Subscribe
Transcript
MayaPicture a developer at three in the afternoon, twelve pull requests deep, staring at a tiny diff — somebody changed one line in a config loader. And the question in her head isn't "does this compile." It's "is there anything worth saying about this change?" And then, if there is, "what exact sentence do I type into the review box?"
LeoRight, and that second part is the sneaky one. Knowing something's off is one skill. Producing the comment a teammate will actually read and act on — that's a different muscle.
MayaThat's the whole move today. Today's paper takes that messy human act — read a code change, decide if it's good, write the review note, maybe even fix it — and asks: can we pre-train a model specifically on that, instead of on plain code?
LeoSo not "model that writes code." Model that reviews code.
MayaExactly. And the lever is the training diet.
LeoOkay, before we dive — last time?
MayaLast time we walked the whole family of code-review benchmarks — a staircase of rising bars, from "write a plausible comment" up to "be trusted in production" — and the twist was that, unlike a patch benchmark, a review benchmark has no green checkmark. No oracle. Each one invents its own ground truth.
LeoAnd today we step onto the bottom stair.
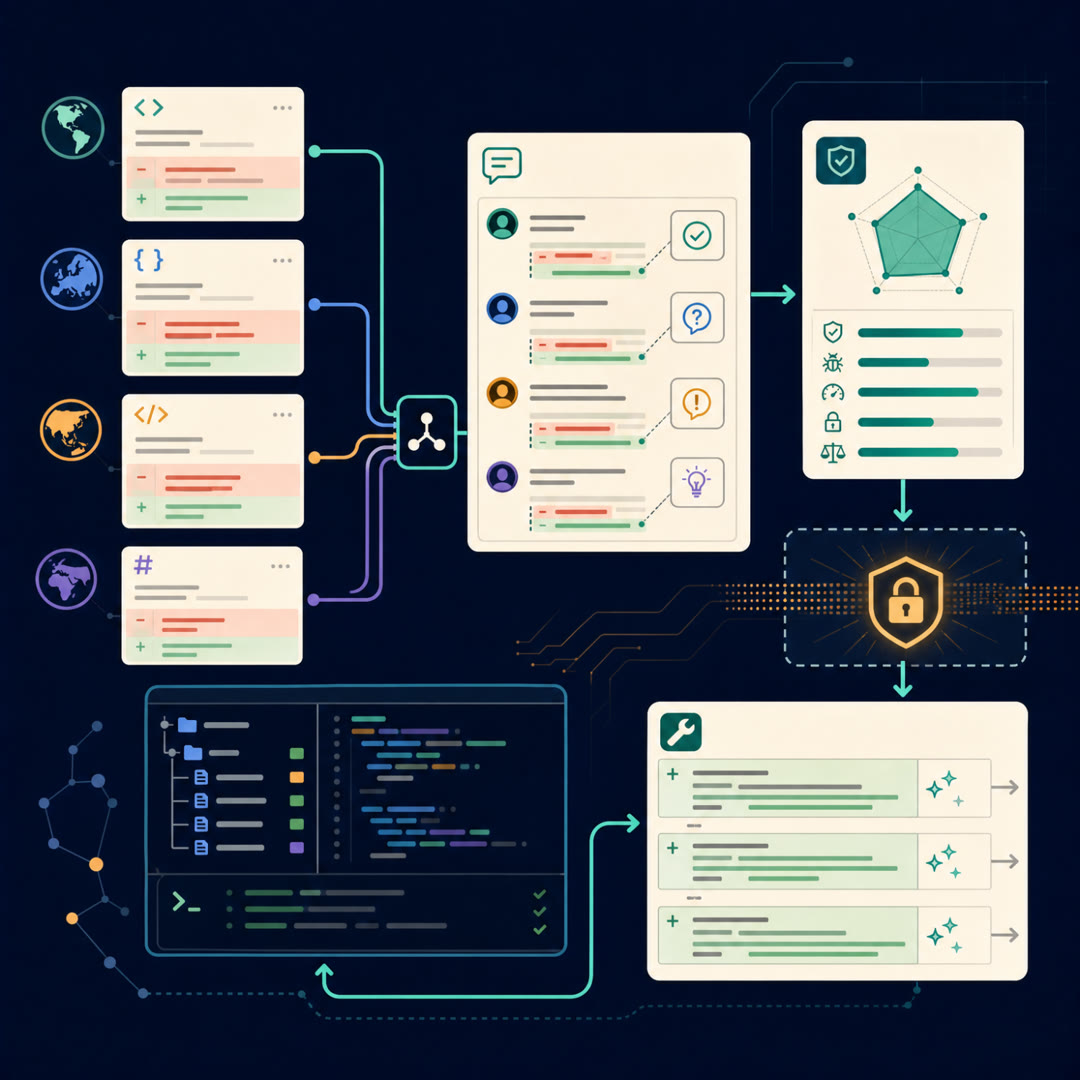
MayaThe bottom and the oldest. CodeReviewer is, in a real sense, the granddaddy here — it's where "code review as a learnable task" got planted. So this is less a benchmark, more a foundation: a pre-trained model plus a dataset, built before most of the benchmarks we mapped even existed.
LeoLet me make sure I've got the plain version. Normally you take a big model, you feed it a mountain of source code, it learns to predict code. CodeReviewer says — no, feed it something else?
MayaFeed it the review situation. Not just code sitting there, but code changes — diffs — paired with the human comments that real reviewers left on them. The raw material is the pull request: here's the before, here's the after, and here's what a human said about it.
LeoOh, so the comment is part of the data, not just the code.
MayaThe comment is the gold. That's the thing you almost never get when you scrape GitHub for code. You get tons of code. You rarely get the little margin notes of "hey, this'll leak a file handle."
LeoHmm. And they did this across a bunch of languages, right? Not just Python.
MayaNine of the popular ones. That breadth matters — a reviewer's instincts are partly language-specific, a null-pointer worry in one language, a borrow-checker worry in another, and partly universal. Training across nine picks up both flavors.
LeoOkay so we've got the data. What does the model actually learn to do with it? Because "review" is kind of a fuzzy verb.
MayaThat's the cleanest contribution, honestly. The paper refuses to leave "review" fuzzy. It breaks the job into three concrete jobs the model can be scored on. Let me give them names so they're easy to hear.
LeoGo for it, name them.
MayaCall the first one the Verdict. Given a diff, just judge it: is this change good, or does it need a comment? Thumbs up, or "hold on." The paper calls it code change quality estimation, but in your head it's the Verdict — a gate.
LeoSo it's not even writing yet. It's deciding whether to speak at all.
MayaRight, and that's a real reviewer skill. Most diffs are fine. Knowing when to stay quiet is half the trust battle — we'll come back to that.
LeoOkay, Verdict. What's the second?
MayaCall it the Note. Now actually write the review comment. The model reads the diff and produces the sentence a human reviewer would have typed. "This loop re-opens the connection every iteration." That's review comment generation — the Note.
LeoThat's the hard one, I bet.
MayaIt is, and we'll get to why. Third one — call it the Patch. Given the diff and the review comment, produce the revised code that addresses it. So the comment said "you're leaking a handle," and the model rewrites the snippet to close it.
LeoOh nice, so that's the full loop. Judge it, comment on it, fix it.
MayaThat's the arc — Verdict, Note, Patch. And here's the design idea that ties it together: those three are downstream tasks. The clever part is what happens upstream, in pre-training, before any of them.
LeoThis is the part I want slowly. What does it mean to pre-train for review specifically?
MayaSo plain pre-training is like — hide a word, guess the word. Generic. CodeReviewer instead invents practice exercises shaped like review. A handful of them, all tuned to the review scenario.
LeoGive me one I can picture.
MayaOne teaches the model the grammar of a diff itself — which lines were added, which removed, how a change is structured — so it reads a diff as a diff, not as a wall of text. Another mixes the two languages of review: the programming language and the natural-language comment, side by side, so the model learns how an English sentence maps onto a code change. The shared thread is: every warm-up drill looks like the real job.
LeoSo by the time you ask it to write the Note, it's already spent its whole childhood staring at diffs-plus-comments.
MayaThat's the bet. And the paper's headline claim is that this review-shaped diet beats the previous best general-purpose code models across those three tasks. The specialized warm-up and the multi-language data both pull their weight — they show it's not just one or the other.
Leo"Beats the previous state of the art" gets thrown around, though. Beats it on what, exactly?
MayaFair. On the three tasks, measured their way. For the Patch, you compare the model's rewrite against the human's actual rewrite — close to a real answer key. For the Verdict, you've got the human's accept-or-comment decision as the label. Those two have firmer ground.
LeoAnd the Note?
MayaThe Note is where it gets soft, and this is the big limitation. How do you score a generated review comment? You compare it to the one human comment that happened to be there. But there are a hundred valid things to say about a diff. The human said one of them. If the model says a different — totally correct — thing, the overlap-with-the-human score punishes it.
LeoOh. So a "wrong" answer might just be a different right answer.
MayaExactly. The metric rewards sounding like that specific reviewer on that specific day, not being useful. So strong comment-generation numbers here mean "plausible and on-topic," not "a senior engineer would've written this." The paper's honest that the generated comments are often generic.
LeoThat's a big asterisk. Hmm. Is that the only soft spot, or are there others?
MayaTwo more. One is dataset noise. The gold was human comments scraped from real pull requests — and real review comments are gloriously messy. "lgtm." "nit." "can you rebase." A lot of them aren't substantive; they're social, or process, or just noise.
LeoSo the model's learning from a teacher who's half mumbling.
Maya[chuckle] Kind of, yeah. Some of the training signal is genuine insight, and some is "ok merge." The model can't fully tell them apart, and neither can the scraper. You filter what you can, but noise leaks in.
LeoAnd the third?
MayaThe third is scope, and I think it's the most important for where the field went next. CodeReviewer works at the level of a single hunk and a single comment. One little diff, one note about it.
LeoAs opposed to?
MayaAs opposed to a whole pull request. A real review isn't "here's one line, react." It's "here are fourteen files, this touches the auth module and the migration, and the thing I'm actually worried about is an interaction between file three and file nine." That cross-file, whole-PR judgment — CodeReviewer doesn't reach it. By construction, it's looking through a keyhole.
LeoAh. And that keyhole is exactly the gap the newer benchmarks we mapped last time were trying to close.
MayaThat's the throughline. The staircase we walked exists because of this limitation. Whole-PR realism, defect localization across files, signal-to-noise — those higher stairs are answers to "the single-comment view is too small."
LeoLet me try to connect it to our running example, the one from the topic. We've got a small team shipping a fix to an open-source data library, and the patch has to pass hidden tests and survive a human reviewer.
MayaPerfect, use it.
LeoSo the dangerous version of that patch — it passes the empty case, the common case, all the obvious tests, but it silently disables refunds for one currency. A test-only gate waves it through. Where does CodeReviewer sit on that?
MayaBeautiful example, because it splits cleanly. CodeReviewer's Verdict might flag the diff as "needs a comment" — good, that's the review gate doing what tests can't. Its Note might even say something about the currency branch. That's the win: review catches what the test oracle is blind to.
LeoAnd the catch?
MayaThe catch is that the silent-refund bug lives in the interaction — this currency, this code path, three files over. The single-hunk keyhole might never see the connection. So CodeReviewer plants the right idea — review is a learnable skill that catches non-test bugs — but it can't yet do the wide-angle reasoning that particular bug demands.
LeoSo it's the proof of concept, not the finished reviewer.
MayaThat's exactly how I'd hold it. It established the task, built the first big multi-language review corpus, showed the three jobs are separable and trainable — and named, by its own limits, the harder version everyone chased after.
LeoOne thing I keep noticing across this topic. The hardest part isn't catching the bug. It's the speaking.
MayaSay more.
LeoThe Verdict has a label. The Patch has a label. The Note — the actual act of writing a useful sentence to a human — is the one with no clean answer key. And that's also the part that decides whether anyone trusts the reviewer.
MayaThat's the deep cut. The two tasks with crisp metrics matter least for trust. The fuzzy one is the product. Which is why the rest of this topic keeps circling back to it — usefulness, precision, signal-to-noise — not "did it detect a bug, yes or no."
LeoSo CodeReviewer hands the field a clean three-part frame and one honest confession: the part we most want, we can least measure.
MayaThat's the episode in a sentence. And maybe that's the question to sit with — if you were grading a review model, and you knew the comment score mostly rewards sounding like one particular reviewer, would you trust a high score on it at all, or would you only believe the Verdict and the Patch?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents