
Transcript
Generated: 2026-05-10 22:05 UTC
---
LeoBefore we jump in, here's a quick setup for this episode on t1e1_attention_is_all_you_need_the_transformer breakthrough. You'll hear Leo and Maya work through the topic together.
LeoThe title sounds almost like a dare: Attention Is All You Need. Not “attention helps.” Not “attention plus recurrence.” Just attention.
MayaAnd the paper really did make that claim in a specific setting: sequence transduction, especially machine translation. For extra reading, the original paper is in the show notes, and this is one where looking at the diagrams helps.
LeoQuick recap from the topic overview: Transformers changed sequence modeling by removing recurrence and using self-attention to route information between tokens.
MayaLet’s define the problem the paper was attacking. In translation, you take an input sentence, like English, and produce an output sentence, like German or French. Earlier systems often used encoder-decoder models with recurrent layers.
LeoThe encoder reads the input. The decoder writes the output. Attention had already been used to connect the decoder back to relevant input positions. The new move was: why keep the recurrent layers at all?
MayaSo the Transformer has an encoder stack and a decoder stack, but each stack is built from attention and feed-forward blocks. The encoder reads the source sentence. The decoder generates the target sentence while attending to the encoder output and to earlier generated target tokens.
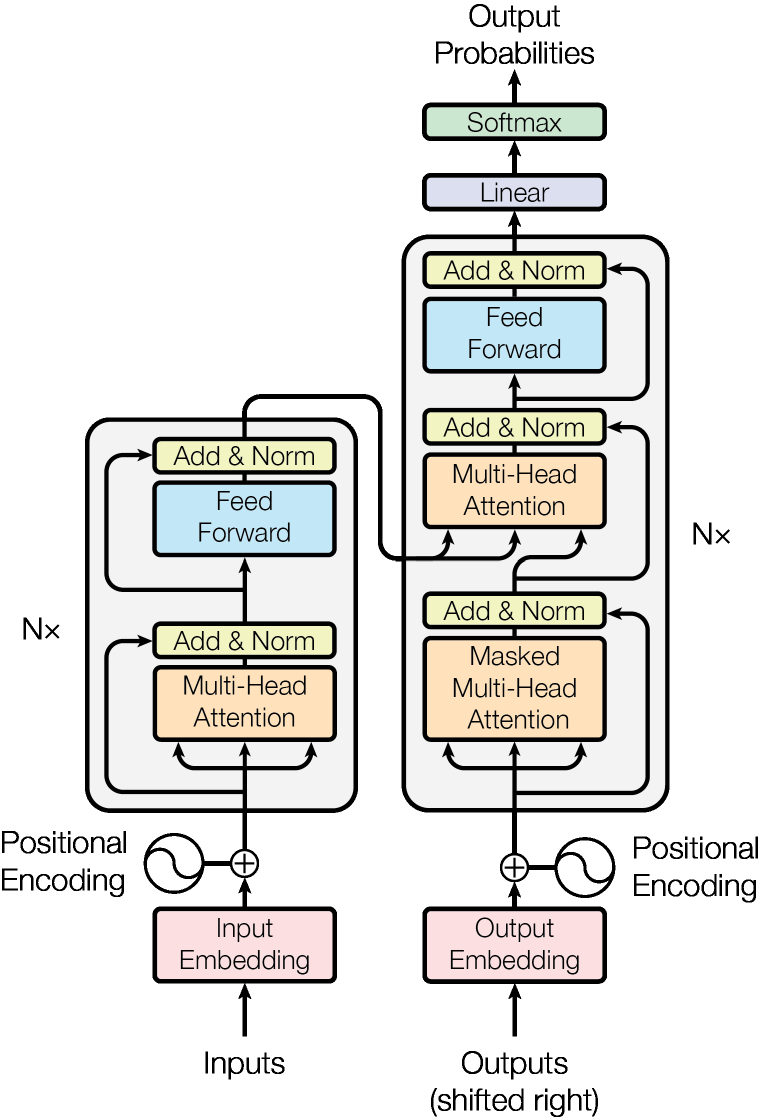
LeoThe first big building block is scaled dot-product attention. That sounds heavy, but the story is simple. Each token creates a query, a key, and a value.
MayaLibrary analogy. Query: what am I looking for? Key: what label does each piece of information advertise? Value: what information do I actually retrieve?
LeoThe model compares the query to all keys, turns those comparison scores into weights, and takes a weighted mix of the values. The “scaled” part keeps the dot products from getting too large when the vector dimension grows.
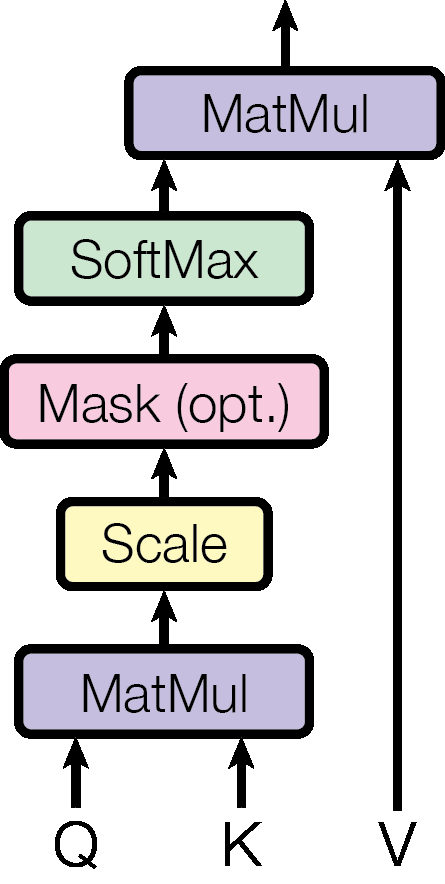
MayaThat scaling detail matters because without it, the softmax can become too sharp. In plain language, the model might become overly confident too early and gradients become less useful.
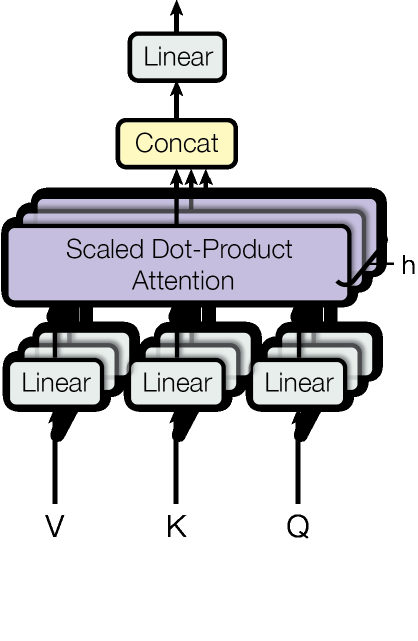
LeoThen comes multi-head attention. Instead of one attention operation, the model runs several smaller attention operations in parallel. Each head can focus on different patterns.
MayaI like to think of it as a group of editors reading the same sentence with different highlighters. One tracks subject-verb relationships. One tracks pronouns. One tracks nearby phrase structure. Again, we should be careful: heads do not always have neat human labels. But the design gives the model multiple relation channels.
LeoThe paper also uses feed-forward networks after attention. Attention mixes information across positions. The feed-forward part processes each position independently. Then the next layer repeats the pattern.
MayaSo one layer asks, “Which other tokens matter to me?” and then, “Now that I have that information, how should I transform my representation?”
LeoAnother important piece is residual connections and layer normalization. Residual connections let information skip around a block, which helps optimization. Layer normalization keeps activations in a manageable range.
MayaFor listeners not deep in neural network training: residual connections are like keeping the original draft while you edit. Instead of forcing each layer to rewrite everything from scratch, the model learns changes on top of what was already there.
LeoNow the weird part. If the model has no recurrence and no convolution, how does it know word order?
MayaPositional encoding. The original Transformer adds a position signal to each token embedding. The paper used sine and cosine functions at different frequencies, although learned position embeddings are common in later models too.
LeoThe point is that “dog bites man” and “man bites dog” should not look the same. Attention gives relationships, but position tells the model where things sit in the sequence.
MayaLet’s talk about masking, because it is easy to miss. In the decoder, the model should not peek at future target words during training. If it is predicting word five, it can look at words one through four, but not six or seven.
LeoThat is called causal masking. It blocks attention to future positions, preserving the left-to-right generation setup.
MayaThe paper’s results were strong for translation. The Transformer achieved high B L E U scores on W M T 2014 English-to-German and English-to-French, and the authors emphasized faster training and better parallelization than recurrent or convolutional alternatives.
LeoB L E U is a translation quality metric. It is imperfect, but at the time it was a common way to compare systems.
MayaWhat made the result feel bigger than translation was the recipe. The architecture was simple, repeatable, parallel, and scalable.
LeoLet’s bring in an everyday example. Imagine you are summarizing a long email thread. A recurrent model reads message by message, compressing history as it goes. A Transformer-like model can compare parts of the thread directly: this deadline mention, that follow-up, the earlier decision, the final approval.
MayaThat direct comparison is powerful. But it also costs memory and compute. Every token looking at every token is a lot of pairwise interaction.
LeoWhich is why later research tries to make attention cheaper. But the original paper’s dense attention was a clean baseline: if flexible context mixing matters, start with the full version.
MayaOne thing I want to emphasize: the Transformer did not make language models “understand” in a human sense by adding a magic module. It changed the training dynamics. It made it easier to train large sequence models efficiently.
LeoThat is the technical and historical punchline. The architecture’s usefulness came from both representation and engineering.
MayaLet’s name some expert disagreements around the paper. First: interpretability. Some people see attention weights as a window into what the model is using. Others argue attention weights are not reliable explanations of model behavior.
LeoStrongest pro-attention-interpretability argument: attention maps can reveal patterns and are more inspectable than many hidden operations. Strongest skeptical argument: a model can attend in ways that do not match causal importance, so attention visualizations can mislead.
MayaSecond disagreement: whether recurrence was truly obsolete. In language modeling, Transformers mostly won the mainstream, but recurrence-like ideas keep returning for long context and streaming tasks.
LeoThe pro-Transformer side says parallel training and flexible attention dominate. The recurrence-friendly side says some tasks need efficient persistent state, especially when context becomes very long.
MayaThird disagreement: architecture versus data and scale. Was the Transformer the breakthrough, or was it the thing that let data and compute become the breakthrough?
LeoMy answer would be: the architecture changed what scale could buy.
MayaNice. Not “architecture instead of scale,” but “architecture made scale more productive.”
LeoNow, where does this paper show up in modern Large Language Models? Decoder-only Transformers are the backbone of many generative language models. They use causal self-attention to predict the next token. Encoder-only variants, like B E R T-style models, are used for understanding tasks. Encoder-decoder variants still appear in translation and other sequence-to-sequence tasks.
MayaSo the original paper’s encoder-decoder design is not identical to every modern Large Language Model, but the core components traveled everywhere: self-attention, multi-head attention, stacked blocks, position handling, residuals, normalization.
LeoLet’s give listeners a practical mental checklist. When you hear “Transformer,” ask four questions. What tokens can attend to what other tokens? How is position represented? How long is the context? And how expensive is the attention pattern?
MayaAlso ask: what is being optimized? Translation? next-token prediction? instruction following? retrieval? tool use? The architecture is a base, not the whole system.
LeoThis is why Topic 2 follows naturally. Once the Transformer became the standard, researchers could ask scaling questions more cleanly: if we keep the broad architecture and increase model size, data, and compute, what happens?
MayaThe scaling-law papers are less about inventing a new block and more about budgeting a giant experiment. How many parameters? How many tokens? When do we stop training?
LeoBefore we close, let’s recap the paper in one breath. The Transformer replaced recurrent sequence processing with stacked attention and feed-forward blocks. It used multi-head self-attention to let tokens route information directly, positional encodings to preserve order, and parallelizable computation to train faster.
MayaAnd it gave the field a design that was not just better on a benchmark, but better matched to the hardware and ambitions of the next decade.
MayaLet’s also talk about why the title became iconic. It was not claiming that human attention is all intelligence needs. It was saying that, for the sequence-transduction architecture they studied, attention could replace the recurrent and convolutional sequence layers.
LeoThat distinction matters because the phrase has been stretched over the years. The paper is bold, but it is still an engineering paper with experiments, ablations, and a target task.
MayaAnother detail worth hearing: the original Transformer uses both encoder self-attention and decoder self-attention, plus encoder-decoder attention. Decoder-only language models later simplified the setup for next-token prediction.
LeoRight. So if someone says, “Generative Pre-trained Transformer is a Transformer,” that does not mean it is the exact model from the 2017 translation paper. It means it inherits the central block design, especially causal self-attention.
MayaThe paper also helped shift how researchers thought about sequence length. Older models could, in principle, carry information forward, but long chains were hard. Attention shortened the path between tokens.
LeoA path-length example: if token one needs to influence token twenty, a recurrent model passes information through many steps. In a self-attention layer, token twenty can attend directly to token one. That shorter path can make learning relationships easier.
MayaBut shorter path is not free. The model computes many pairwise scores. So the same feature that helps long-range dependency also creates the long-context cost problem.
LeoThat tension — direct access versus computation cost — is one of the permanent Transformer trade-offs.
LeoFinal question for listeners: if attention lets the model connect anything to anything, is the future about making those connections bigger, or making them more selective?
CreditsThanks for listening. The producer is William Liu. Join us for the next episode.
Source material
← Back to Mastering Language Models: From Architecture to Optimization