Subscribe
Transcript
MayaA patch can pass every automated check you own and still be the wrong thing to ship. That's the claim, and it isn't a paradox — it's the whole reason verification needs more than one label. Watch it happen. The agent fixes the bug. Public tests — green. Hidden tests — green. The verifier model scores it high. Every machine that looks at this patch says yes. So it goes up for review, and the senior engineer reads it for ninety seconds and rejects it.
LeoRejects a patch that passed everything.
MayaPassed everything. Her note is one line — "this works, but nobody will be able to maintain it." And here's the part that matters for today. When the team files this run, what label do they write down? Because "all tests passed" and "rejected by review" are both true, and they point in opposite directions.
LeoThe green checkmark and the human disagree — and you've got to record both without pretending one of them is the answer.
MayaThat gap — green machine, red human — that is the episode.
LeoVerification. That's the drawer we're standing in front of now — the labels that say whether a patch was any good. And it pairs with the one we just closed: the trajectory drawer, the recording of how the agent drove, where the failed-and-recovered runs turned out to be the richest thing in there once you label them step by step.
MayaThe drive, not just the destination.
LeoToday we move one drawer down. Verification. And on the surface that sounds like the easy drawer — did the tests pass, yes or no, done. I suspect you're about to tell me it's the opposite.
MayaIt's the drawer where people think the work is a checkbox and it's actually a ladder. The whole idea fits in one line — training teams need labels beyond pass/fail. The whole episode is unpacking why "beyond" is doing enormous work in that sentence.
LeoOkay. Ground the listener first. What's wrong with pass/fail? It's clean. It's cheap. A test runs, it's green or it's red.
MayaNothing's wrong with it — as far as it goes. A passing test is a fact. It certifies that the code ran and produced the expected output on the cases someone wrote down. That's real and it's valuable. The trap is treating that fact as a judgment. Green tells you the code works. It does not tell you the code is good.
LeoGreen is a fact, good is a judgment.
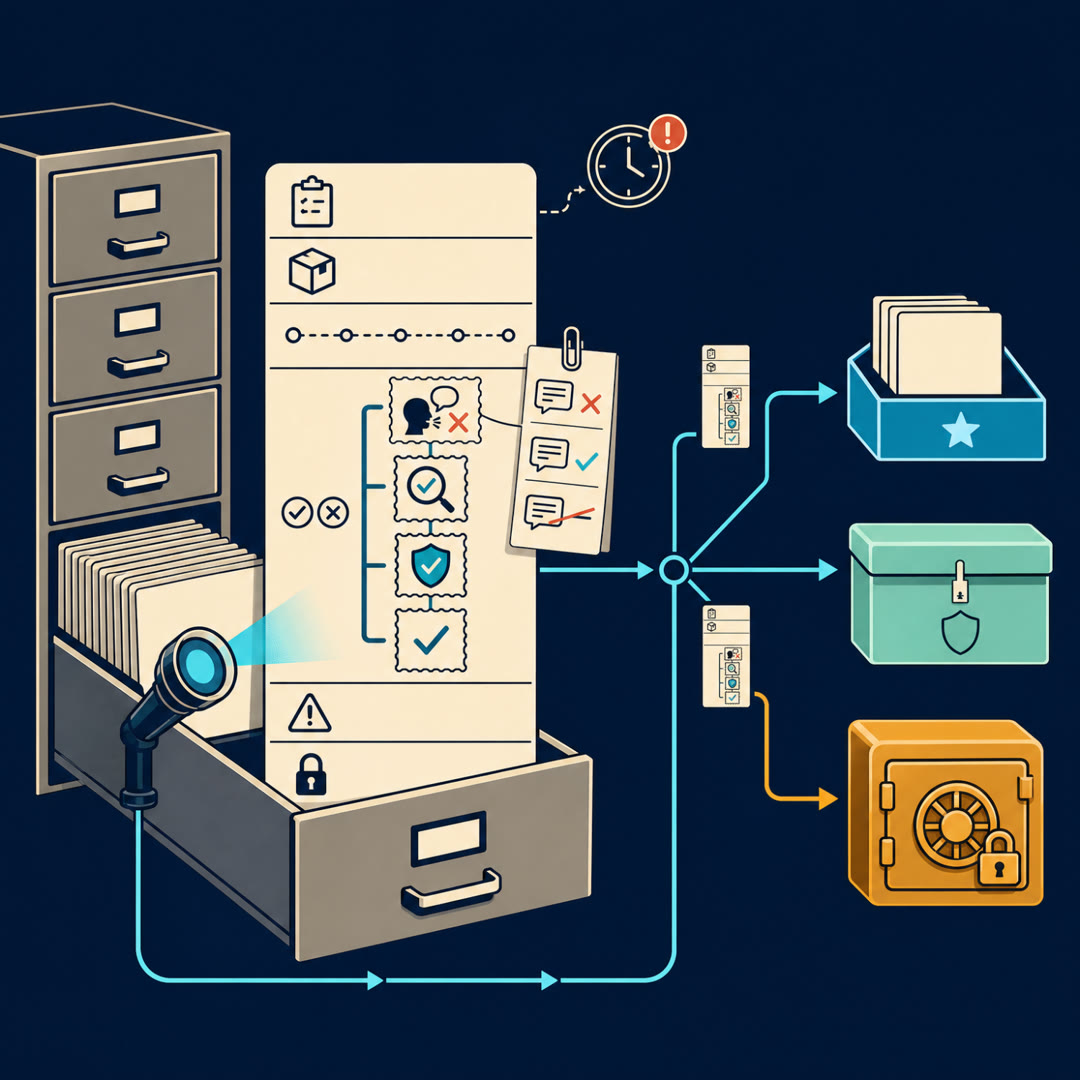
MayaAnd those are two different stamps. The bug-fix run we've been carrying all topic — one ticket, one record card — its verification drawer isn't a single yes. It's a little row of stamps, and they don't all come from the same kind of grader.
LeoAnd that's the ladder we built two topics back — public tests at the bottom, then the held-back hidden tests, then the verifier score, then human review at the top.
Maya{bc} Mm-hm — that's the one. I won't re-walk every rung, we did that with the verifier-versus-tests material. The one thing I'd carry forward is what people miss about it: those rungs aren't four ways of measuring the same quantity. They measure different things, and the higher you climb, the more it's about judgment and the less it's about execution.
LeoWhen you said "labels beyond pass/fail" — the beyond is everything above the test line.
MayaThat's the drawer. Code quality. Maintainability. Did review accept it. How severe were the problems. Which comments the author actually acted on. Whether it broke something two weeks after it merged. None of those are a test result. All of them are labels a training team would kill for.
LeoLet me slow down on one, because it sounds the softest and I bet it's the most useful. "Review acceptance." That's just... did a person say yes?
MayaIt's richer than yes. Picture the review not as a verdict but as a little transcript. The reviewer leaves comments — this line's wrong, this name is confusing, this could leak memory. Each comment has a severity — is this a blocking defect or a nitpick. Then the author responds. And then — this is the gold — does the author actually apply the fix, or argue it down, or ignore it.
LeoThe label isn't "approved" at all. It's the whole back-and-forth.
MayaAnd the single most valuable field in that whole exchange isn't the comment at all. It's whether a developer acted on it. A review comment that got applied is a comment that was right and useful. A comment that got ignored — even a polite one — was noise. The action is the truth signal.
LeoHuh. So you're saying the human's behavior labels the reviewer, not just the patch.
MayaThat's exactly it, and that's the door into the real argument of this episode — because once you accept that a review comment is only worth what someone does about it, you have to ask what a good reviewer even is. And serious people split hard on that.
LeoThen let's have it. What's the split?
MayaIt comes straight out of the review-quality material. Two camps on what makes a code reviewer — human or agent — actually good. One camp says the whole job is recall. The other says the whole job is trust. And they pull in genuinely opposite directions.
LeoGive me recall, because I think recall is obviously right and I'll defend it. The entire reason a reviewer exists is to catch the bug before it ships. A missed defect is the expensive one — it's the null-pointer that pages someone at 3 a.m., the security hole nobody saw.
MayaSo catch everything, and sort it out later?
LeoIf your reviewer is quiet and polite and misses the one comment that mattered, it failed at the only job that counts. So I want a reviewer that flags everything even slightly suspicious. Catch the bug. I'll tolerate some noise to never miss the big one.
MayaAnd you'll lose the reviewer entirely. Because here's what actually happens to the everything-flagger. It leaves forty comments on a pull request. Thirty-five are nitpicks or flat wrong — a style opinion, a hallucinated bug, a "did you consider" that you obviously did. The developer reads the first ten, realizes most are junk, and starts skimming.
LeoSure, but skimming isn't ignoring — the real bug's still in there.
MayaIt is, and that's the trap. By comment thirty they've muted the whole thing. And buried at comment thirty-seven is the real defect — the one your high-recall reviewer did catch — and nobody reads it.
LeoWait — your reviewer that catches it is no better than the one that missed it.
MayaIt's worse. The silent reviewer at least didn't burn anyone's afternoon. The review-quality work says this straight out — high-volume noisy comments reduce trust even when some of them are correct. Recall without precision isn't a good reviewer with a little noise around it. It's a comment feed so loud the developer silences the whole channel — and once that channel's muted, every future comment, right or wrong, lands on a screen nobody's reading.
LeoOkay. That lands.
LeoBut let me hold my ground on the part you can't wave away. Precision taken to its extreme is a reviewer that only ever says one thing, the safest most obvious thing, and stays silent on everything hard. Perfect signal-to-noise — and useless. It never catches the subtle bug because subtle bugs are exactly where you risk a false positive. You can be so afraid of cluttering that feed that you never post the comment that actually mattered.
MayaThat's fair, and I'll give it to you fully. A reviewer optimizing for precision alone goes quiet and timid, and a timid reviewer misses the hard defects that were the point. So neither knob, cranked alone, gives you a reviewer anyone wants.
LeoWe're actually agreeing on the shape, then — it's not recall or precision, it's the ratio, and the ratio is set by what the developer can stand.
MayaAnd that's why the resolution isn't "find the magic balance." It's change what you measure. Stop scoring the reviewer on how many bugs it could theoretically catch, and start scoring it on the signal we already named — did developers act on its comments.
LeoOne label that absorbs both failure modes.
MayaThat single label folds both sides in. A reviewer with great recall but terrible precision gets ignored, and the acted-on rate tells you. A timid reviewer that never flags the hard stuff has nothing to act on, and the acted-on rate tells you that too.
Leo"Did a human act on it" isn't just one nice field. It's the referee for the whole recall-versus-trust fight.
MayaIt's the instrument that settles it. Bug recall is what you'd measure if a reviewer worked in a vacuum. Developer action is what you measure when you admit a reviewer only matters if a tired human takes it seriously at 5 p.m. on a Friday.
LeoThe reviewer who floods the feed gets the channel muted. So measure the muting, not the flagging.
MayaThat's the line. Measure whether anyone's still listening.
LeoLet me make sure I've got the part that's new today, because this is where I'd lose someone. We already know the ladder — tests, verifier, review, bottom to top. What today adds is that the top rung isn't a yes-or-no. The human review is a transcript: comments, severities, and what the author actually did about each one.
MayaAnd the highest-value label in the whole drawer is the quietest one — whether a developer acted on what the reviewer said. Climb the ladder and you move from "did it run" to "should it ship" to "did a human trust it enough to change their code."
LeoThere's one more label you slipped in at the very top and then dropped. Post-merge.
MayaThe honest one. Every label we've talked about so far is a guess made before the code lives in the world. Post-merge is the only one made after. The patch got accepted, it shipped — and then two weeks later it caused a regression. A bug in production. That's a label no test and no reviewer gave you at the time. Reality gave it to you, late.
LeoA patch can be green on every rung of the ladder and still get a red stamp from the world a month later.
MayaWhich is the most sobering thing in the drawer — and the most valuable. A post-merge regression label means every signal you trusted said yes, and they were all wrong together. That's not a label you want a lot of. But the runs that have it are the ones that teach your verifiers what they're blind to.
LeoOkay, the honest limitation, then — because we've been talking like these labels just exist, waiting to be filed.
MayaAnd they don't, not for free, and not cleanly. Every label above the test line is a human judgment, and human judgments are noisy. Two reviewers disagree on whether the same comment was a blocker or a nitpick. Severity is half opinion. "Did they act on it" can mean the comment was right — or just that the author was tired and clicking accept to get to lunch.
LeoSo even your favorite label has a soft spot.
MayaIt does. The rich labels are exactly the expensive, subjective, contestable ones. The clean label — pass/fail — is the one that's cheap and nearly worthless on its own. The valuable labels and the trustworthy labels are pulling against each other, and pretending otherwise is how you train on noise and call it judgment.
LeoThe drawer's whole tension is right there — the labels you most want are the ones you can least trust to be consistent.
MayaThat's the edge of it. Record them anyway — but record who said it and what happened next, never just "good: yes." The disagreement between the green test and the red reviewer isn't a problem to resolve before you file it. It's the label.
LeoHere's what I'd leave the listener turning over.
MayaGo.
LeoThink about the last code review you got — from a person or a tool. If someone had been quietly recording only the comments you actually acted on — not how smart they sounded, just which ones changed your code — would that count say your reviewer was good, or just loud?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents