Subscribe
Transcript
MayaPicture a library with a thousand specialists on staff — one for medieval poetry, one for tax law, one for marine biology, on and on. A question walks in. Instead of marching it past all thousand desks, a single clerk glances at it and waves it toward just two. The other nine hundred ninety-eight never look up.
LeoAnd the building paid to employ all thousand.
MayaIt paid to employ all thousand — that's the strange, almost greedy bet at the heart of today's paper. Build a model with enormous total capacity, but for any one word, wake only a tiny slice of it.
LeoOkay.
MayaLast time, the topic overview drew the opening map — sparsity separates a model's capacity from its compute-per-word, framed through one small lab on a fixed ninety-day compute budget facing five choices: sparsity, data, automation, optimization, and whether it all converges.
LeoThat was the map. Today's paper is the first dot on it — where someone first made that clerk-and-specialists trick actually train.
MayaIt's called "Outrageously Large Neural Networks," and the title is doing real work. They built a layer with — at the top end — around a hundred and thirty-seven billion parameters, back in twenty-seventeen, when the biggest dense models were a tiny fraction of that.
LeoTwenty-seventeen — before the giant Transformers everyone knows. The seed, not the harvest. So anchor the listener — what wall were they hitting?
MayaA simple, brutal one. For years the recipe was: make it bigger, feed it more — reliably better results. But "bigger" had a cruel catch. In a dense network, every parameter does work on every single example.
LeoSo double the size, and you double the cost of every word, every training step, forever.
MayaForever. Capacity and compute were welded together. And the authors suspected we were wasting most of that compute.
LeoWasting how?
MayaProcessing the word "the" doesn't take the same brain as parsing a clause about quantum chromodynamics — but a dense model throws its entire brain at both. The hunch: most of the network's knowledge is irrelevant to most inputs. So why activate all of it?
LeoHuh.
MayaThat's conditional computation — different inputs lighting up different parts of the network. People had wanted it for years and nobody had made it work at scale.
LeoAnd that phrase usually hides the real hard part. What broke?
MayaA cluster of things — call it the trio of headaches. First, branching. GPUs love doing the same dense math on huge batches. The moment you say "this input goes left, that one goes right," you fracture the batch into ragged pieces and the hardware sits idle.
LeoRight — the silicon wants a stampede, and conditional computation gives it a hundred footpaths.
MayaExactly. Second, bandwidth — if experts live on different machines, every routing decision ships data across the network, and that traffic can swamp the computation. And the third, the subtle one, is balance.
LeoBalance meaning the load across experts?
MayaThe load across experts. It's the headache that nearly sinks the whole idea — hold onto it. It's the villain of the second half.
LeoNoted. So they've got the dream — thousands of specialists — and three reasons it shouldn't work. What's the mechanism?
MayaThey take a layer — in their case, between stacked recurrent layers, the L-S-T-Ms that were the workhorse before Transformers — and replace it with a Mixture-of-Experts layer. Inside sit thousands of small feed-forward networks. The experts.
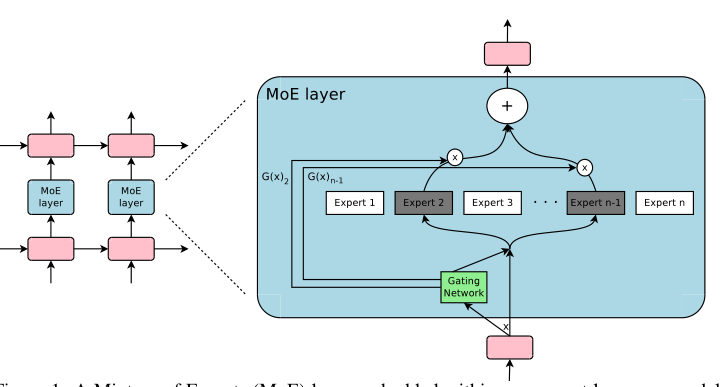
LeoThe specialists at their desks.
MayaAnd in front of them, the clerk — the gating network. For each incoming token, it scores every expert: how relevant are you to this particular word? Then comes the move that makes it sparse instead of just clever — it doesn't blend all the experts. It picks the top few, say the two highest-scoring, and sends the token only to them. Everyone else stays dark.
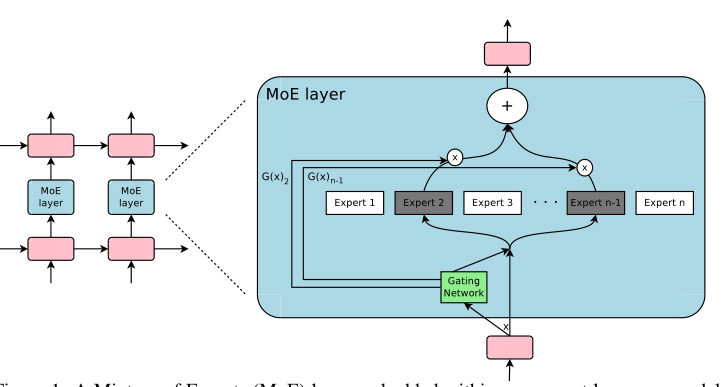
LeoSo the math per token is the cost of two small experts, not two thousand. Capacity is two thousand experts. Compute is two.
MayaThat sentence is the whole paper. Capacity scales with the number of experts; compute scales with how many you pick. Decouple them and you grow the model a thousand-fold without the per-word cost following.
LeoThat's the bargain.
MayaThat's the bargain. And the gating they use has a name worth keeping — noisy top-k gating. "Top-k" is the picking-the-best-few part. The "noisy" part is sneakier, and not decoration.
LeoOkay, sell me on the noise — randomness in a routing decision sounds like a bug, not a feature.
MayaIt sounds insane, I know. But before they pick the top few, they add a little tunable random noise to each expert's score. It gives the routing some wiggle. Without it, the very best expert wins every single time, deterministically, and—
Leo—and the rich get richer. The expert that's slightly good early keeps getting picked, keeps getting trained, keeps getting better, and the rest starve.
MayaYou just described the villain — the technical name is expert collapse. A handful of experts win the early lottery, get all the traffic, all the gradient, and the other nine hundred-plus become dead weight — parameters you pay to store that never learn anything. And it's self-reinforcing — more traffic makes an expert better makes it win more. Left alone, the system eats itself.
LeoWhich would be a disaster — you bragged about a thousand specialists and actually trained six.
MayaSix overworked ones and a graveyard.
LeoSo the noise is a first nudge — it lets a non-favorite occasionally sneak in and get practice. But noise alone can't be the whole fix. Too flimsy.
MayaIt isn't. The real fix is two extra penalties they bolt onto the training objective — the most quietly important engineering in the paper. Think of them as two referees.
LeoName the referees.
MayaThe first watches importance. For a batch of tokens, it adds up how much total gating weight each expert receives — roughly, how much the router loves each expert — and penalizes lopsided totals. Hog all the love, the loss goes up, and training spreads the affection around.
LeoSo importance balances how much the router wants each expert. What's the second referee watching — the same thing?
MayaAlmost — except for the part that breaks. Importance can be balanced on paper while the actual traffic is still lopsided. You can love two experts equally on average but still route most of your real examples to one of them.
LeoAh.
MayaSo the second referee watches load — the actual number of examples landing on each expert — and penalizes imbalance there too. Importance smooths the intention; load smooths the reality. You need both, because a model is endlessly creative about satisfying one while violating the other.
LeoThat's the part I'd have gotten wrong. I'd have written the importance penalty, watched the average balance out, declared victory — and shipped a model still secretly funneling everything to three experts.
MayaMost people would. And it's a lesson that outlives this paper — add a penalty to fix a behavior, and the system finds the nearest loophole. The load penalty exists to close this one.
LeoOkay. So we've got the clerk, the top-few pick, the noise, two referees keeping the experts honest. That's the model on a whiteboard. But you flagged the branching headache and the bandwidth headache up front. Those don't go away because you wrote a clever loss.
MayaThey don't, and this is where the paper stops being an idea and becomes a system. Bring back our ninety-day lab — the small team with a wall of rented machines and a hard clock. They've bought into sparsity, and now they have to run a model whose experts won't fit on one machine.
LeoRight — thousands of experts, a hundred-billion-plus parameters. Not living on a single GPU.
MayaSo they split the work several ways at once. The data fans out — machines chew through different batches in parallel, the ordinary part. The new part is that the experts themselves are scattered across machines. Route a token, and it travels to wherever its chosen expert lives, gets processed, and travels back.
LeoAnd that's the all-to-all traffic. Every machine shipping tokens to every other machine, every step.
MayaEvery step. And here's the elegant bit — because every machine sends its routed tokens out together, the experts still end up seeing large batches. They reassemble a stampede out of all those footpaths, and the hardware gets fed after all.
LeoSo the trick that makes branching efficient isn't avoiding the branch — it's gathering all the branches across the cluster so each expert still gets a crowd. Turning the bandwidth cost into the thing that saves you.
MayaThat's the synthesis. Conditional computation looks free on a whiteboard and gets expensive in the network — so they engineered the traffic to rebuild the batches the hardware craves.
LeoNow the evidence, because everything so far is "should work." Somebody ran it. Where, and did it pay off?
MayaTwo places. Language modeling — predicting the next word over enormous text corpora. And machine translation — the benchmark world of twenty-seventeen.
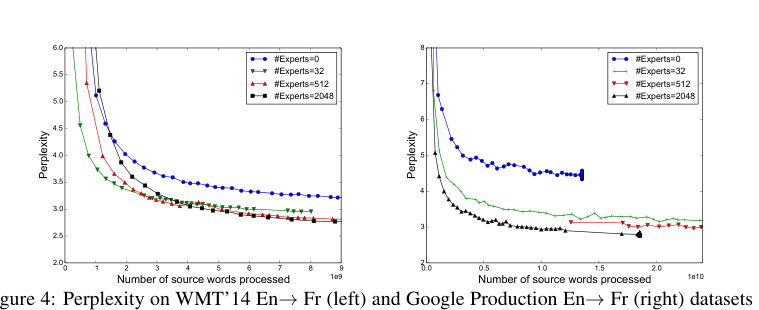
LeoAnd?
MayaOn both, the Mixture-of-Experts models beat the strong dense baselines of the day — better quality — while using less computation per word than you'd expect for that capacity. The headline they put on it: greater than a thousand-fold improvement in model capacity, with only minor losses in computational efficiency.
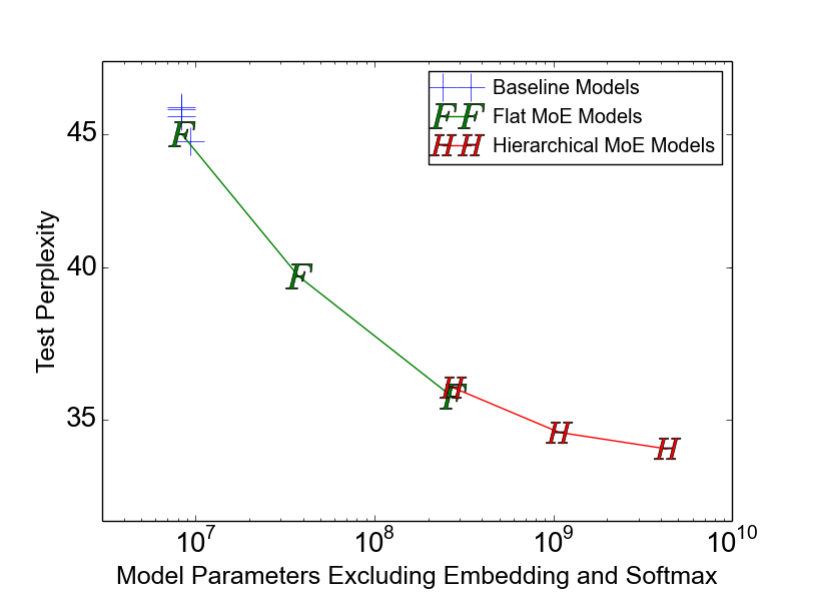
LeoHold on. "Only minor losses." That phrase carries a lot of weight, and this is exactly where sparse-scaling maximalism oversells itself.
MayaGo ahead — push.
LeoA thousand times the capacity is the number that gets quoted forever. But the honest version has asterisks. Those minor efficiency losses were on modern GPU clusters — their phrase, their hardware. It assumes a cluster with the bandwidth to do that all-to-all dance, which the small lab on a rented wall might not have. And every referee, every noise term, is a knob you can set wrong.
MayaI won't argue the asterisks — they're real. But look at the other side of the ledger. The dense alternative to a hundred-billion-parameter model in twenty-seventeen wasn't expensive — it was impossible to train. Sparsity didn't make a hard thing cheaper; it made an unbuildable thing buildable.
LeoFine — the capacity claim survives. You could not have reached that scale densely. I'll give you that.
MayaBut?
LeoBut the simplicity claim is where I dig in. A dense model has one path — deploy it, watch it, debug it. This thing can secretly collapse onto a few experts if a loss coefficient drifts, needs a whole cluster's network engineered just so, with delicate balance penalties holding it upright. The routing is fragile, and that fragility is a real, permanent tax — not a footnote.
MayaAnd I'll concede the heart of that. The paper's own machinery is the confession — if balancing experts were easy, you wouldn't need two referees and a noise term to do it. So here's where the evidence lands: sparsity buys capacity you could not otherwise afford, and bills you in operational complexity and routing risk. Both true at once.
LeoThat I can sign. It's not "sparse beats dense." It's "sparse buys scale, dense buys simplicity, and you pick which scarce resource you're protecting."
MayaWhich is the split that runs through this whole topic — and it starts here, where the trade was first made explicit.
LeoRight here.
MayaOne more limitation, beyond the fragility. The experts don't always specialize the clean way the library analogy promises. You'd love to open the box and find the medieval-poetry expert and the tax-law expert. Often what you find is more statistical than semantic — experts carving up the input in ways that work but don't tell a tidy human story.
LeoSo the routing helps the math even without handing you an interpretable map. The specialists are real; the specialties just aren't always nameable.
MayaNot always nameable — and that gap is still an open research question, years downstream of this paper.
LeoWhich is the mark of a real seed — it didn't just answer; it opened a row of questions people are still working.
MayaThat's the legacy. Almost every large sparse model since — including the giant Mixture-of-Experts systems people deploy now — traces its lineage to this exact move: a gating network, a sparse top-few pick, a balancing scheme keeping the experts honest. The names changed. The skeleton didn't.
LeoSo for the ninety-day lab making its first big choice — they're not really deciding "sparse or dense." They're deciding which problem they'd rather own.
MayaSay more.
LeoGo dense and you own a big, hungry, predictable machine — one path, easy to reason about, a hard ceiling on what it knows per dollar. Go sparse and you own a thousand specialists, a clerk that plays favorites, and a network you keep fed — but a ceiling a thousand times higher.
MayaThat's the inheritance this paper handed everyone who came after. So here's the question to sit with: if you were that lab, and the routing might quietly collapse onto a few favorites while the dashboard still looks fine — how much capacity would be worth that risk to you?
Source material
← Back to Mastering Language Models: From Architecture to Optimization