
Transcript
Generated: 2026-05-10 03:14 UTC
---
MayaBefore we jump in, here's a quick setup for this episode on t3e2_megatron_lm_tensor parallelism. You'll hear Maya and Leo work through the topic together.
MayaGPipe splits the model by layers. Megatron-L M asks a sharper question: what if one layer is already too big?
LeoA good way to hear today’s paper is this: the bottleneck is not one thing. It is a stack of limits, and this episode picks one layer of that stack.
MayaGPipe gave us an assembly line across layers. Megatron-L M moves inside the layer, especially inside the giant matrix multiplications that dominate Transformer computation.
LeoSo the listener should not picture a neat whiteboard equation only. They should picture a training job as a living system: chips, memory, network links, data loaders, kernels, and a clock that punishes every idle moment.
MayaExactly. Tensor parallelism splits the math of a layer across devices. Instead of G P U A owning layer 10 and G P U B owning layer 11, both GPUs cooperate on layer 10.
LeoGive me the everyday version before we go technical.
MayaTake a feed-forward layer that multiplies an activation matrix by a very large weight matrix. Megatron can split that weight matrix across GPUs. Each G P U computes part of the result, then the system communicates just enough to reassemble the information needed for the next operation.
LeoNice. That makes the paper feel less abstract. But what is the specific move?
MayaFirst, megatron-L M implements a simple intra-layer model-parallel approach for Transformer language models using native Py Torch plus a few communication operations.
LeoThis is where the mental model matters. In other words, the system is not only asking, “Can we compute this?” It is also asking, “Can we store it, move it, and synchronize it before the GPUs go idle?”
MayaSecond, the paper reports training Transformer models up to 8.3 billion parameters using 512 GPUs and sustaining 15.1 petaFLOPs with 76 percent scaling efficiency relative to a strong single-G P U baseline.
LeoThat is the part many people miss. The win is not just academic elegance. The win is making a training run cross a hard boundary: fits versus does not fit, stalls versus keeps flowing, theoretical speed versus actual wall-clock speed.
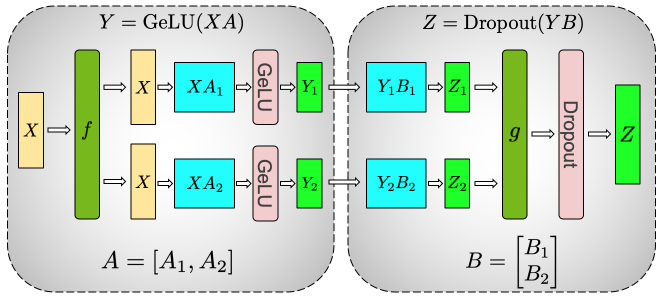
MayaThird, its key insight is that Transformer matrix multiplications can be split along rows or columns, with communication inserted at points where partial results must be combined.
LeoSo we should treat this as a design pattern, not a one-off trick. The pattern is: find the hidden resource that is being wasted, then redesign the training loop around it.
MayaIn a Transformer, the big operations are matrix multiplications in attention and the feed-forward network. Megatron-L M looks at those matrices and asks how to split them so the communication lands in predictable, manageable places.
LeoThis is more delicate than GPipe, right? With GPipe, a stage owns full layers. With tensor parallelism, multiple GPUs cooperate inside the same layer.
MayaRight. That means communication is more frequent, but the split can unlock models where a single layer or activation path is too large or too compute-heavy for one device.
LeoAnd because it is built around Transformer structure, the trick is not arbitrary. It uses the fact that attention projections and feed-forward matrices have natural dimensions to split.
MayaYes. The paper’s appeal is that the implementation can be relatively simple compared with building an entirely new compiler or training stack.
LeoHere is the expert disagreement I hear underneath this episode: Is tensor parallelism worth the communication cost?
MayaThe strongest arguments are both reasonable. Yes when one layer is too large or when the matrix multiplies are big enough that computation dominates. No when the splits create too many synchronization points or the network interconnect cannot keep up.
LeoAnd the practical answer is usually not ideological. It depends on the model shape, sequence length, hardware topology, training objective, and how much engineering time the team has.
MayaTensor parallelism can look like “just split the matrix,” but the layout matters. Split the wrong dimension and you may introduce extra all-reduces or move huge tensors at the worst possible time.
LeoLet’s add a concrete listener check. If you were debugging this in a real training run, what would you measure first?
MayaI would measure all-reduce time, matmul utilization, tensor shapes, and whether communication is overlapping with compute or creating hard synchronization barriers.
LeoThat makes this episode useful beyond the paper. It gives the listener a diagnostic habit. Do not memorize the technique first. Find the bottleneck first.
MayaThe communication primitive to listen for is all-reduce. Each worker computes part of something, and then the partial results have to be combined. Good tensor parallel layouts minimize how often that global conversation happens and how large the messages are.
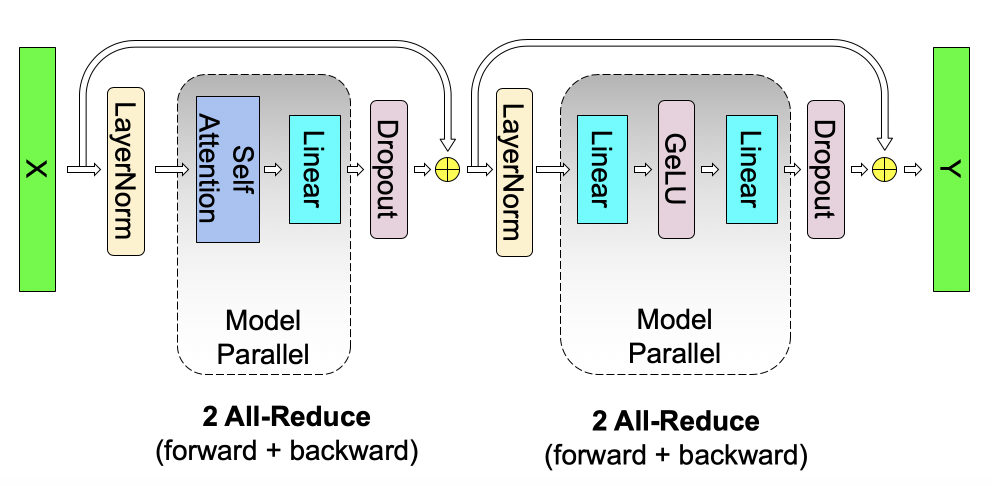
LeoThat is a nice way to say it. Tensor parallelism is not merely dividing math; it is designing conversations between GPUs. Some conversations are cheap and local. Some are expensive and block progress.
MayaThis is also why hardware topology matters. A tensor-parallel group often wants very fast links because its members synchronize frequently. Put those GPUs across a slower network boundary and the same algorithm may look much worse.
LeoSo Megatron-L M is a model-parallel paper, but it is also a reminder that Transformer math and cluster layout need to be designed together.
MayaInside a Transformer block, the attention projections and feed-forward layers are mostly dense linear algebra. Megatron-L M uses the structure of those operations. Some matrices can be split column-wise, others row-wise, so partial results compose cleanly.
LeoThat is more concrete than saying “split the layer.” It means the algebra decides the communication pattern. If the split aligns with the next operation, communication can be delayed or reduced.
MayaYes. For example, one projection may produce separate chunks that can flow into the next local computation before being combined. Another operation may require an all-reduce so every worker sees the complete result.
LeoThe training engineer’s job is to make those expensive moments rare and well overlapped.
MayaMegatron also matters historically because it made giant Transformer training feel implementable with relatively small changes in a familiar framework. That influenced later systems that combine tensor, pipeline, and data parallelism.
LeoSo if GPipe is the assembly line across layers, Megatron is the shared workbench inside a layer. Both are useful, but they solve different physical constraints.
MayaConsider the feed-forward network in a Transformer. It often expands hidden dimension, applies a nonlinearity, then projects back down. Those large projection matrices are natural candidates for parallel splits because each device can compute a slice of the intermediate representation.
LeoBut after slices are computed, the next layer may need the full representation. That is where communication returns. The algorithm is constantly negotiating between local work and global agreement.
MayaAttention projections create a similar opportunity. Query, key, and value computations can be arranged so work is distributed across devices. But the shape of heads, hidden dimension, and batch/sequence dimensions affects the best split.
LeoSo Megatron-style tensor parallelism is not just a historical paper. It is a way to think about the Transformer as a set of divisible linear algebra operations.
MayaBefore we close, let’s turn this into an implementation review. If a team brought you a tensor-parallel Transformer block, the first thing to ask is not whether the method sounds modern. It is whether the measurements show the right problem being solved.
LeoThe review checklist would include matmul efficiency, all-reduce cost, tensor shape layout, and topology-aware grouping. That list sounds detailed, but it prevents one-dimensional thinking. A training run can improve one metric and quietly damage another.
MayaAnother review habit is to compare against the simplest baseline. If the fancy method beats a weak baseline but loses to a tuned simple setup, the story is not finished. Distributed training papers are strongest when they cross a hard boundary and still preserve efficiency.
LeoAnd the hardest question is: Did the matrix split reduce memory or compute pressure without creating a worse communication wall? That question keeps the listener grounded in engineering reality instead of buzzwords.
MayaI also like asking what the method makes easier for future work. Some techniques are valuable because they train one model faster. Others are valuable because they let many teams explore model sizes, sequence lengths, or training recipes that were previously out of reach.
LeoThat is the broader theme of Topic 3. Distributed training is not just about bragging rights. It changes the experiments researchers can afford to run, and those experiments shape the models everyone else later uses.
MayaIf someone asks what to remember, say this: Tensor parallelism splits the math of a layer across devices. Instead of G P U A owning layer 10 and G P U B owning layer 11, both GPUs cooperate on layer 10.
LeoAnd for anyone who wants to go deeper, we’ll include the primary material and extra reading notes in the episode metadata. This is one of those topics where diagrams, source links, and implementation notes really help.
MayaWhen a model layer becomes a team sport, where should the teammates pass the ball?
LeoHold onto that question. In the next episode, we keep following the same theme: find the bottleneck, then decide whether to split, shard, move, recompute, or rethink the training plan.
CreditsThanks for listening. The producer is William Liu. Join us for the next episode.
Source material
← Back to Mastering Language Models: From Architecture to Optimization