Subscribe
Transcript
MayaThe first agent is mid-task, writing code against a beautiful instructions file — conventions, style, do this, never do that. It reads it, nods along, ships the change... and nobody ever checks whether it actually followed any of it. Right next to it, a second agent on the same codebase has the opposite setup: linters, tests, a review bot, all firing constantly — but no guidance going in, so it makes the same mistake, gets flagged, makes it again next task, gets flagged again. Forever.
LeoSo one's deaf, one's got amnesia.
MayaThat's it exactly. One steers but never measures. One measures but never learns. And today's source says: the thing that actually works isn't either piece — it's the *loop* you build by wiring them together. That loop is the whole discipline.
LeoAnd it has a name now.
MayaIt does. Harness engineering. Today's article is by Birgitta Böckeler at Thoughtworks, on Martin Fowler's site — and her move is to stop treating all this agent-wrangling as folklore and call it what it is: a branch of software engineering, with parts, a vocabulary, and open research problems.
LeoOkay, but "let's call our tricks a discipline" is a thing people say to sound serious. I want to know what makes it one. By the end I want a test for that.
MayaFair. Hold me to it. If by the close it still sounds like vibes with a fancy hat, you get to say so.
LeoWe just spent an episode getting almost insultingly mechanical — down at the *edit format*, the exact grammar the agent uses to change a file, and how that one choice swings the score like a model upgrade. So today feels like the opposite altitude.
MayaRight — one tiny piece deep inside the wrapper. Today we zoom all the way back out. This is the closing frame for the whole topic. We've spent eight episodes building pieces — context, tools, memory, evaluators, sandboxes, the lot. Böckeler's article is the one that steps back and asks: what *is* the thing we've all been building? And can we engineer it on purpose instead of by accident?
LeoThe wrapper gets a job title.
Maya[chuckle] The wrapper gets a job title, a curriculum, and a list of unsolved problems. Which is honestly the most "real engineering field" thing about it.
LeoStart me at the bottom. What are the actual parts?
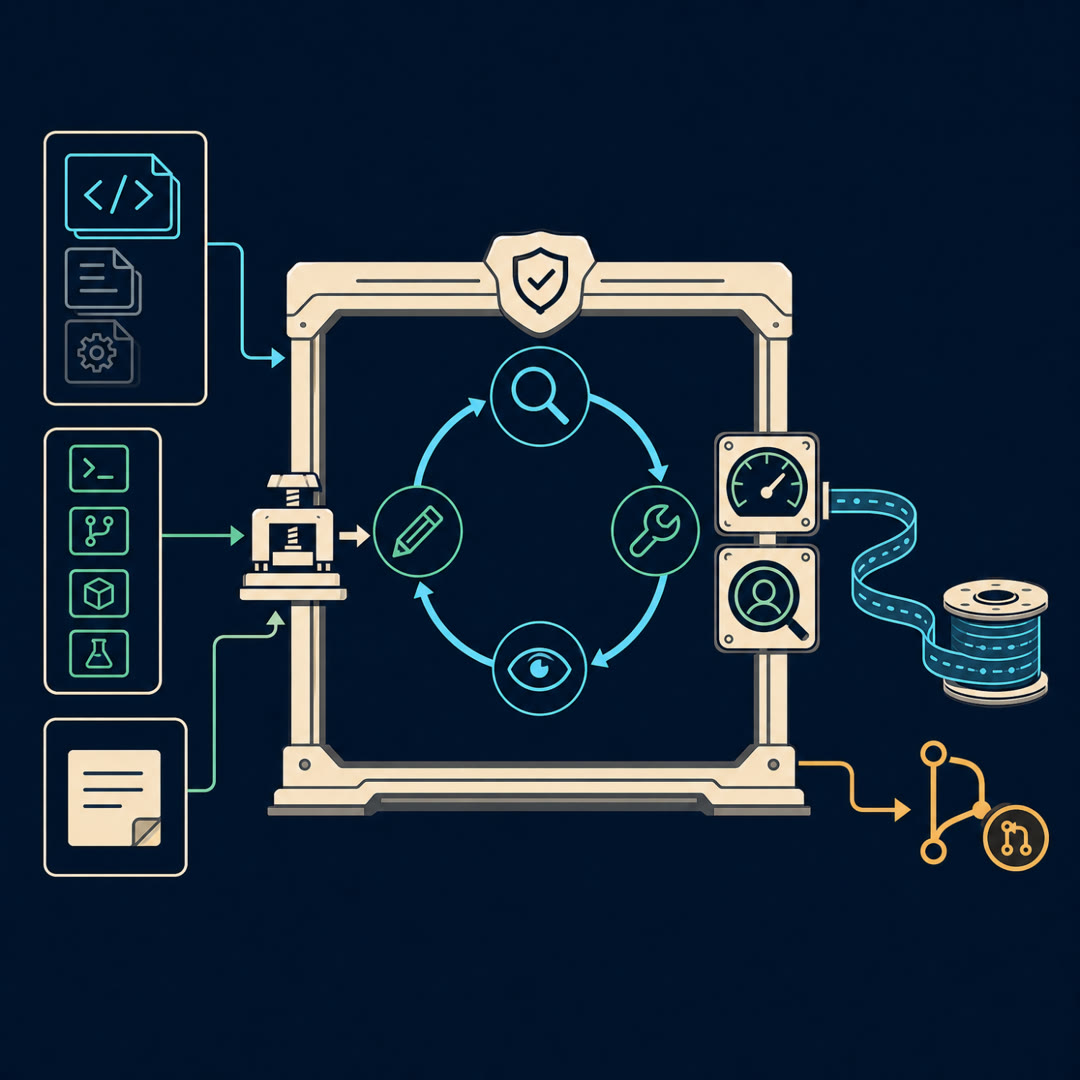
MayaTwo kinds of thing. Böckeler splits the entire harness into Guides and Sensors. And the cleanest way to hear it: a guide acts *before* the agent does something. A sensor acts *after*.
LeoSteering versus catching.
MayaSteering versus catching. A guide is feedforward — you put it in the agent's path so it's more likely to get things right the first time. Your conventions file, your house rules, a script that scaffolds a new service the approved way. A sensor is feedback — it watches what the agent produced and tells it, or you, whether it's any good. A test run. A linter. A review agent reading the diff.
LeoOkay. With me.
MayaAnd here's the line I want to plant early, because it's the heart of it. Böckeler says: separately, you get either an agent that keeps repeating the same mistakes, or an agent that encodes rules but never finds out whether they worked. The capability only shows up when guides and sensors are *connected* — when what the sensor catches feeds back into the guides.
LeoThat's the two-agent thing from the cold open. The deaf one had guides, no sensors. The amnesiac had sensors, no guides.
MayaYes — and now you can see why neither is enough on its own. The deaf one never finds out it's wrong. The amnesiac finds out every single time and never updates. Wire the catch back into the steering and *now* the system gets better over time. That feedback wire is the engineering.
LeoLet me push on sensors, because "a test" and "an AI reviewing your code" are wildly different animals to trust.
MayaThey are, and Böckeler draws exactly that line. Sensors come in two speeds, and you should never confuse them. She calls them computational and inferential.
LeoComputational and inferential. What's each one, concretely?
MayaA computational sensor is deterministic and fast — the CPU runs it. Tests, type checkers, linters, structural analysis. Milliseconds to seconds, and the answer is *reliable*. Red is red. An inferential sensor is the semantic stuff — AI code review, an LLM acting as a judge. Slower, costs more, runs on a GPU, and the answer is... probabilistic. It might be right.
LeoSo one tells you the truth cheaply, the other gives you an opinion expensively.
MayaThat's a sharper way to put it than the article does, and it's correct. And the practical consequence she draws is the useful bit. She maps the *failure modes* of coding agents against these two sensor types. The computational ones reliably catch a whole column — duplicate code, runaway complexity, missing test coverage, architecture drift, style violations. Mechanical stuff. Machines are great at it.
LeoAnd the other column?
MayaThe other column is the scary one. Misdiagnosing the bug. Building three features nobody asked for. Quietly misunderstanding the instruction. Neither sensor reliably catches those. The deterministic one can't see intent. The AI one can take a swing — but, her words, expensively and probabilistically. Not on every commit.
LeoSo the failures that hurt most are exactly the ones your gauges are worst at reading.
MayaThat's the uncomfortable middle of the whole article. The cheap reliable sensors catch the cheap problems. The expensive flaky sensors take a guess at the expensive problems. And the worst failure — an agent confidently doing the wrong correct-looking thing — sits right in the blind spot.
LeoGive me a working picture to hang this on. We keep coming back to the payments service quietly dropping about one transaction in a thousand. Where does that sit today?
MayaThink of a busy restaurant kitchen. Guides are everything upstream of the plate — the prep stations laid out so the line cook reaches for the right thing without thinking, the recipe card clipped above the pass that makes it hard to assemble the dish wrong in the first place. Sensors are the expediter at the pass: every plate stops there and gets checked before it goes out to the room.
LeoSteer the cook, then taste the plate.
MayaSteer the cook, then taste the plate. And the expediter checks in two different ways. Some checks are instruments — a thermometer in the chicken, a scale for the portion. Objective, instant, trustworthy. That's the computational sensor.
LeoAnd the inferential one?
MayaThe inferential check is the chef who actually *tastes* it and goes "...something about the seasoning is off." Often right. Sometimes just having an off night. And you can't have the chef taste every single plate on a Saturday rush — too slow, too expensive. So the rich, semantic judgment is exactly the check you can't run on everything.
LeoSo our dropped-transaction bug — which check would've caught *that*?
Maya[sigh] Honestly? That's the blind-spot example. A dropped transaction one time in a thousand under load — the thermometer reads fine, the portion's right, and even the chef's taste probably passes it, because the plate looks perfect sitting on the pass. That's a behaviour problem. And behaviour, Böckeler says flat out, is the hardest harness of all to build.
LeoWait — "the behaviour harness." You're saying there's more than one harness.
MayaThere are three regulation jobs, and she names them so you stop lumping them together. There's the Maintainability harness — is the code clean, is it the way we build things here. There's the Architecture-fitness harness — does the system keep its intended shape, the right layers talking to the right layers. And there's the Behaviour harness — does the thing actually *do the right thing*.
LeoAnd rank them by difficulty.
MayaThe first two are tractable. Maintainability and architecture have a lot of computational sensors — linters, fitness functions, structural tests. The shape of a system is something a machine can measure. Behaviour is the wall. She's blunt: we still have a lot to do to figure out good harnesses for functional behaviour — good enough that you'd actually reduce human supervision and stop manually testing.
LeoSo the dropped-transaction bug isn't just unlucky. It's sitting in the one category the discipline admits it hasn't cracked.
MayaExactly there. And I want to flag the honesty, because it's rare. The article's whole thesis is "this is a real engineering discipline" — and then it cheerfully tells you the most important third of it is unsolved.
LeoOkay. You told me to hold you to this. Guides, sensors, two speeds, three harnesses — that's a nice taxonomy. A taxonomy isn't a discipline. What's the part that earns the word?
MayaGood — this is the real question. For me it's three moves she makes, and none of them is the vocabulary.
LeoGo.
MayaStart with where she puts it — across the whole lifecycle, not in a tool. Guides and sensors sit at pre-commit, pre-integration, in the pipeline, and in continuous drift-detection running in the background. That's the same shape continuous delivery took when *it* grew up. She even borrows the phrase — keep quality left, catch it as early in the flow as you can.
LeoMm. Lifecycle, not a plugin.
MayaRight. And then the part that actually moved me — the steering loop. The rule is: whenever an issue happens more than once, you don't just fix that instance, you go *improve a guide or a sensor* so it's less likely to ever happen again. The human's job stops being "review every diff" and becomes "tune the system that reviews the diffs."
LeoSo you're not catching fish, you're adjusting the net.
MayaThat's the discipline in one line. You're maintaining the net. And underneath both of those is the move that makes it *engineering* rather than prompting — she names the deep reason the harness has to exist at all. A human developer brings social accountability, a kind of aesthetic disgust at a three-hundred-line function, an instinct that "we don't do it that way here," organisational memory. A coding agent has *none* of that. Zero. So the harness is where you externalise all that tacit human judgment and make it explicit and enforceable.
LeoHuh. Okay. That one actually lands. The harness is the org's taste, written down and made executable, because the agent didn't inherit any.
MayaAnd that's why it's not prompting. Prompting is a sentence you hope lands. This is a system of guides and sensors and a feedback loop that you build, measure, and maintain across the lifecycle. That's the test you asked for. If you're tuning the net instead of catching the fish, you're doing the discipline.
LeoI'll grant it the hat.
LeoWhich means now I get to be a problem. Because she's making real claims, and a couple of them I don't think the evidence carries yet — and to her credit, she says so herself.
MayaGo. She'd want this; the article ends on open questions, not a victory lap.
LeoStart with the behaviour harness. The proposed fix is: have the agent generate the tests that check its own behaviour. But that's the thing we spent this whole topic worrying about — the agent grading its own homework. If the agent wrote the bug *and* wrote the test, the test passing tells me almost nothing.
MayaI won't fight you, because she doesn't either. Her own words: this puts a lot of faith in AI-generated tests, and that's not good enough yet. There's a pattern she likes — approved fixtures, where a human signs off on a trusted set of inputs and expected outputs once, and the agent checks against those. But she's explicit it's selective. It fits some areas, not others. It is not a wholesale answer to the test-quality problem.
LeoFine. Concession logged.
LeoSecond one, and this is the one that actually bites. She says — beautifully — the harness is most needed where it is hardest to build. The gnarly legacy codebase with ten years of debt is exactly where you'd most want the agent supervised, and exactly where you *can't* build good guides and sensors, because the place is a swamp.
MayaYeah. That one I can't wave away. She coins a word for it — harnessability — how amenable a codebase even is to being harnessed at all. And the green-field service with clean layers is wildly harnessable. The legacy monolith is barely harnessable. So the discipline works best exactly where you need it least.
LeoWhich to me is more than a footnote. It means "harness engineering as a discipline" might quietly be "harness engineering for codebases that were already in good shape." The agents get trustworthy on the easy stuff and stay untrustworthy on the hard stuff.
MayaHere's my real partial concession, and then where I hold the line. You're right that harnessability is unevenly distributed, and that's a genuine limit — not a quibble. Where I hold: the discipline gives you a *lever* on it. Harnessability isn't fixed. Some of the same work that makes a codebase legible to humans — clear seams, good tests, enforced architecture — is exactly what makes it harnessable. So a swamp isn't a life sentence. It's a backlog.
LeoSo the honest version is: the harness is hardest to build where it's most needed — *and* building it is the same work as paying down the debt anyway.
MayaThat I'll fully sign. The discipline doesn't dodge the swamp. It tells you the swamp is the work.
LeoOkay. That I buy.
MayaAnd there's a third open question she leaves on the table that I think is the most interesting, so I won't pretend to resolve it. When your guides say one thing and your sensors say another — the convention file says "keep it simple," the coverage gauge says "add more tests" — how far do you trust the agent to make the trade-off itself? She doesn't answer it. She just names it as a live problem the field has to solve. Which is, again, the most engineering-discipline thing in the whole piece — it has a known list of things it can't do yet.
LeoGive me one more of her open questions, because it's the kind of thing only someone who's actually built these would ask.
MayaThis one's my favorite. She asks: if your sensors *never fire* — if the lights stay green for a month — is that a sign of high quality, or a sign your detectors are broken?
Leo[chuckle] Oh, that's a genuinely nasty question.
MayaIt's nasty because both answers are plausible and you can't tell them apart from inside the green. It's the same reason serious teams use mutation testing — deliberately break the code to check the tests actually scream. She floats the same idea for harnesses: we need a way to measure harness coverage and quality the way code coverage and mutation testing measure tests. And right now — there isn't one. Nobody's built the gauge that checks your gauges.
LeoSo the field has a tooling-shaped hole right in the middle of it.
MayaA tooling-shaped hole, and she basically waves at it and says: someone go build this. Which is what the end of a real research agenda sounds like.
MayaSo let me bring it home and hand you the question. The whole topic, we kept finding capability hiding outside the model — in the context, the tools, the memory, the edit format. Today's frame is the one that ties it together: all of that is one system you can engineer on purpose, with guides that steer and sensors that catch and a loop that learns. The model is the driver. The harness is everything the org knows about how to build things, written down and made enforceable, because the driver showed up with no memory of your shop.
LeoAnd the open edge is that the most important harness — the one that checks the thing actually *works* — is the one nobody's finished.
MayaRight. So here's what I want you sitting with.
LeoGo ahead.
MayaThink about your own codebase for a second — the real one, not the clean one in your head. If you had to make it *harnessable* — legible enough that an agent could be steered and checked without a human watching every line — what's the very first guide or sensor you'd build... and is that first thing telling you something you've been avoiding about the codebase itself?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents