
Subscribe
Transcript
MayaPicture our ninety-day lab on day one. Machines humming, the sparse model wired up — but the loading dock is empty. Someone has to decide what text walks through the door, and that choice quietly sets the ceiling on everything: do you back a truck of scraped web pages up and shovel it in, or hand-assemble a corpus — a crate of books, a bin of legal opinions, a spool of source code — and deliberately mix them?
LeoAnd the instinct is usually "more web, less fuss." Scraping is free, huge, already there.
MayaRight — and today's paper says that instinct leaves capability on the table. The bet is that what your model can do is shaped less by how many tokens you pour in, and more by how many different worlds those tokens come from.
LeoOkay.
MayaLast time we followed mixture-of-experts out of language entirely — that operator transformer carried sparse routing into physics, experts specializing across different families of partial differential equations so one sparse model could generalize across many physical systems.
LeoThat was sparsity in the model. Today's source flips to the other side of the same lab — diversity in the data. The paper is The Pile, from EleutherAI, and instead of a routing trick it's a deliberately assembled corpus — and the argument that assembling it that way is a design decision, not housekeeping.
MayaThat's the turn. Most data sections read like a footnote — "trained on web text, here's the token count." The Pile makes the corpus the experiment.
LeoLet's be concrete first. How big, and made of what?
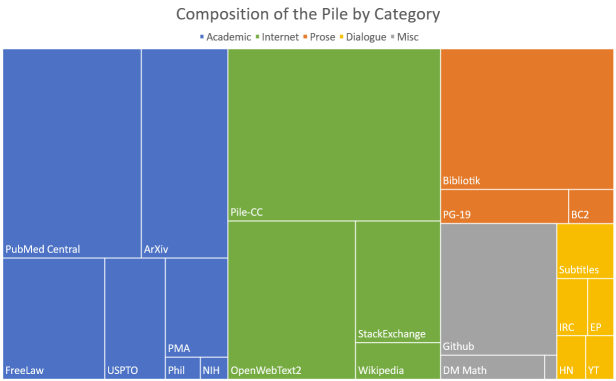
MayaRoughly eight hundred gigabytes of English text — eight hundred twenty-five gibibytes, exactly. But the headline isn't the size. It's the count of distinct sources. Twenty-two of them.
LeoTwenty-two datasets, stitched into one.
MayaTwenty-two — and not flavors of the same web soup. Think of an intake hopper with labeled bins. Books. Source code from public repositories. Academic papers — a biomedical pile and a physics-and-math pile. Court opinions. Dialogue — subtitles, forum threads. Encyclopedia text. Question-and-answer communities. And yes, a filtered slice of the open web — but as one ingredient, not the whole meal.
LeoHuh.
MayaThat structure is the argument made physical. Each bin is a different register of language — a different vocabulary, a different way of building a sentence, a different shape of reasoning.
LeoLet me push on the "why" before I buy the "what." Why would a model trained on court opinions and biology abstracts be better at, say, ordinary conversation? Those feel like distractions from the main task.
MayaBecause the claim is they're not distractions — they're transfer. The paper's central finding is that more diverse training data improves the model's general, cross-domain ability and downstream generalization. Read the legal bin and you learn how careful, heavily-qualified argument is built. Read the code and you absorb rigid, nested logic.
LeoSo each domain teaches a skill that shows up everywhere else.
MayaThat's the bet. A model that's only read the open web has seen one register a thousand times. A model that's read twenty-two has seen the machinery of language from many angles — and that breadth shows up later as flexibility.
LeoHere's where I plant a flag, though, because this is the kind of claim that sounds wonderful and dodges the cost. Our lab doesn't have an infinite token budget — it has ninety days on a fixed wall of machines. So the real question isn't "is diversity nice." It's: for the same tokens, does diverse beat curated?
MayaThat's the version worth defending — because they tested close to it. Budget held fixed, they trained on the Pile mix and compared against models trained on raw web crawl and on cleaned web crawl. The diverse mix came out ahead — not only on the new domains, which you'd expect, but on the web-text evaluation itself.
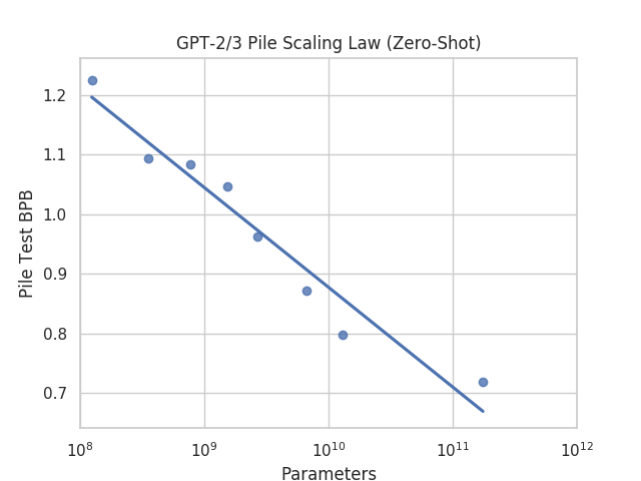
LeoWait — better at web text than the model trained only on web text?
MayaThat's the result that makes people sit up. Adding books and code and law didn't just buy new skills. It made the model better at the thing the web-only model specialized in.
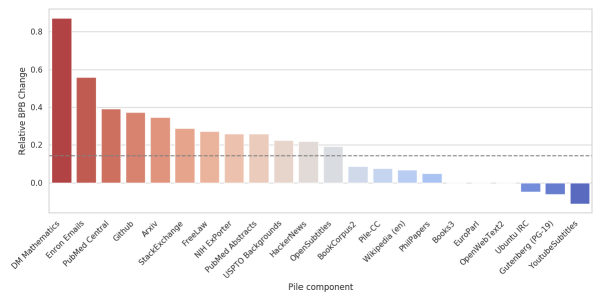
LeoOh — that flips it.
MayaIt flips the intuition that "broad" trades against "good at my domain." At the scales they tested, breadth lifted the home domain too.
LeoOkay, real result, I'll take it seriously. But let me stage the fight honestly, because there are genuinely two camps in this lab, and our ninety-day team has to pick one.
MayaDo it. I'll take the diversity side, you take curation.
LeoFine. The curation camp says quality beats quantity, full stop. On a fixed budget, every gigabyte spent on a low-grade forum thread is a gigabyte not spent on a clean, well-edited book. So you filter aggressively — keep only high-quality text, train on a smaller, cleaner pile. And the evidence is real: models that filter hard often beat models that don't, token for token. Garbage in, garbage out isn't a slogan, it's measured.
MayaAnd the diversity camp doesn't deny garbage hurts — it denies that "high quality" means "from one source." Aggressive curation has a failure mode: you optimize for a narrow notion of clean and quietly delete whole registers. Filter for polished prose and you throw out the code, the legal hedging, the messy dialogue — the very registers that teach transferable skills. The Pile's answer is you want both. It's not raw web — each of those twenty-two bins was selected to be high-quality within its domain.
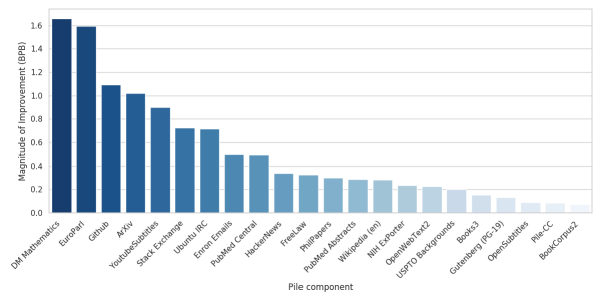
LeoHm. That's a fair correction, and it narrows the fight. So it isn't diversity versus quality—
Maya—it's where you spend your curation effort. Within each domain, or down to one domain.
LeoThen let me concede what the evidence forces and keep what it doesn't. The Pile result says diversity helped at their scale — I'll give them that. What it doesn't settle is the frontier case, when you have so much data you're choosing the very best slice of an ocean. At that extreme, ruthless filtering might win, and a hand-built twenty-two-way mix might be the wrong tool.
MayaI'll sign that. Breadth and curation aren't enemies — the question is the order you apply them in, and how much data you're standing on. The Pile makes the case for "diverse first, curated within," and proves it at its scale — it just doesn't claim to be the last word at every scale.
LeoGood. A fight that ends somewhere. So — the assembly. You can't just dump twenty-two datasets in a folder and call it a corpus. What's the engineering?
MayaTwo jobs, both unglamorous and load-bearing. The first is the mix — how much of each bin goes in. They didn't weight by raw size.
LeoBecause raw size lies.
MayaRaw size lies. The open web is enormous; a curated set of books is tiny by comparison. Weight purely by bytes and the web drowns everything. So they up-weighted the higher-value sources — a book is worth more passes than a random web page, deliberately.
LeoRight.
MayaThe second job is cleanup, and the big one is deduplication. Merge twenty-two sources and the same text shows up in several — an article quoted on the web and again in a forum, boilerplate across thousands of pages, one document in two datasets.
LeoAnd duplicates aren't free. See the same passage a hundred times and the model spends budget memorizing it instead of learning the general pattern — and your evaluation gets contaminated if a test passage snuck into training.
MayaBoth. So they deduplicate across the whole corpus, not just within each source. Finding near-duplicates across eight hundred gigabytes is a hard engineering job — and it's most of what "assembling a good corpus" really means. The glamour's in the idea; the work's in the dedup.
LeoOkay, new problem. Once you've built this Frankenstein corpus, how do you know if it's working? You can't eyeball eight hundred gigabytes.
MayaTheir measuring stick is built for exactly the diversity problem — bits per byte. A language model, underneath, is a compressor: the better it predicts the next text, the fewer bits it needs to encode it. Bits per byte just asks how many bits the model needs per byte of content. Lower is better — the model found it more predictable, which means it understood it better.
LeoAnd why bytes instead of tokens? Seems pedantic.
MayaIt's the opposite — it's what makes the comparison fair across domains. Different tokenizers chop text differently, and code tokenizes nothing like prose. Per token, you can't compare a model's grip on Python against its grip on poetry. Per byte, the denominator is the raw text itself, the same for everyone — one honest ruler across all twenty-two bins.
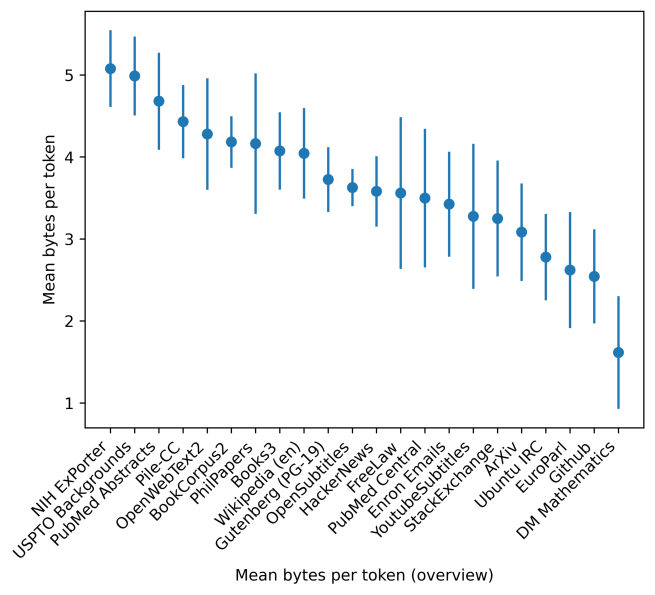
LeoAh — a scorecard, not a score.
MayaExactly. You don't get one number that says "good model." You get a profile — strong on encyclopedia text, weaker on legal, surprisingly good on dialogue. For our lab, that profile is gold: it tells you which registers the model is starving on, so you can re-weight the hopper.
LeoSo the corpus isn't fire-and-forget — it's a dial you tune against a per-domain scorecard. "What's our training data" stops being a noun and becomes a verb.
MayaAnd that's the reframe the Pile leaves you with — which sets up the bill, because every good design has one.
LeoSay it. Breadth means you've deliberately ingested the messy parts of the internet. What comes with that?
Maya{sigh} Everything that comes with the open internet. Bias, toxicity, copyrighted material, private information caught in the scrape. A diverse corpus is a more representative slice of human writing — and human writing includes its worst registers. The paper is unusually candid here: it documents the corpus instead of laundering it, and that documentation is part of the contribution.
LeoResponsible move, but it doesn't make the problem disappear — it hands the lab a known liability instead of a hidden one.
MayaThat's the honest framing. And a second limitation from our debate: the mixing weights and dedup thresholds are partly judgment calls. Change those dials and you change the model. The recipe isn't a law of nature — it's a defensible set of decisions, and the paper's gift is making them explicit enough to argue with.
LeoMm.
MayaWhich is the lasting thing. Before the Pile, the data section was where papers got vague. After it, "we trained on a diverse, documented, deduplicated mix, and here's the per-domain scorecard" became something you could expect — and check.
LeoIt turned data curation from a private craft into a public, measurable artifact. Even labs that never download a byte of the Pile inherited the playbook — assemble across registers, weight on purpose, dedup hard, score per domain.
MayaSo for our ninety-day team, the decision was never really "Pile or curation." It was: be deliberate about both. Pick your registers, curate within each, and let a per-domain ruler tell you when the mix is wrong — instead of finding out at the end, budget already spent.
LeoAnd spend it knowing what you bought. Breadth isn't free, and the weights are yours to defend.
MayaSo here's the question I'd leave the lab with: if your model's general ability really does come from the variety of worlds it reads, then which register is your training data quietly missing — and what can your model never learn because that bin is empty?
Source material
← Back to Mastering Language Models: From Architecture to Optimization