Subscribe
Transcript
MayaPicture an agent that solved the same task five different ways. Five complete attempts, five diffs on the table. The tests are silent — maybe there are no good hidden tests for this one, or maybe all five pass them. And someone has to point at one and say, *that's the best work here.* Not "this compiles." Not "this is green." The best *engineering*. That pointing — done by a model, reading the whole run — is today's move.
LeoSo the judge isn't a test harness. The judge is another language model, looking at the work.
MayaReading the work. And not just the final patch — the path the agent took to get there. That's the shift.
LeoOkay, hold that — last time we were in a very different room. CodeClash — agents handed an open goal, no precise bug report, just an objective, and they fought it out over rounds. A tournament where the score came from *winning the game*.
MayaRight. CodeClash measured agents by outcomes — did your code beat the other agent's at the actual goal. Today's source steps back and asks a quieter question. Forget who wins. When you've got a pile of attempts and no clean automatic referee, *how do you score one trajectory at all?* It's a project literally called LLM-as-a-Verifier.
LeoAnd "verifier" is doing a lot of work in that name. Plain version — what is a verifier here?
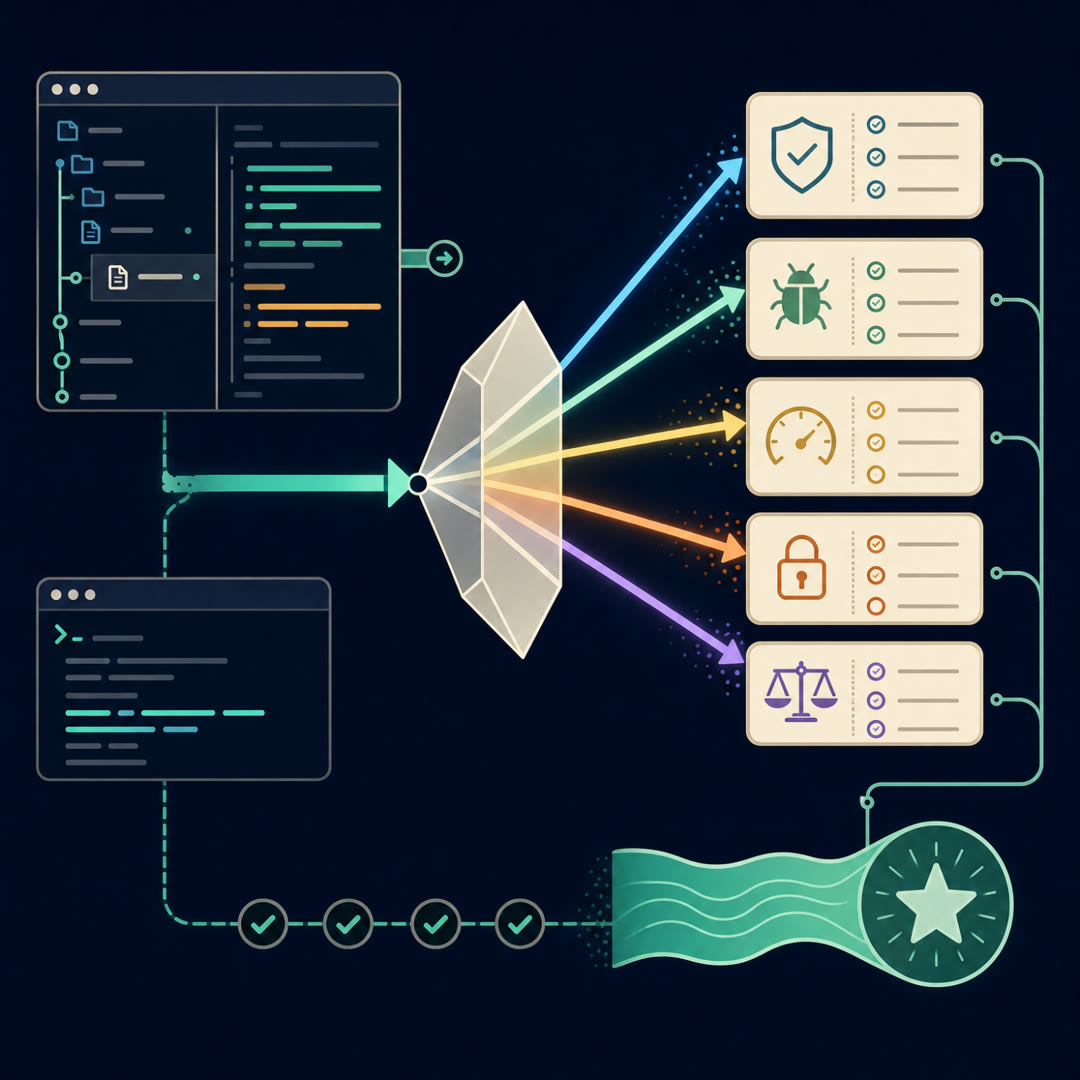
MayaA verifier just judges whether work meets the bar. A test is a verifier — a brutally simple one. It checks one fact, says pass or fail. This project asks: can a language model be a *richer* verifier? One that reads a whole coding-agent run — the searches, edits, commands, final diff — and scores how good that run actually was.
LeoHmm. But that's exactly the thing that makes me nervous. A test can't have an opinion. A model judging a model — that's grading with vibes, isn't it?
MayaThat's the right fear, and the whole design is built to answer it. Ask a model "rate this run, one to ten," yeah — you get a vibe. One number, no idea how sure it is, swings if you ask twice. So the project does something more careful.
LeoGive me the signposts before we start. So I don't lose the thread on a walk.
MayaThree. *Break the question apart.* *Ask more than once.* *Listen to how sure it is.* Those are the moves that turn "rate this, one to ten" into something you'd actually trust.
LeoOkay. Break the question apart — start there.
MayaInstead of one giant "is this good," you decompose the judgment into separate criteria. Did it address the task? Is the change focused, or did it thrash all over the repo? Does the trajectory show it understood the feedback it got back? Each criterion judged on its own.
LeoAh — so it's a little scorecard, not one verdict.
MayaA scorecard. And that matters concretely. Take our running example — the team shipping a fix to that open-source data library. A single "looks good" can hide a disaster. Split it up, and one criterion can quietly fail: *did this change preserve behavior for every case?* That's where the patch that passes the common path but silently breaks one currency's refunds gets caught — by a criterion watching for "did you narrow the behavior without meaning to."
LeoSo decomposing isn't just tidiness. It gives the failure somewhere to show up.
MayaExactly. A blended score lets a real problem average out against four things that went fine. Separate criteria refuse to let it hide.
LeoOkay. Second move — ask more than once. If I ask the same model the same question, don't I get the same answer?
MayaYou'd think so, but no — these models are samplers. Ask twice, you can get two different reads, especially on a borderline call. So the project runs the verification several times and aggregates. The oldest trick in measurement: a noisy instrument, read repeatedly, averages toward the truth.
LeoLike weighing yourself three times on a cheap scale and taking the middle.
MayaThat's the instinct exactly. One read is noise. A handful, combined, is a measurement. It costs you — every pass is another model call — but it buys stability one shot can't.
LeoAlright, the third one is the one I don't have a picture for. *Listen to how sure it is.* What does that even mean for a model?
MayaThis is the clever part, worth slowing down. When a model is about to emit a score — choosing what number token to write — it doesn't just pick one. Underneath, it has a probability spread across the options. It might lean hard toward a high score, or be genuinely split between two.
LeoOh — so you can peek under the final answer and see the *confidence*.
MayaThat's the move. Those underlying probabilities are called logprobs — the model's own internal odds for each possible token. Instead of the one word it lands on, the project reads the whole spread and turns it into a continuous, weighted score. A model that's eighty-twenty on "good" gives a softer number than one that's all-in.
LeoSo a confident judgment and a coin-flip judgment don't get to look identical anymore.
MayaRight. A bare verdict throws that away — "good" and "good, but barely sure" come out the same. Reading the spread keeps the doubt *in* the number. That's calibration here: the score reflects not just the call, but how strongly the model believes it.
LeoOkay, and once you've got these calibrated, decomposed, repeated scores — what do you actually *do* with them?
MayaBack to the five attempts on the table. You can now rank them. The project uses a tournament — pit trajectories against each other pairwise, round-robin, let the verifier pick the better one each time. The one that keeps winning is the one you keep.
LeoSo it's a selection tool. The agent generates a bunch of tries, and the verifier is the judge that crowns one.
MayaThat's the headline use. And it's exciting because of *where* it helps — exactly where tests go quiet.
LeoSay more, because I'm still half on team-tests. Why not just write better tests?
MayaBecause tests answer one question — does the output match the behavior I thought to check. Beautiful when you have them. But a lot of engineering judgment never lands in a test. Is this the *focused* fix or a sprawling one? Did the agent understand the error it got back, or stumble into a fix? On open-ended tasks, there may be no single right answer to encode at all.
LeoAnd on a fresh task, you might not *have* hidden tests yet.
MayaRight. Or all your candidates pass the tests you do have, and you still have to choose. The project reports on the long-horizon command-line tasks — Terminal-Bench — and on SWE-bench Verified, and using the verifier to select trajectories lifts success above just taking the agent's first try. Modestly — not a miracle. But a real lift from grading the *work*, not just the output.
LeoA judge that reads the room, sitting where the tests can't reach.
MayaThat's the pitch. Now — you've been patient, and you know what's coming.
Leo[chuckle] The part where you tell me it hurts.
MayaIt hurts in four honest ways — the same four every model-as-judge scheme inherits. The first you flagged at the top — hallucination. A verifier is still a language model. It can confidently announce that a trajectory handled an edge case it never touched, or flag a bug that isn't there. Wrong with the same fluent certainty it's right with.
LeoSo the judge can hallucinate the verdict the same way the worker hallucinates the code.
MayaSame failure, one level up. Second is calibration drift. We just praised reading the confidence — but confidence only helps if it's *honest*. Models are often overconfident, and "the model said it's very sure" and "it's actually right that often" aren't guaranteed to match. Lean on calibration too hard and you trust a confidence that was never earned.
LeoHmm. So the very thing that makes it feel rigorous could be quietly lying to you.
MayaCould be. It has to be checked against ground truth, not assumed. Third is bias. The verifier and the agent are often the same family of model — and a model can prefer work that *looks like its own*. Longer, more confident-sounding answers can win not because they're better but because they pattern-match to "good." The judge has tastes, and they aren't neutral.
LeoThat's nasty for selection, because you're picking the winner *by* those tastes.
MayaIt is. You can train the agent to please the judge instead of solving the problem — the same reward-hacking shadow over this whole topic. And the fourth limit is cost. Decompose into several criteria, repeat each one, run a round-robin over a pile of candidates — that's a lot of model calls per decision. Tests are nearly free to re-run. This is not.
LeoSo it's a powerful instrument that's also expensive *and* fallible. Where does that leave it next to plain tests?
MayaNot as a replacement — as a *complement*, and that's the honest reading. Where you have solid hidden tests, lean on them; they're cheap and they don't have opinions. Where tests run out — open-ended work, trajectory quality, choosing among candidates that all pass — a calibrated, decomposed, repeated verifier extends judgment into territory tests can't see. As long as you remember it's a noisy, biddable judge, not an oracle.
LeoWhich lands right on the topic's running argument, doesn't it. Tests-as-the-only-oracle versus human-or-model judgment.
MayaIt lands on it perfectly. One camp says executable tests are the only thing you can trust — everything else is opinion dressed up as measurement. The other says tests miss most of what matters, so you need richer judgment even if it's imperfect. This project is the second camp saying: fine, *if* we use model judgment, let's make it as disciplined as we can — break it apart, repeat it, calibrate it — instead of waving it away.
LeoAnd tie it to our thread one more time. The data-library team — what's the artifact here?
MayaIt's not "the verifier said eight out of ten." It's the whole scored trajectory — the criteria it was judged on, the confidence behind each, the runs it beat in the tournament. That scorecard is reusable. You can train on it, audit it, argue with it. Collect the judged work-trace, not just the verdict.
LeoThe judgment becomes data, not just a gate.
MayaThat's the quiet gift. A test gives you a bit — pass or fail. A verifier like this gives a graded, calibrated, contestable record of *why* one run beat another. Worth more, costs more, and you keep one eye on whether you can trust it.
LeoHere's the one I'll leave you with. If you let a model judge which engineering work is best, and you start optimizing your agents to win that judgment — how would you know when your agents have stopped getting better at the work, and started getting better at flattering the judge?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents