade the same way — gradually, silently, no error message.
MayaThe source is a survey — Continual Learning of Large Language Models: A Comprehensive Survey — and it maps this whole territory: how a pretrained model keeps adapting to changing data, tasks, and user preferences without serious damage to what it could already do.
LeoWhich is exactly where last episode left us hanging. LowRA squeezed a single adaptation under two bits per number — adaptation got cheap. But cheap was never the same as repeatable. Today's question is not how you specialize once — it's how you specialize fifty times, across two years, and still trust the result.
MayaSo name the villain properly. Catastrophic forgetting: train on the new task, lose capability on the old ones. In a toy setting it's blunt — teach task A, then task B, and performance on task A collapses.
LeoBut a large language model doesn't have one old task. The "old task" is everything — grammar, coding style, safety behavior, entire domains of knowledge.
MayaWhich is why forgetting here is rarely a collapse. It's erosion with good manners. The model stays articulate while a previous domain quietly gets worse — or keeps the facts but loses its formatting discipline, or leans so far into one customer's style it's less useful everywhere else.
LeoHospital floor, then — make that concrete. Our discharge-note summarizer gets retrained on the newest guideline revision. The new summaries read beautifully. Three weeks later, pediatrics notices that an exclusion rule from two revisions back has started... slipping.
MayaAnd nothing in the training loss flagged it. That's the interpreter on the phone — fluent, confident, and quietly missing a word.
LeoRight.
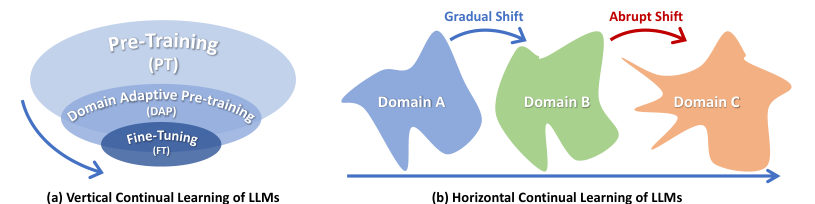
MayaThe survey hands you two axes for organizing all of this. Vertical continuity is the apprenticeship direction: general language model, then instruction-follower, then domain assistant, then task-specific helper. Each step narrows the job and deepens the skill.
LeoGeneral to specialized. And the other axis?
MayaHorizontal continuity is keeping up with the world. New laws, new products, new codebases, new slang. The job doesn't get narrower — the ground moves sideways underneath it—
Leo—and the model has to keep walking. Two different reasons to touch the weights, and I'd bet two different risk profiles.
MayaYou'd win the bet, and the survey crosses those axes with stages. Continual pretraining: keep the broad training going as fresh general data arrives. Domain-adaptive pretraining: keep training, but on one domain's text — legal filings, biomedical papers — before any task-specific tuning. Continual fine-tuning: keep updating on a sequence of tasks or instruction data.
LeoAnd each stage breaks in its own way. Continual pretraining can shift the broad representations everything else stands on. Domain-adaptive pretraining sharpens the domain's language but can over-specialize. Continual fine-tuning learns the new task fastest — and that speed is what bulldozes the older ones.
MayaWhich lands us on the survey's central tension: plasticity and stability. Plasticity means the model can still learn new things. Stability means it doesn't lose old ones.
LeoToo stable, it can't adapt. Too plastic, it forgets. That's not a bug — that's a dial somebody has to set on purpose.
MayaAnd setting it on purpose is the whole discipline. Continual learning is not "just train more." It's controlled updating under memory, compute, and evaluation constraints — old performance is part of the objective, not a casualty of it.
LeoAlright, the toolbox. What does the field actually do about forgetting?
MayaFour families, and I'll hang a picture on each. The Songbook — rehearsal. Keep a folder of yesterday's material and mix it back into today's training, the way a choir runs old repertoire before learning the new piece. The model re-practices what it must not lose.
LeoCosts storage, and somebody has to decide what earns a place in the folder. Next.
MayaThe Tether — regularization. Let the weights move toward the new task, but penalize the moves that strain whatever the old tasks depend on. Freedom, on a leash.
LeoWith the leash length being a setting somebody has to defend in review. Keep going.
MayaThe New Wing — parameter isolation. Don't renovate the old building; give the new task its own fresh parameters and leave the rest standing. And if that sounds familiar, it should. Adapters are exactly this. Topic 4 has been building the New Wing all along.
LeoWhich is why the topic ends on this survey. Parameter-efficient fine-tuning isn't only cheaper — keeping each update in its own small file is itself a forgetting defense.
MayaWith one catch we shouldn't skate past: isolation is not integration. If the job needs knowledge combined across those separate wings, or generalization to a task no wing covers, the walls stop helping and start being the problem.
LeoAnd the last family?
MayaThe Diet — data and curriculum strategies. Control what the model eats, in what order, in what proportions. The least glamorous family and, in practice, half the battle, because continual learning is substantially a data engineering problem. What do you store, what do you replay, what do you delete, what gets weighted up?
Leo[chuckle] Every grand machine learning idea eventually confesses to being a data pipeline.
MayaThis one confesses early. Now — the argument the field genuinely has, because the survey sits on a real split. When the world changes, does the learning belong inside the weights at all? Or outside the model, in retrieval and tools?
LeoI'll take outside, and not reluctantly. Weights are a terrible database. A refund policy changes on Tuesday — in a retrieval index it's live that afternoon, I can read the entry, I can delete the entry, and on Thursday I can prove what the system knew on Wednesday. Bake it into weights, and the update is slow, the audit trail is a shrug, and revoking it is a research project.
MayaAnd when the thing that changed isn't a fact? A new reasoning pattern. A house style. The clinical instinct for what a discharge summary must never contain. You cannot staple "be a careful pediatric summarizer" into a context window and get behavior. Retrieval hands the model a note card — it doesn't change what the model is.
LeoMost of what teams call "the model needs to learn" is facts wearing a costume! Product docs, policy text, user records — that's lookup, and lookup wants an index—
Maya—and what's left over is the part that makes it an assistant instead of a search box. Fluency. Integration. Judgment under the new regime. That has to be internalized, and the weight-update camp is right about it.
LeoFine — behavior, style, domain instinct: those live in weights, I'll concede it. A note card never made anyone careful. But anything with a revision date — facts, prices, policies, the law — concede it back, because fresher, inspectable, and revocable wins there every time.
MayaConceded, without much pain — because the survey's practical answer is the split itself. Weights for stable behavior patterns. Retrieval for fast-changing knowledge. The deciding question is half-life: how long does the thing you're teaching stay true?
LeoHalf-life. That's the rule I'd paint on the wall.
MayaThere's a second argument stacked right behind it: one continually updated model, or many specialized ones? And this time I'm taking a side first — give me the one model. Transfer is my card. Skills compound: what it learns in one domain sharpens the next, and every update makes the whole thing smarter. Wall the updates off into separate adapters and you forfeit the compounding—
Leo—and keep the blast radius! One bad update in your shared model poisons every user it has, every department, the same Tuesday. My bad adapter gets unplugged before lunch.
MayaUnplugged, sure. But your fifty little specialists never teach each other anything. Each wing relearns the world from scratch.
LeoFine — transfer is real, I'll give you that, and a research lab chasing capability should let one model evolve. But the tiebreaker isn't technique, it's governance. An enterprise that has to audit, explain, and roll back takes my contained adapters and sleeps at night.
MayaAnd that one I'll hand back to you — because it's where the survey effectively lands: the right architecture depends on who has to answer for the model's behavior.
LeoAnd none of it is trustworthy without measurement, so let me say the quiet part loudly. The new-task score — the number everyone celebrates — is the least informative number on the sheet. You need old-task retention. Transfer to related tasks. Forgetting measures. Benchmarks that know what time it is.
MayaMm-hm.
LeoPlus the behaviors no training loss ever sees. Does it still follow instructions? Still refuse what it should? Is its confidence still calibrated? Did the safety policy survive the update?
MayaUnderneath all of that sits a definitional question: what counts as forgetting? A legal assistant that gets better at statute language and slightly worse at casual jokes — acceptable. Worse at basic arithmetic — not acceptable, ever.
LeoSo forgetting isn't a single number; it's a product requirement. Somebody has to write down which capabilities are load-bearing before the first update ships.
MayaAnd one trap deserves its own warning label: leakage. A model that keeps training on a moving stream of data will eventually see benchmark-flavored text. The scores climb, and you think it's getting smarter. It's getting familiar.
LeoSame lesson Topic 2 taught — more data is not better data if the stream is biased, duplicated, or marinating in your test set. Evaluation rots quietly unless the pipeline defends it.
MayaRun the whole survey through one system before we close. A coding assistant, trained in twenty twenty-four. By twenty twenty-six the frameworks, the package versions, and the security practices have all moved.
LeoNever update it, and it confidently recommends last year's vulnerabilities. Update it aggressively on whatever is newest, and it overfits to noise — or quietly drops the older languages half its users still write.
MayaA sane build uses the whole toolbox at once. Retrieval for the latest documentation — that's your index, Leo. Periodic domain-adaptive training for ecosystem shifts that have proven stable. Adapters for customer-specific codebases. And a regression suite standing guard over everything that used to work.
LeoAnd bring it back to the hospital, because the lifecycle is the real lesson of this survey. What triggers a retrain of the discharge summarizer? A new guideline revision. A dip in evaluation. An incident report. Then a candidate adapter runs the gauntlet — old notes and new notes both — and a human with the authority to say no inspects the failures before anything ships.
MayaWith the rollback path rehearsed before it's needed, not after.
LeoVersions, regression tests, release notes, rollback plans, monitoring after deployment. At some point you squint and realize the model lifecycle has turned into the software lifecycle.
MayaBecause it is one. The model stops being a finished artifact and becomes a managed, evolving system — that's the survey's quiet thesis.
LeoOne misconception worth retiring on the way out: continual learning does not mean the model learns live from every user interaction.
MayaIn high-stakes systems that reading is usually dangerous. You want curation, privacy controls, evaluation gates, rollback plans. Continual means the lifecycle keeps going after deployment — it never meant uncontrolled.
LeoAnd it closes Topic 4's arc cleanly. LoRA made the update small. QLoRA made the frozen base cheap to hold. LowRA squeezed the update itself down to almost nothing. This survey asks what all those cheap updates add up to over a model's lifetime.
MayaSpecialization is not a button you press once. It's a standing negotiation between new usefulness and old reliability — and the topics ahead keep renegotiating it, from preference feedback to open-model ecosystems to how much adaptation belongs in system code rather than in weights at all.
LeoSo carry this one out the door. The next time a system you run learns something new — what would it take to prove, not just hope, that nothing important quietly slipped away?
Source material
← Back to Mastering Language Models: From Architecture to Optimization