Subscribe
Transcript
Maya—no, I'm telling you the single most expensive mistake in this whole pipeline isn't what's inside a record. It's where the record is allowed to go. One card on both sides of the train-test line and your benchmark is fiction.
LeoAnd I'm telling you you're inflating a filing error into a catastrophe. A record drifts from the train pile into the eval pile — okay, you patch it, you re-run, you move on. That's not the most expensive mistake in the pipeline. That's a Tuesday.
MayaA Tuesday. Walk it through with me. A team trains an agent on their full data lake. Benchmark goes up — eighty-something, climbing every week. Champagne. Then a skeptic pulls one task out of the eval set, searches the training data, and finds it. Same repo. Same bug. Same fix. The model didn't learn to debug. It learned to recite.
LeoSo the eighty wasn't a capability score. It was a memorization score wearing a capability costume.
MayaAnd nobody put it there on purpose. No one sat down and said "let's leak the answers." The same repo just showed up on both sides, and the wall between studying and testing quietly came down. That's not a Tuesday. That's the number being a lie and nobody knowing.
LeoOkay — that one I'll grant you.
MayaThat's the whole episode. Every other drawer we've opened this topic is about what a record contains. Today's is about where a record is allowed to go.
LeoTelemetry was about pulling gold out of your product's exhaust — and you spent the back half hammering one thing: the data's worthless unless you build the privacy and secret and contamination plumbing first. Today isn't about mining the gold. It's about where that plumbing is allowed to send it.
MayaThe gauntlet. Guilty until proven clean.
LeoToday's the drawer that plumbing actually lives in. We've name-dropped governance for four episodes. Now we open it.
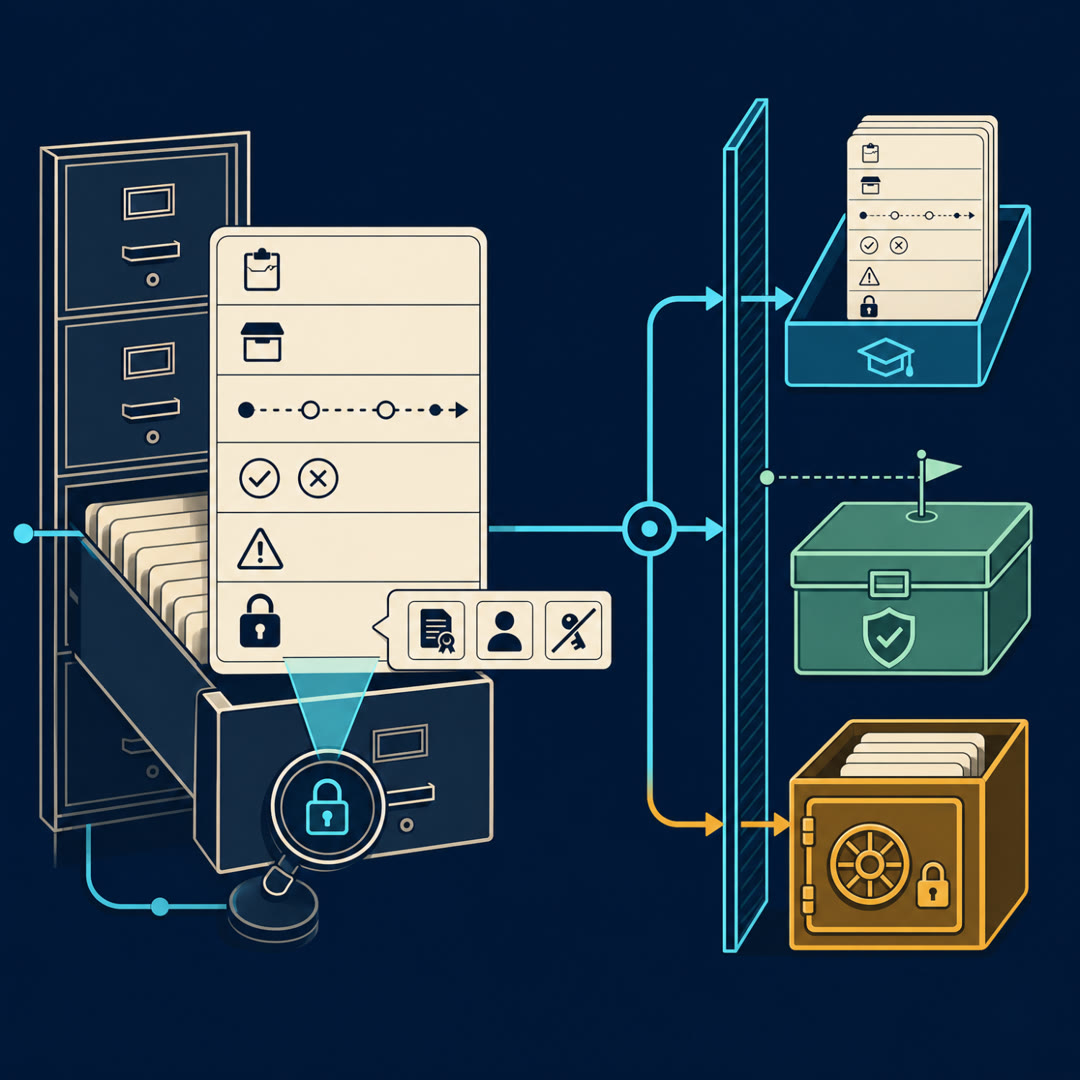
MayaThe last drawer of the cabinet. And it's the one engineers love least, because it feels like paperwork — license fields, scan results, a little flag that says "this one's eval-only." Boring. Until you realize it's the drawer that decides whether any of the other five drawers are trustworthy or legal.
LeoMake that concrete. Same record card we've carried all topic — the one bug-fix run, the chart of one piece of work. What's actually written in the governance drawer for it?
MayaPicture the card. Five drawers above already filled in — the task, the runnable environment, the trajectory, the verification labels, the failure notes. The governance drawer at the bottom holds the answers to four questions reality doesn't answer for you. Whose code is this and are we allowed to learn from it. Is there anything poisonous hidden in it. Does this record overlap our exam. And — the one we'll spend the most time on — is this card a study card or a test card.
LeoHold on, those are two different jobs sharing one drawer. The first three sound like a clearance check. The last one sounds like... filing.
MayaThat's exactly the right cut, and almost nobody draws it. Governance is two jobs wearing one coat. One job is clearance — may this record exist in our corpus at all. The other is placement — given that it's allowed in, which pile does it belong to. Clear it, then sort it. Let's take them in that order, because you can't sort a record you haven't cleared.
LeoClearance first. What's the gate?
MayaThree checks, and they're not new to you — we met them as part of the telemetry gauntlet. License: do we have the right to train on this code at all. Private information: is there a real person's data sitting in this record. Secrets: is there a live credential — an API key, a token — buried in a log line.
LeoAnd we said the brutal rule on that last one. A secret doesn't fail the line.
MayaIt fails the record. The whole card goes to quarantine. Because a model has no delete key — once a token's in the weights, you can't un-leak it.
LeoYeah.
MayaHere's the one twist governance adds on top of the telemetry version. In the governance drawer, these aren't a one-time scan you run and forget. They're a standing flag on the card. License: cleared. Secret-scan: passed, this date. Private-info: redacted, here's what. So that six months later, when somebody wants to ship a dataset built from these cards, the clearance travels with the data and they don't have to re-litigate every record.
LeoSo governance metadata is the receipt. The record can prove it was allowed.
MayaProvenance. A record that can't prove where it came from and what was checked is a liability, not an asset — no matter how good the engineering inside it looks. Okay. Clearance done. Now the interesting half. Placement.
LeoThe study-card-versus-test-card split.
MayaThe split. And I want to slow down here, because this is where smart teams quietly destroy their own ability to measure anything. The job sounds trivial — take your pile of cleared records, put most of them in the training bin, hold some back for evaluation. Done, right?
LeoThat's what every machine-learning tutorial says. Shuffle, take ninety percent for train, ten for test.
MayaAnd for agentic coding data, that shuffle is the bug. That random ninety-ten split is exactly how you end up with my opening story — the model reciting an answer it saw in training and you calling it a capability.
LeoWait, walk me through why random breaks here specifically. Random split is the textbook move. What's different about code?
MayaBecause the unit you're shuffling isn't independent. Think about what's actually in these cards. You don't have ten thousand unrelated problems. You have, say, four hundred problems pulled from forty repositories. Ten cards from this repo, ten from that one. The cards inside one repo share DNA — the same code style, the same helper functions, the same maintainer's habits, sometimes literally the same files touched in two different tickets.
LeoOh.
MayaSo you shuffle and split randomly. Now eight cards from repository X land in train and two land in test. The model studies eight examples of that exact codebase, that exact author's patterns, that exact test harness — and then you "test" it on two more from the same codebase. It's not solving a new problem. It's finishing a crossword it already saw most of.
LeoSo a high score on that split isn't lying exactly. It's measuring the wrong thing — it's measuring "can you do more of what you just saw," not "can you do something new."
MayaThat's it precisely. Near-duplication is the silent killer. And it gets worse, because code has a second axis the textbook split ignores entirely. Time.
LeoTime how?
MayaA repository in twenty-twenty-three and the same repository in twenty-twenty-five are basically two different codebases — refactors, renamed modules, new frameworks. If you train on a snapshot from this year and test on a snapshot from two years ago, you've let the model peek at the future of that codebase. The fix it "discovers" in the test, it may have already seen the downstream version of in training.
LeoHuh.
MayaSo the curriculum names the discipline plainly — train-eval separation. And the practitioners' version of it is a rule with teeth: the split has to be structural, not random.
LeoOkay, but here's where I want to actually fight you, because I think you're about to make me pay too much for purity.
MayaGo. This is the real argument in the field, so let's have it.
LeoFine. You want a structural split — hold out entire repositories, hold out by time, never let a repo straddle the line. I get the contamination logic. But count the cost.
MayaGo on — what does it actually cost you?
LeoI've got forty repos. My hardest, richest, most realistic data — the gnarly multi-service bugs — those cluster in maybe five big repos. If I hold whole repos out for eval, I'm yanking my best training material out of training. I'm starving the model of exactly the hard cases it most needs to learn from, to protect a benchmark.
MayaYou're not starving it. You're refusing to grade it on a test it already studied. Those are different—
Leo—they're different in theory. In practice I have a finite, expensive pile of real data, and you're telling me to set the best fifth of it on fire so I can measure cleanly. A team with ten thousand synthetic tasks can afford that. A team with four hundred hand-curated real ones cannot. At some point the purity tax is so high you just have a beautifully measured model that's worse.
MayaSo measure with less and train with the hard stuff — you're treating it like all-or-nothing.
LeoBecause the contamination story you opened with says it basically is. One repo on both sides and the number's a lie. You can't half-leak.
MayaOkay. That last point I'll give you — you can't half-leak a repository. If a repo's in train, every test card from it is compromised, full stop. That part of your cost is real and I'm not going to pretend it isn't.
LeoThank you.
MayaBut here's the concession I want back. The expensive thing isn't holding data out. It's holding the wrong data out. You don't have to sacrifice your five gnarly repos to training. You sacrifice a different set of repos to eval — and you keep that eval set small, fresh, and sealed. Your hard repos stay in training where you want them. Your eval is its own protected pocket that nothing in training has ever touched.
LeoSo the move isn't "hold out your best." It's "designate a separate eval reserve up front, before you've trained anything, and never spend it on training no matter how good it looks."
MayaA sealed pocket. The curriculum's word is the private eval — your own held-out set, structurally clean, that you guard like an exam bank. And the discipline that keeps it honest over time is freshness.
LeoDefine freshness, because I think it's the thing that actually resolves our fight.
MayaFreshness means your eval set has a shelf life. Every model you train learns a little more about the kinds of tasks you evaluate on — not by leaking, just by the team steering toward what the benchmark rewards. So a private eval that's two years old has slowly rotted. The fix is to keep pulling new held-out tasks — recent tickets, recent repos, things created after your latest training cut — so the exam is always made of material the model genuinely couldn't have seen.
LeoSo freshness is how I get to keep my hard repos in training and still measure honestly. I don't burn old data for eval. I keep harvesting new data for eval.
MayaThat's the resolution, and it's a real one. You were right that holding out your richest existing repos is a tax not everyone can pay. I was right that a random split is a self-inflicted lie. The thing that satisfies both: a small, structurally separated, continuously refreshed private eval — and your big expensive corpus mostly flows to training.
LeoI'll take that.
MayaAnd there's one instrument that makes the whole thing auditable, which I love because it's almost devious. Benchmark canaries.
LeoCanaries — like the bird in the coal mine?
MayaSame spirit. A canary is a deliberately planted, unique marker — a uniquely-named function, a one-of-a-kind string, a fake task with a fingerprint — that you slip into your eval set and never put in training. Then later you check: did the model ever emit the canary? Does it somehow "know" that unique string?
LeoOh, that's sneaky. If the model coughs up something it could only have learned from the eval set—
Maya—then your wall has a hole in it, and the canary just told you where. It's a tripwire for contamination. You don't have to trust that your split was clean. You can detect when it wasn't.
LeoSo the canary is the thing that turns "we promise the eval is sealed" into "we can prove it, or catch ourselves when it isn't."
MayaWhich is the whole posture of this drawer. Don't trust, instrument. Clearance leaves a receipt. The split is structural, not random. The eval is private, sealed, and refreshed. And a canary watches the wall.
LeoLet me say the drawer back, because this is the one I'd forget. Governance is two jobs in one coat — clearance, then placement. Clearance is license, private-info, secrets, each one a standing flag the record carries as proof. Placement is the split — never random, because near-duplicate cards from one repo and old-versus-new snapshots leak the answers. So you hold out whole repos, keep a private eval that's sealed and kept fresh, and plant canaries to catch leaks you missed.
MayaThat's the drawer. And the one sentence under all of it — a benchmark number is only worth as much as the wall between your training and your test. Weak wall, worthless number, no matter how high it is.
LeoNow the honest limitation, because we've made this sound airtight and nothing's airtight.
MayaIt's not. There's a crack in the wall itself, and then a crack in the politics around it. Start with the wall. Perfect separation is impossible at the edges. The open-source world is one giant shared corpus. A popular bug fix gets blogged about, copied into Stack Overflow, pulled into someone else's repo. You can hold out a repository and still find its DNA scattered across the training set through no fault of your own. You manage contamination. You don't eliminate it.
LeoSo it's a leak you bound, not a leak you close.
MayaBound and monitor. And the crack in the politics is the sharper one — governance has a cost that lands on the wrong people. The team that builds careful splits, refreshes evals, runs canaries — they look slower and their benchmark numbers look lower than the team that just shuffled everything together and reported eighty-five.
LeoRight. [sigh] The honest team posts a worse number than the sloppy one. And the sloppy one wins the demo.
MayaUntil production. The sloppy team's eighty-five was a memorization score, and it evaporates the first time a real user brings a repo the model never saw. The honest team's seventy was real, and it holds. But you have to survive long enough for reality to settle the argument — and that's a political problem, not a technical one.
LeoSo governance isn't just plumbing. It's the discipline to report the lower honest number when a higher dishonest one is right there.
MayaThat's the drawer nobody wants and everybody needs. It doesn't make your model better. It makes your knowledge about your model true. And a model you understand is worth more than a model that scores well on an exam it already took.
LeoHere's what I'd leave the listener holding.
MayaGo.
LeoThink about the last benchmark number you trusted — yours or one in a paper. You don't get to see how the train and test sets were separated; you just see the number. So here's the question: if that wall had a quiet hole in it, what would even tip you off — and have you ever actually checked, or did you just believe the score because it was high?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents