Transcript
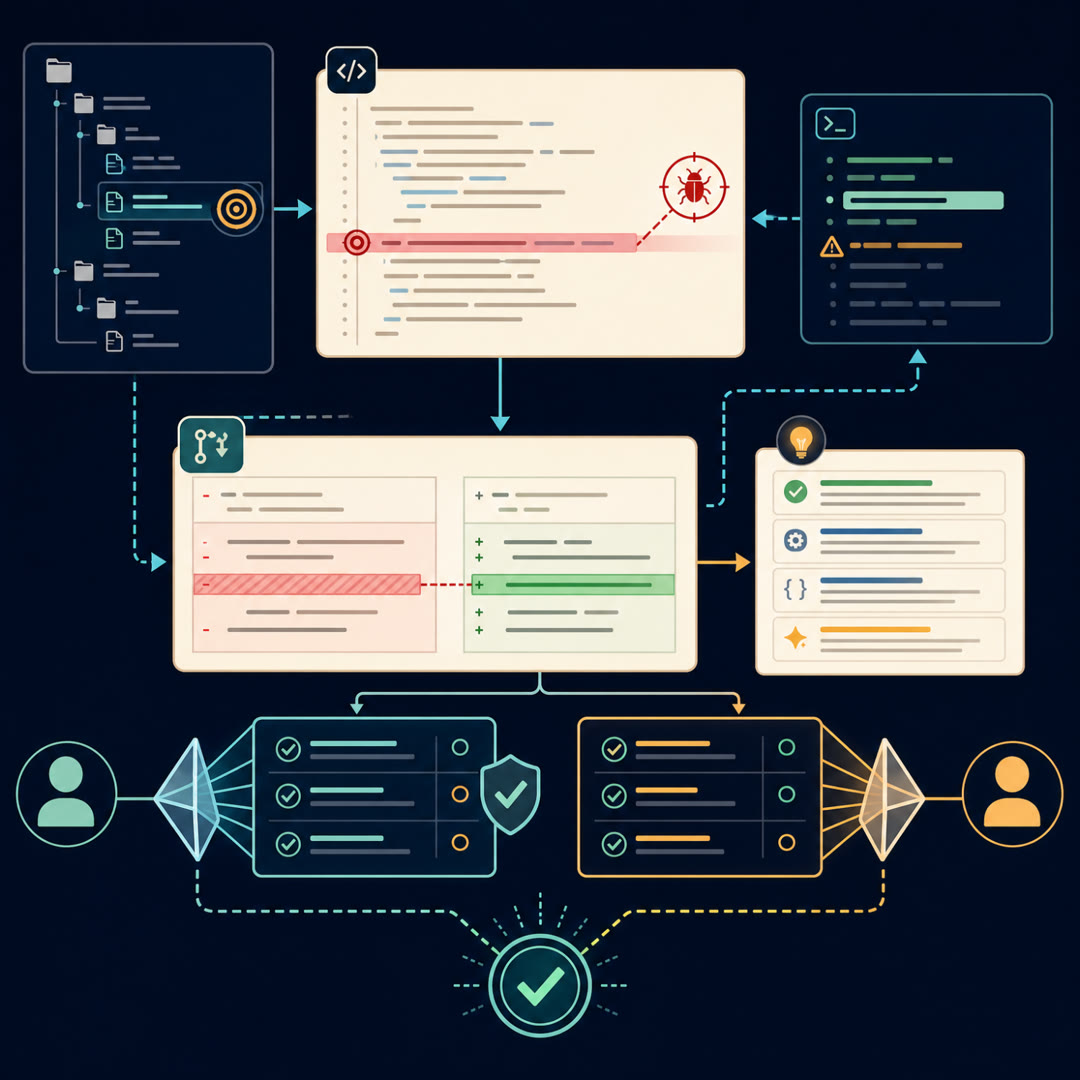
MayaImagine a pull request where someone has quietly planted a bug — a known, deliberate bug, on a line you could circle on a printout. Now you hand that diff to a review model and ask one question: did it flag *that* line. Not "did it say something smart." Did it land on the bug we already know is there.
LeoOh — so the answer key exists *before* the model reviews. We're not arguing about whether the comment was insightful. We checked it against a planted defect we put there on purpose.
MayaThat's the whole move of today's source. CodeReviewBench scores a reviewer against bugs it already knows the location of, and then has language models grade whether the reviewer actually caught them.
LeoLast time we looked at SWE-PRBench, and its move was grounding review in human-annotated pull requests — real reviewers had flagged real issues, and the question was whether an agent finds what those humans flagged.
MayaToday's source sharpens the cost side of that. Human annotation is expensive and slow. CodeReviewBench asks: can we build a review benchmark that's fully deterministic and auditable — where every score, every trace, every judge's reasoning is published so you can re-check it yourself — by leaning on known bugs and model judges instead of a human annotator in the loop.
LeoOkay, before we run — give me the plain version of "model judges." What's actually doing the grading?
MayaSo the reviewer model leaves its comments on a diff. Then two *separate* language models read those comments and score them — one judge from one lab, one from another — and the benchmark averages the two. The idea is that one judge alone might be quirky, but two independent judges agreeing is harder to fluke.
LeoTwo graders, different houses, and you trust the average more than either alone.
MayaRight. It's the same instinct as asking two reviewers instead of one. And critically, the reviewer's free-text comments get parsed into structured suggestions first, so the judges aren't grading vibes — they're grading "did this specific claimed bug match a real one."
LeoLet me set my listening map so I don't lose it on a walk. What are we walking through?
MayaThree landmarks. The planted-bug bench — how the test cases are built. The coverage-versus-validity dial — the two numbers that matter most. And the audit room — why this benchmark is so loud about publishing everything.
LeoPlanted-bug bench, coverage-versus-validity dial, audit room. Got it.
MayaStart with the bench. A test case here is a diff with one or more known defects in it, drawn from a spread of real-world languages — TypeScript and Node, Python, React, Ruby, Java.
LeoSo it's not all Python-fixes-a-Django-bug, the way a lot of these benchmarks drift.
MayaNo, and that breadth is deliberate. A reviewer that's sharp on Python type errors might be hopeless on a React component or a Ruby idiom. Spreading languages stops one ecosystem from flattering the score.
LeoOkay, and there's a split in *kinds* of bugs too, right? Not all bugs are the same shape.
MayaThat's the part I'd underline. CodeReviewBench separates two bug families, and they test very different muscles. The first is local logic — a bug that lives entirely inside one file. An off-by-one, a wrong comparison, a missing null check. Everything you need to catch it is right there on the screen.
LeoAnd the second is the nasty one.
MayaCross-file context. Picture our running example — a fix to an open-source data library. Someone changes the signature of an internal function, and that change quietly breaks three callers in other files that the diff doesn't even show you.
LeoOh, that's the one that gets shipped. The diff looks clean and self-contained, and the damage is offstage.
MayaExactly. To catch a local-logic bug you just read the diff carefully. To catch a cross-file bug you have to hold a model of the whole repository in your head — who calls this, what depends on it. CodeReviewBench scores cross-file as its own isolated metric, because that's where the easy reviewers fall apart.
LeoSo a model could look strong overall and still be blind to exactly the bugs that hurt most.
MayaAnd separating the metric is how you'd catch that. A high local score with a weak cross-file score tells you precisely what kind of reviewer you have — a careful reader who can't see around corners.
LeoQuick recap: a bench of diffs with known bugs, across five language worlds, split into "in this file" and "reaches into other files."
MayaWhich sets up the second landmark, and this is the heart of it — the coverage-versus-validity dial.
LeoThese sound like the recall-and-precision pair we keep circling back to in this topic.
MayaThey are exactly that, dressed in plain clothes. Coverage asks: of all the bugs we planted, how many did the model actually find. Miss half of them, your coverage is low — you're a reviewer who skims.
LeoAnd validity?
MayaValidity flips the camera around. Of everything the model flagged, how much was real. If it raised ten alarms and only three were genuine bugs, validity is low — you're a reviewer who cries wolf.
LeoAnd the trap is you can game either one alone.
MayaThat's the whole reason you need both on the same dial. Want perfect coverage? Flag every single line as suspicious — now you've caught all the bugs, and buried them in noise, so validity craters. Want perfect validity? Only flag the one bug you're absolutely certain about, stay silent on everything else — now every alarm is real, but coverage collapses because you missed the rest.
LeoHmm. So neither number means anything without its partner. A reviewer is only good if it's catching most of the real bugs *and* most of what it says is true.
MayaAnd that's why CodeReviewBench reports an overall quality score that the judges produce, plus coverage and validity standing next to it, plus a pass rate — did the reviewer clear a minimum bar on each case at all.
LeoLet me make sure I've got the contrast with a patch benchmark sharp, because I always want that line clear. On SWE-bench, the agent writes code and the hidden tests decide. Here?
MayaHere the agent writes *opinions about someone else's code*, and there's no green checkmark to settle it. You can't run a test to see if a review comment is "correct." So CodeReviewBench substitutes the model judges for the missing test oracle — that's the load-bearing design choice, and also, as we'll get to, its biggest soft spot.
LeoRecap for me: two dials, coverage and validity, and a good reviewer has to win both at once or it's gaming the test.
MayaWhich brings us to the third landmark — the audit room. And this is where CodeReviewBench plants a flag that's almost philosophical.
LeoGo on — what's the flag they're planting?
MayaThe project's stated principle is, roughly — no cherry-picking, no human scoring, no prompt tricks. Just deterministic evaluations you can audit yourself. Every score, every reviewer trace, every judge's reasoning is published.
LeoOh, that's a direct shot at the demo culture. "Here's our model crushing code review" — with the three good examples and none of the embarrassing ones.
MayaRight. The bet is that if you publish the full trace explorer — here's exactly what the reviewer said, here's exactly why each judge scored it the way it did — then nobody has to take the leaderboard on faith. You can go read the disagreements yourself.
LeoAnd that's actually a different value than the score itself. The score tells you who won. The published traces tell you *whether to believe the score*.
MayaThat's the elegant part. Determinism plus full disclosure means the benchmark is trying to be falsifiable. If you think a judge scored a comment wrong, the evidence is right there for you to argue with.
LeoOkay. I can feel the limitation coming, though, and I think it's sitting right under the audit room.
MayaIt is, and every one of these episodes owes one, so let me name it plainly. The judges are language models. The entire benchmark rests on two models reliably telling a real bug-catch from a plausible-sounding wrong one — and that's the exact thing language models are sometimes bad at.
LeoSo the grader could be fooled by a comment that *sounds* like it found the bug but actually points at the wrong line.
MayaOr the reverse — a terse but correct comment the judge underrates because it isn't dressed up. This is the known weakness of any model-as-judge setup. Publishing the judge reasoning helps, because you can catch a bad call. But it doesn't make the judge right; it just makes the judge *auditable*.
LeoAnd there's a coverage-of-bugs limit too, isn't there. These are planted, known defects.
MayaGood catch. A known-bug bench can only test you on the bugs someone thought to plant. Real review also means catching the defect nobody anticipated — and a benchmark built around a fixed answer key, by construction, can't score you on the surprise you weren't supposed to find.
LeoSo it's honest about *known* bugs and quiet about *unknown* ones. Which is the opposite blind spot from a human-annotated set, where the humans at least flagged whatever they actually noticed.
MayaWhich is exactly why this and SWE-PRBench are complementary, not rivals. One trades human breadth for deterministic, auditable, cheap-to-rerun scoring. The other trades that determinism for the messy realism of what humans truly flagged. Neither one is the whole truth.
LeoRecap the audit room for me: it's loud about publishing everything so you can check it, and the thing you most need to check is whether the model judges judged fairly.
MayaCouldn't say it better.
LeoGive me the memory hook before we close.
MayaHere it is. CodeReviewBench turns code review into a thing you can audit — known bugs, two judges, full traces in the open. It buys you cheap, repeatable, falsifiable scores. The price is that your answer key is finite and your graders are models. So read the leaderboard, then read the traces.
LeoAnd that lands right back on the series promise — collect the whole story, not just the number. For review, the story is which bugs were planted, which got caught, which alarms were false, and why two judges scored it the way they did.
MayaExactly. CodeReviewBench's gift is putting all of that in the open so the score has something to stand on.
LeoHere's the question I'll leave for everyone listening: if you could see the full reasoning behind every score on a leaderboard, would you trust a benchmark graded by two models you can audit — or hold out for human annotators you mostly have to take on faith?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents