Transcript
Generated: 2026-05-10 03:15 UTC
---
MayaBefore we jump in, here's a quick setup for this episode on t3e6_flashattention_io awareness. You'll hear Maya and Leo work through the topic together.
MayaFlash Attention begins with a simple-sounding accusation: we were doing too much traffic, not just too much math.
LeoA good way to hear today’s paper is this: the bottleneck is not one thing. It is a stack of limits, and this episode picks one layer of that stack.
MayaThe earlier episodes split work across GPUs. Flash Attention looks inside a G P U and asks how attention moves through memory.
LeoSo the listener should not picture a neat whiteboard equation only. They should picture a training job as a living system: chips, memory, network links, data loaders, kernels, and a clock that punishes every idle moment.
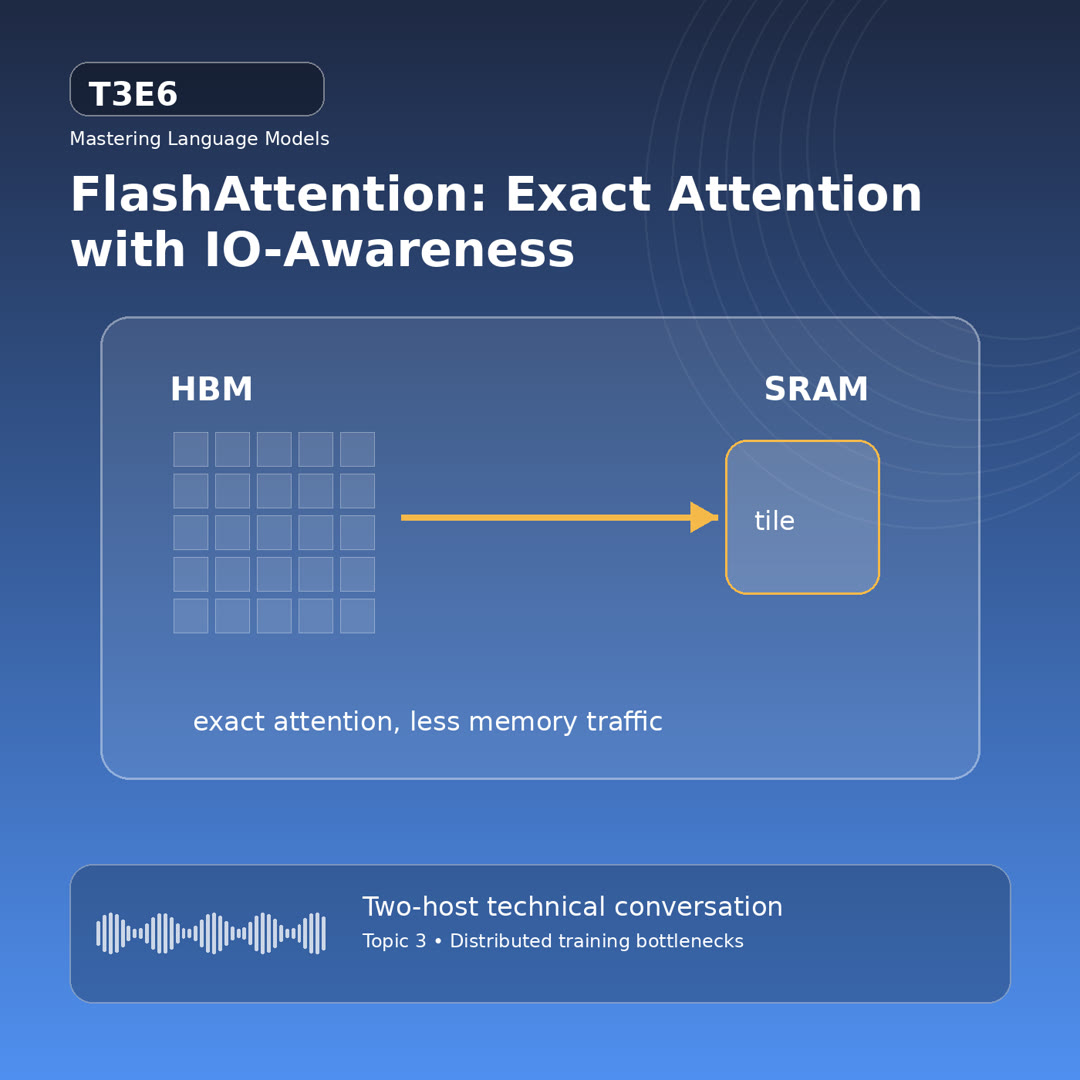
MayaExactly. Attention is quadratic in sequence length, but the killer in practice is often the giant attention matrix moving through memory. Flash Attention computes exact attention while avoiding unnecessary reads and writes.
LeoGive me the everyday version before we go technical.
MayaStandard attention often materializes a huge matrix of token-to-token scores. Flash Attention tiles the computation: load a block, compute safely with online softmax, update the result, and avoid writing the full attention matrix to slower memory.
LeoNice. That makes the paper feel less abstract. But what is the specific move?
MayaFirst, flash Attention is an I/O-aware exact attention algorithm that uses tiling to reduce reads and writes between G P U high-bandwidth memory and on-chip S R A M.
LeoThis is where the mental model matters. In other words, the system is not only asking, “Can we compute this?” It is also asking, “Can we store it, move it, and synchronize it before the GPUs go idle?”
MayaSecond, the paper argues that many approximate attention methods reduce theoretical compute but fail to deliver wall-clock speedups, while I/O-aware exact attention can be faster in practice.
LeoThat is the part many people miss. The win is not just academic elegance. The win is making a training run cross a hard boundary: fits versus does not fit, stalls versus keeps flowing, theoretical speed versus actual wall-clock speed.
MayaThird, it reports speedups including 15 percent end-to-end wall-clock speedup on B E R T-large versus the MLPerf 1.1 record, 3x speedup on Generative Pre-trained Transformer-2 at sequence length 1K, and 2.4x speedup on Long Range Arena.
LeoSo we should treat this as a design pattern, not a one-off trick. The pattern is: find the hidden resource that is being wasted, then redesign the training loop around it.
MayaThe clever part is the online softmax. Softmax normally wants to see all scores before normalizing. Flash Attention processes blocks while keeping enough running statistics to produce the exact same result without storing the entire attention matrix.
LeoThat word exact matters. This is not “approximately pay attention to fewer tokens.”
MayaRight. The model gets the same mathematical attention result, but the kernel changes how data is staged through memory.
LeoWhich also explains why hardware knowledge is not optional. A theoretically smaller operation can lose if it bounces data around inefficiently.
MayaAnd a theoretically unchanged operation can win if it keeps data close to the compute units.
LeoHere is the expert disagreement I hear underneath this episode: Should long-context efficiency come from approximating attention or implementing exact attention better?
MayaThe strongest arguments are both reasonable. Approximation can reduce asymptotic cost, but may hurt quality or fail on hardware. Flash Attention shows that exact algorithms can win by respecting the memory hierarchy.
LeoAnd the practical answer is usually not ideological. It depends on the model shape, sequence length, hardware topology, training objective, and how much engineering time the team has.
MayaFlash Attention does not make attention non-quadratic in compute. It makes the exact computation much more practical by reducing memory traffic and memory footprint.
LeoLet’s add a concrete listener check. If you were debugging this in a real training run, what would you measure first?
MayaI would measure end-to-end throughput, not only kernel speed. Then I would inspect sequence lengths, attention memory, G P U occupancy, and whether a faster attention kernel exposed a different bottleneck.
LeoThat makes this episode useful beyond the paper. It gives the listener a diagnostic habit. Do not memorize the technique first. Find the bottleneck first.
MayaThe memory hierarchy is the star. G P U high-bandwidth memory is fast, but on-chip S R A M is much faster and much smaller. Flash Attention wins by doing more useful work while data is in the small fast place.
LeoThat is a helpful physical picture. Do not carry the same boxes across the warehouse again and again. Bring a small batch to the workbench, finish the useful work, then move on.
MayaThe reason this matters for language models is sequence length. As context windows grow, the attention matrix becomes enormous. Avoiding that materialized matrix changes which context lengths are practical.
LeoAnd because the result is exact, model developers can adopt it without asking whether a new sparse or approximate attention pattern changed model behavior.
MayaA small but important detail is that Flash Attention avoids materializing the full attention matrix. In standard implementations, that matrix can be huge for long sequences. Avoiding it reduces memory footprint and changes what sequence lengths are feasible.
LeoAnd the online normalization means the softmax stays numerically valid even though the computation is blocked. The listener does not need every equation, but they should understand that the exactness is engineered, not hand-waved.
MayaThat exactness helped adoption. If a training team swaps in a faster exact attention kernel, they are not also changing the model’s attention pattern. They are changing the route through hardware.
LeoWhich is much easier to trust than a method that says, “We will attend approximately and hope quality stays fine.”
MayaThe broader lesson is that asymptotic complexity is not the whole story. A method with the same big-O compute can be much faster when it respects memory hierarchy and G P U execution.
LeoSo Flash Attention is a great bridge between algorithm design and hardware literacy. You cannot fully explain the speedup from the math alone.
MayaOne listener question might be: if attention is still quadratic, why is this such a big deal? The answer is that real bottlenecks are not only asymptotic. For sequence lengths teams actually use, memory traffic and materialization can dominate practical cost.
LeoSo Flash Attention does not repeal the math. It makes the existing math travel through the machine more intelligently.
MayaThat distinction helps avoid hype. It enables longer contexts and faster training within a regime, but it does not mean infinite context is suddenly free.
LeoExactly. It changes the frontier. And once the frontier moves, model designers start asking more ambitious questions about sequence length, batch size, and architecture.
MayaBefore we close, let’s turn this into an implementation review. If a team brought you a Flash Attention deployment, the first thing to ask is not whether the method sounds modern. It is whether the measurements show the right problem being solved.
LeoThe review checklist would include attention memory footprint, sequence length, kernel speed, numerical exactness, and end-to-end throughput. That list sounds detailed, but it prevents one-dimensional thinking. A training run can improve one metric and quietly damage another.
MayaAnother review habit is to compare against the simplest baseline. If the fancy method beats a weak baseline but loses to a tuned simple setup, the story is not finished. Distributed training papers are strongest when they cross a hard boundary and still preserve efficiency.
LeoAnd the hardest question is: Did faster attention change the full training step, or only one kernel benchmark? That question keeps the listener grounded in engineering reality instead of buzzwords.
MayaI also like asking what the method makes easier for future work. Some techniques are valuable because they train one model faster. Others are valuable because they let many teams explore model sizes, sequence lengths, or training recipes that were previously out of reach.
LeoThat is the broader theme of Topic 3. Distributed training is not just about bragging rights. It changes the experiments researchers can afford to run, and those experiments shape the models everyone else later uses.
MayaIf someone asks what to remember, say this: Attention is quadratic in sequence length, but the killer in practice is often the giant attention matrix moving through memory. Flash Attention computes exact attention while avoiding unnecessary reads and writes.
LeoAnd for anyone who wants to go deeper, we’ll include the primary material and extra reading notes in the episode metadata. This is one of those topics where diagrams, source links, and implementation notes really help.
MayaWhen an algorithm is slow, how often is the real issue not the formula, but the route the data takes through hardware?
LeoHold onto that question. In the next episode, we keep following the same theme: find the bottleneck, then decide whether to split, shard, move, recompute, or rethink the training plan.
CreditsThanks for listening. The producer is William Liu. Join us for the next episode.
Source material
← Back to Mastering Language Models: From Architecture to Optimization