Transcript
MayaPicture a senior engineer opening a pull request first thing in the morning. Not a tidy little bug — a real one, many files touched, a config change, a renamed function, an edge case buried three layers down. She reads the whole thing and leaves four comments. One says, "this breaks the empty-input path." Now hand that exact same pull request to a coding agent and ask: which of those four comments can you find on your own?
LeoAnd that question is the whole episode, isn't it. Not "can you write the patch" — "can you stand where the reviewer stood and see what she saw."
MayaThat's exactly it. Today's source is a benchmark called SWE-PRBench, and its move is to grade an agent against what real reviewers actually flagged, on whole, real pull requests.
LeoOkay, but anchor where we are first, because last time we were in a slightly different room.
MayaRight. Last time was CR-Bench — and that one zoomed in tight. It took defects, labeled each with a category and a severity, and watched the trust meter: how much noise per real catch. The reviewer's desk under a magnifying glass, one finding at a time.
LeoAnd today's source pulls the camera back.
MayaWay back. CR-Bench asked, "given a defect, how well do you describe it." SWE-PRBench asks the messier version: "here is an entire pull request as a human submitted it — go find everything a careful reviewer would have said."
LeoSo it's the same job, code review, but on the real unit of work.
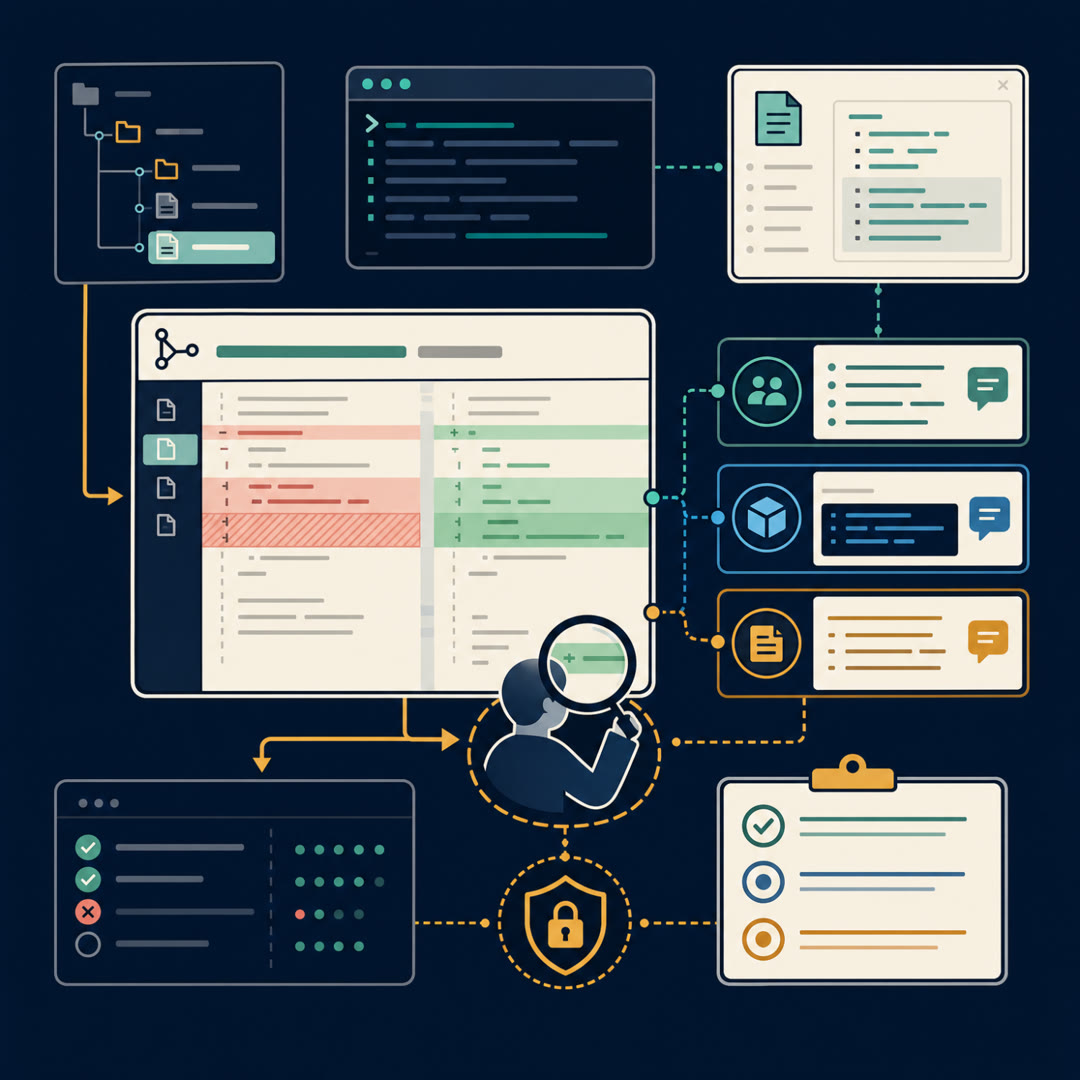
MayaThe real unit. That's the key word for today — whole-PR realism. Let me put it in plain language before we get fancy. Most of the famous coding benchmarks evaluate issue-fixing. You hand the agent a bug report, it produces a patch, and hidden tests decide pass or fail. That's generation. SWE-PRBench is about the next desk over — the stage after someone has already written the change, and now it needs review before it can merge.
LeoSo it's not "fix this." It's "judge this."
Maya"Judge this." And the thing being judged is a genuine pull request, multi-file diff and all, from real open-source repositories.
LeoHmm. Let me push on the realism word, because benchmarks love to claim it. What makes a pull request realistic versus a sanitized toy?
MayaFair challenge. Three things, all from using actual merged-and-reviewed history. The diff isn't one neat function — it's spread across many files, the way real changes are. The ground truth isn't invented by the authors; it's the comments human reviewers actually left on that PR before it shipped. And these are PRs that went through the real merge-or-reject gauntlet, so the comments mattered — they changed what happened to the code.
LeoOh, that's the part I find clever. The label isn't "here's a bug we planted." It's "here's what a person who cared about this codebase chose to say out loud."
MayaExactly. And that's harder than it sounds, because human comments are all over the map. Some are bugs. Some are "this will be slow at scale." Some are "this design will hurt us in six months." A planted-bug benchmark only tests the first kind.
LeoSo how do they actually build this? Because "scrape pull requests and their comments" sounds easy and is probably a nightmare.
MayaIt is, and how they handle it is itself the interesting engineering. They start from a large pool of candidate repositories and filter hard — the paper describes a repository quality score to keep only well-maintained projects, because a sloppy repo gives you sloppy review history. Out of that, they land on a curated set of a few hundred pull requests with expert annotations.
LeoA few hundred — so this is the hand-built, high-trust kind of benchmark, not the scrape-a-million kind.
MayaRight, it's deliberately on the smaller, carefully-vetted side. And here's a detail I want to flag honestly, because it's a methods choice you should know about: to decide whether an agent's comment actually matches a human's comment, they don't do exact string matching — that would be hopeless, since two people can say "this is a memory leak" a hundred different ways. They use a model as the judge. An LLM-as-judge setup that reads the agent's comment and the human's comment and decides, do these point at the same thing.
LeoAnd that's the part where I get a little nervous. You're using a language model to grade language models.
MayaYou should be a little nervous, and the authors clearly were too, because they report an agreement check — how often the automated judge lines up with human raters. They cite a kappa around the mid-point of the scale, which in plain terms means substantial agreement, not perfect. So it's a real signal, but it's a judged signal, not a tests-pass-or-fail oracle.
LeoLet me restate that for myself. In issue-fixing benchmarks, the oracle is a test suite — cold, objective, no opinions. Here the oracle is "did a model think you matched a human," backed by spot-checks against actual humans.
MayaThat's the trade the moment you leave generation and enter review. There's no test that passes when you correctly say "this design is risky." So review benchmarks accept a softer, judged oracle — and the best they can do is measure how trustworthy that judge is and show you the number.
LeoOkay. So they built the thing. What does it actually tell us when frontier models sit down and take the test?
MayaThe headline is humbling, and it's the reason this benchmark exists. When the models get just the diff — the raw change, nothing else — they catch only a minority of the issues humans flagged. A small fraction, well under a third, across a spread of strong frontier models.
LeoWait. Under a third. So if a human reviewer left ten comments, the agent is reliably finding maybe two or three of them.
MayaOn the diff-only setting, roughly that ballpark. And the spread between the best and worst models was real but not gigantic — the top cluster of models scored close together, then a clear step down to the rest. Which tells you this isn't solved by just picking a slightly better model. Everybody is far from the human line.
LeoThat's a very different picture from issue-fixing, where the leaderboards have been climbing toward the ceiling.
MayaCompletely different picture. And that gap is the argument for why review deserves its own benchmark. An agent can be excellent at writing a patch that passes hidden tests and still be near-blind at spotting what's wrong with someone else's patch. Those are different muscles.
LeoNow you said "diff-only setting," which implies there are other settings. What happens when you give the agent more to work with?
MayaThis is my favorite finding, because it's so counterintuitive. They ran the same models with more context — not just the diff, but the surrounding file contents, and then a full-context version with even more. Common sense says more context, better review. More to see, more bugs found.
LeoSure. That's how I'd bet.
MayaIt went the other way. Scores degraded as they piled on context. The leaner, structured prompt — the diff plus a tight summary — beat the bigger, fuller prompt across the models they tested.
LeoHuh. So drowning the model in the whole repository made it a worse reviewer, not a better one.
MayaThe authors read it as attention dilution. When the review-relevant lines are surrounded by thousands of tokens of mostly-irrelevant file content, the model's focus spreads thin and it misses what it would have caught in a tighter frame. The reviewer equivalent of being handed the whole codebase when all you needed was the changed function and its callers.
LeoThat's a real lesson for anyone building a review agent. The instinct to "just give it everything" can actively hurt you.
MayaIt can. And it reframes agent design. We assume the bottleneck is "the model can't see enough." Here it flips — the model can't focus enough. Curating what the reviewer looks at becomes the engineering problem, not maximizing it.
LeoLet me connect this back to our running example, because I want to make sure it's concrete. We've been carrying this fix to an open-source data library all topic — the patch that passes the empty-and-common case but silently disables refunds for one currency.
MayaPerfect case. Imagine that patch comes in as a real pull request. The hidden tests are one gate — and the patch sails through them, because the tests never covered that one currency. SWE-PRBench asks the other question: would a review agent, reading the diff, leave the comment a sharp human reviewer left — "wait, this branch skips the refund path for this case"?
LeoAnd on the evidence, the answer is usually no. The agent catches the easy, local stuff and misses exactly that kind of subtle, intent-level concern.
MayaWhich is the most expensive kind to miss. The bug that passes every test and still shouldn't merge. That's the hole SWE-PRBench is built to shine a light into.
LeoOkay, I want to be fair to the benchmark, so let's do the limitations honestly. We touched the judged-oracle issue. What else should a careful listener hold lightly here?
MayaA few. The judged oracle is the big one — matching is done by a model, validated against humans, but it's still a model's opinion of "same issue," and edge cases will be fuzzy. Second, the ground truth is human comments, and reviewers aren't omniscient — they miss things too, and they leave style nitpicks alongside real defects. So "matching the human" is the target, but the human isn't a perfect ceiling.
LeoRight, you're benchmarking against a noisy gold standard, not a true one.
MayaAnd it's a curated few-hundred-PR set from open-source projects. Great for quality, but the distribution is open-source review culture — it may not capture how review happens inside a company with private context and its own conventions. So a strong number here is real evidence, but evidence about this slice of the review world.
LeoThat's a healthy way to hold it. It's a sharp instrument pointed at one important place, not a verdict on everything review.
MayaAnd that's the through-line of this whole topic. Each benchmark is one instrument shaped to see one kind of work. SWE-PRBench finally puts the agent in the reviewer's chair on a real, whole pull request, and the number it returns — agents catching only a slice of what humans flag — is the field saying out loud, "review is still mostly an open problem."
LeoIt's a useful kind of humbling. The patch-writing leaderboards made it feel almost solved. This one reopens the question.
MayaIt reopens it on exactly the part that matters most — the judgment, not the typing. Which leaves me with the question I'd hand to you, and to anyone listening.
LeoGo for it — and make it the one that actually keeps it turned on.
MayaIf your code review agent could either catch one more subtle, intent-level bug per pull request, or cut its noisy comments in half — knowing it can't do both — which one would actually make your team trust it enough to keep it turned on?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents