
Subscribe
Transcript
MayaDay sixty-one of the ninety-day run. The loss has been sliding down for weeks, and overnight it stops — not crashing, just refusing to go lower. Same model, same data, same machines. Someone swaps one knob: how the optimizer scales each step. Twelve hours later the curve is moving again.
LeoOne knob. Not the architecture, not the corpus.
MayaThe optimizer. The quiet character in this whole series — the thing that takes a gradient and decides what step to actually take. Get it wrong and the most beautiful sparse model in the world just... sits there.
LeoLast time we ended on the search problem — automated machine learning, where the tuning over architecture, hyperparameters, and data recipes stops being hand-craft and becomes a machine search that competes with training for the same compute budget.
MayaAnd today's source closes the loop, because the optimizer is what that search runs on top of. It's a twenty twenty-five systematic review in the journal Mathematics that steps back and asks: across all of machine learning, what are the optimization methods, and when does each one actually win?
LeoA review, not a new method. So our job is the map, not a single trick.
MayaRight — and it's the finale, so it's the map of the whole back wall of the lab. The gauges that decide whether ninety days of rented machines turn into a model or a very expensive flat line.
LeoOkay. Start me at zero.
MayaAt zero, optimization is one sentence. You have a knob-covered machine — the model's weights — and a score that says how wrong it is. Optimization is the procedure for turning the knobs to make the score better.
LeoAnd gradient descent is the obvious one. The gradient points uphill, so step downhill. Done.
MayaDone, except for the part that eats careers. The review splits the whole field at the top into two families, and the split is about whether you even have that downhill arrow. Gradient-based methods use the slope, the derivative. Population-based methods don't — you throw a crowd of candidate solutions at the problem and let the good ones breed.
LeoEvolution versus calculus.
MayaA fair bumper sticker. And the review's headline finding is clean: gradient-based methods win when you're data-rich and need to converge fast — exactly deep learning. Population-based wins when the derivative isn't available or the landscape's too jagged to trust a slope.
LeoSo for our lab — a giant sparse language model, gradients everywhere — we live almost entirely in the gradient family.
MayaAlmost entirely. Which is where the review spends most of its energy, and where the interesting fights are. So let me walk the gradient family as a kind of lineage — each method fixing the last one's flaw.
LeoGo.
MayaThe ancestor is stochastic gradient descent. S-G-D. "Stochastic" means you don't compute the slope over all your data every step — ruinous on eight hundred gigabytes of text. You grab a small batch, estimate the slope, and step.
LeoCheap, noisy. The noise is the catch, right? Each batch lies a little about the true direction.
MayaThe noise is the catch — and, plot twist, also part of the magic. Hold that thought. The first real fix is momentum. Plain S-G-D on a long narrow valley does this miserable zig-zag across the walls, barely moving forward. Momentum says: remember where you've been going and keep some of that velocity.
LeoA ball rolling downhill instead of a hiker re-deciding every footstep.
MayaThat's the picture — the ball averages out the side-to-side jitter and builds speed down the long axis. Then Nesterov sharpens it with one tweak: look ahead. Take the momentum step first, measure the slope where you're about to land, and correct from there.
LeoPeeking around the corner before you commit.
MayaThat's the whole first room — S-G-D, momentum, Nesterov. The slope, the velocity, the look-ahead. Now the second room, which is the one most engineers actually live in, and it's a different idea entirely.
LeoAdaptive methods.
MayaAdaptive methods. Here's the problem they attack. In a big model, different weights see wildly different gradient scales. One parameter gets a strong, frequent signal; another gets a rare, tiny one. A single global step size is wrong for both at once.
LeoSo instead of one learning rate for the whole model—
Maya—you give every parameter its own. The first one in the lineage is AdaGrad — it keeps a running sum of how big each parameter's gradients have been, and divides the step by that. Big history, small steps. Rare parameter, big steps when it finally moves.
LeoWhere's the catch? There's always a catch.
MayaThe catch is that the running sum only grows. So every per-parameter step shrinks toward zero and the model freezes before it's done. RMSProp fixes it with a forgetting factor — a decaying average of recent gradient sizes instead of summing forever. Old news fades.
LeoAnd then Adam is... both of those bolted together?
MayaAdam is the merger. A-D-A-M. RMSProp's decaying average for the per-parameter scaling, plus momentum's running average of direction. Velocity and per-parameter scaling in one optimizer.
LeoWhich is why it's the default in basically every codebase. Import Adam, set a learning rate near a small round number, it mostly just works.
MayaIt mostly just works. And the variant our lab actually reaches for is AdamW — the W is "weight decay done right." Adam was muddling the regularization in with the adaptive scaling; AdamW pulls them apart so keeping weights small isn't accidentally rescaled per parameter.
LeoHuh.
MayaThe review flags that whole pattern — a lot of the recent advance isn't a brand-new optimizer, it's better regularization and adaptive control bolted onto the ones we have. AdamW is the poster child.
LeoOkay, but you parked a "plot twist" back there and I want it back. The noise in S-G-D being magic.
MayaHere's where the review gets honest, and where the real fight lives. Adam converges fast — often quickest to the bottom on the training score. But there's a stubborn result, going back to a sharp twenty seventeen paper, "The Marginal Value of Adaptive Gradient Methods": the place Adam converges to often generalizes worse than where plain, well-tuned S-G-D ends up.
LeoWait. Worse? Lower training loss and a worse real-world model?
MayaLower training loss, worse test behavior. They even built a clean classification problem where the adaptive methods provably converge to a solution that misclassifies new data close to a coin flip — while S-G-D nails it.
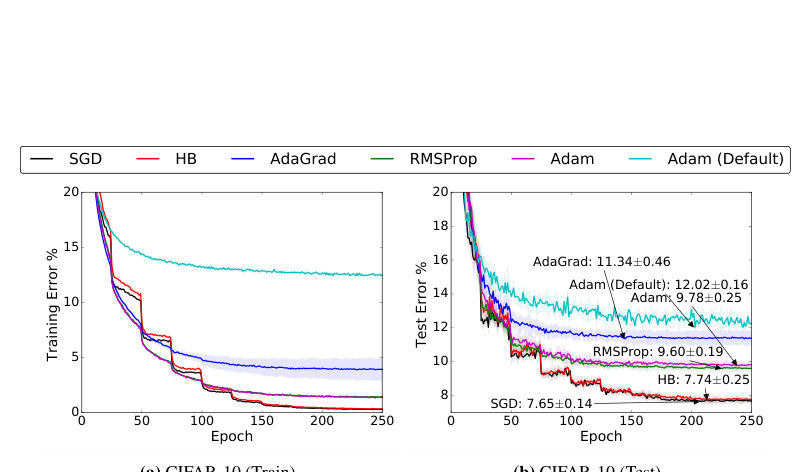
LeoOkay, let me take the S-G-D side, because I think it's stronger and people wave it off. The noise you called a flaw is a feature. Plain S-G-D's randomness pushes the model toward wide, flat basins — solutions that don't change much if the data wobbles. Adam's per-parameter rescaling lets it dive into sharp, narrow holes that fit the training set and nothing else. Fast to a worse place.
MayaFine — and I'll take the adaptive side honestly, because "just use S-G-D" is glib on a ninety-day run. Well-tuned S-G-D hides a brutal word: tuned. Get the learning-rate schedule a little wrong and S-G-D stalls or diverges, and you've burned days you don't get back. Adam forgives. On a sparse model with a router still thrashing early, gradients are jumpy and non-stationary, and that forgiving scaling is often the difference between a run that survives week one and one that blows up.
LeoThe jumpy-router point I'll grant you — that's real. Sparse mixture-of-experts training has these brutal early gradients while the router decides who does what, and adaptive scaling does babysit that better. But that's a stability argument, not a generalization argument. You're conceding my point and winning a different one.
MayaI am — and that's the resolution, isn't it? Not Adam versus S-G-D, winner take all. It's which problem dominates your run. Early, with a wild data mix and a thrashing router, instability is the threat and adaptive wins. Late, when you care about the model that walks out the door, generalization is the threat and the S-G-D-shaped solution looks better.
LeoWhich is why the trick people actually ship is to switch — start on Adam to survive the chaos, hand off to S-G-D near the end to land in the flatter basin.
MayaAnd the review's framing supports that — a toolbox matched to regimes, not a leaderboard with one winner. The honest answer is "it depends," and it names what it depends on.
LeoI can live with that.
MayaTwo more rooms, fast, because our lab hits both. Second-order methods — and large-batch methods.
LeoSecond-order. That's curvature, not just the slope?
MayaThat's it. First-order methods know which way is downhill; second-order methods also know how the hill bends, so they take smarter steps and converge in far fewer of them. The catch is cost — the full curvature of a billion-parameter model is a matrix the size of the parameter count squared. You can't store it, let alone invert it. So the line — quasi-Newton methods like L-B-F-G-S — chases cheap approximations of that curvature.
LeoAnd most still don't pay off at deep-learning scale. Theoretically gorgeous, operationally brutal — which is why first-order rules in practice.
MayaBeautifully put. And the last room is pure ninety-day-lab: large-batch and distributed optimization. Your model's too big for one machine, so you split the batch across a wall of accelerators. The cruel part — naively, the bigger the batch, the worse the model often gets, because you've thrown away exactly the gradient noise we just spent ten minutes praising.
LeoThe magic noise, killed by averaging over a giant batch.
MayaKilled by averaging. So there's a family — LARS and LAMB are the named ones — that rescale the step layer by layer, so a huge batch can still train a usable model without the generalization tax.
LeoAnd that's not a luxury for our lab, that's the whole reason the run fits in ninety days. Big batches are how you keep the wall of machines busy.
MayaIt's load-bearing. Which brings the series example home. Look at everything piled onto this one optimizer choice. A sparse mixture-of-experts model — router jumpy early, gradients non-stationary. A Pile-style data mix — books next to code next to lab notes — so the loss landscape is lumpy, no single clean valley. A huge distributed batch — so the protective noise is thin. And a fixed budget — maybe one or two real shots at the schedule.
LeoEvery one of those makes the optimizer matter more. The sparsity, the diversity, the scale — they don't just sit next to the optimization choice. They sharpen it.
MayaThey sharpen it — that's the through-line of the whole topic, in optimizer language. Sparsity gave you capacity without full cost. The data mix gave you breadth. The search gave you tuning at machine speed. And the optimizer has to make all of it converge — on one budget, in one window.
LeoAnd the limitation the review is honest about — it's a map, not a GPS. It names the families and the regimes, but it can't hand you the schedule for your specific model on your data. That part's still craft.
MayaStill craft, still partly luck, and still the thing that decides whether day ninety is a model or a flat line. So here's where I'll leave the whole series. We've spent seven topics adding power to the machine — sparse routing, diverse data, automated search, and now the optimizer that has to land it all. If you had to bet your one ninety-day budget on getting exactly one of those choices right — sparsity, data, or the optimizer — which one would you trust the others to forgive?
Source material
← Back to Mastering Language Models: From Architecture to Optimization