Subscribe
Transcript
MayaWhat would it take to fire the person who hand-tunes the harness — and let a second agent write it instead? Here's the specific answer this paper found. Not the model, not the human engineer hand-tuning the prompt at midnight — a second agent, whose entire job is to *invent the wrapper*. And before it writes a single line, it gets to walk into a room where every harness anyone ever tried is sitting on a shelf. Not a summary of how they did. The actual code. The actual run logs. The actual scores. It reads the whole shelf, then writes the next one.
LeoSo we've gone up a floor. We're not optimizing the model anymore, we're not even hand-optimizing the harness — we're automating the *person who optimizes the harness*.
MayaRight, that's the move this paper makes. And the twist that makes it work isn't "use an agent to write code" — everybody's doing that. It's *what the agent is allowed to read* while it writes.
LeoOkay, go.
MayaWhere did we leave the harness? With a human still holding the pen — the OpenAI piece, harness engineering in an agent-first world, where humans build the garage and the discipline lives in the scaffolding. Humans still steer, agents execute.
LeoToday's paper asks the uncomfortable follow-up. If the harness is part of capability — which is the thing we've been hammering all topic — then who builds the harness, and why is *that* still a human doing it by hand?
MayaRight. Every episode so far, the harness was hand-engineered. Smart people writing context rules, tool schemas, memory policies. This paper — it's called Meta-Harness, end-to-end optimization of model harnesses — says: let a search process build it. Automatically. And then it goes and *measures* whether that actually beats the humans.
LeoAnd I want to flag right now, because we parked this exact worry back in the overview — "automatically optimized harness" set off my perpetual-motion alarm. So I'm coming in skeptical and staying there until the numbers earn it.
MayaGood. Hold that. Because the numbers are the interesting part.
LeoDefine it before the jargon eats us. We've used "harness" all topic. What's the *meta*?
MayaStart with what we know. The harness is the code around the model — what it stores, retrieves, and shows the model on each step. Context, tools, memory, the lot. Hand-written, usually.
LeoRight.
MayaA meta-harness is a harness for *building harnesses*. It's an outer loop. The inner loop is the agent doing the actual task — fixing the bug, solving the math problem. The outer loop is a different agent whose task is: write the inner loop's harness, watch it run, and write a better one.
LeoSo it's optimization, but the thing being optimized isn't weights and it isn't a prompt string — it's *source code*. The harness is a program, and the meta-harness searches over programs.
MayaCleanest way to say it, yeah. The search space is code. Not "tweak this temperature," not "reword this instruction" — propose a whole new program that decides what the model sees, run it, score it, propose another.
LeoWhich immediately raises the question I always ask. People have been auto-tuning prompts for years. Text optimizers. What's actually new here?
MayaExactly the right question — and the paper's whole argument hinges on the answer.
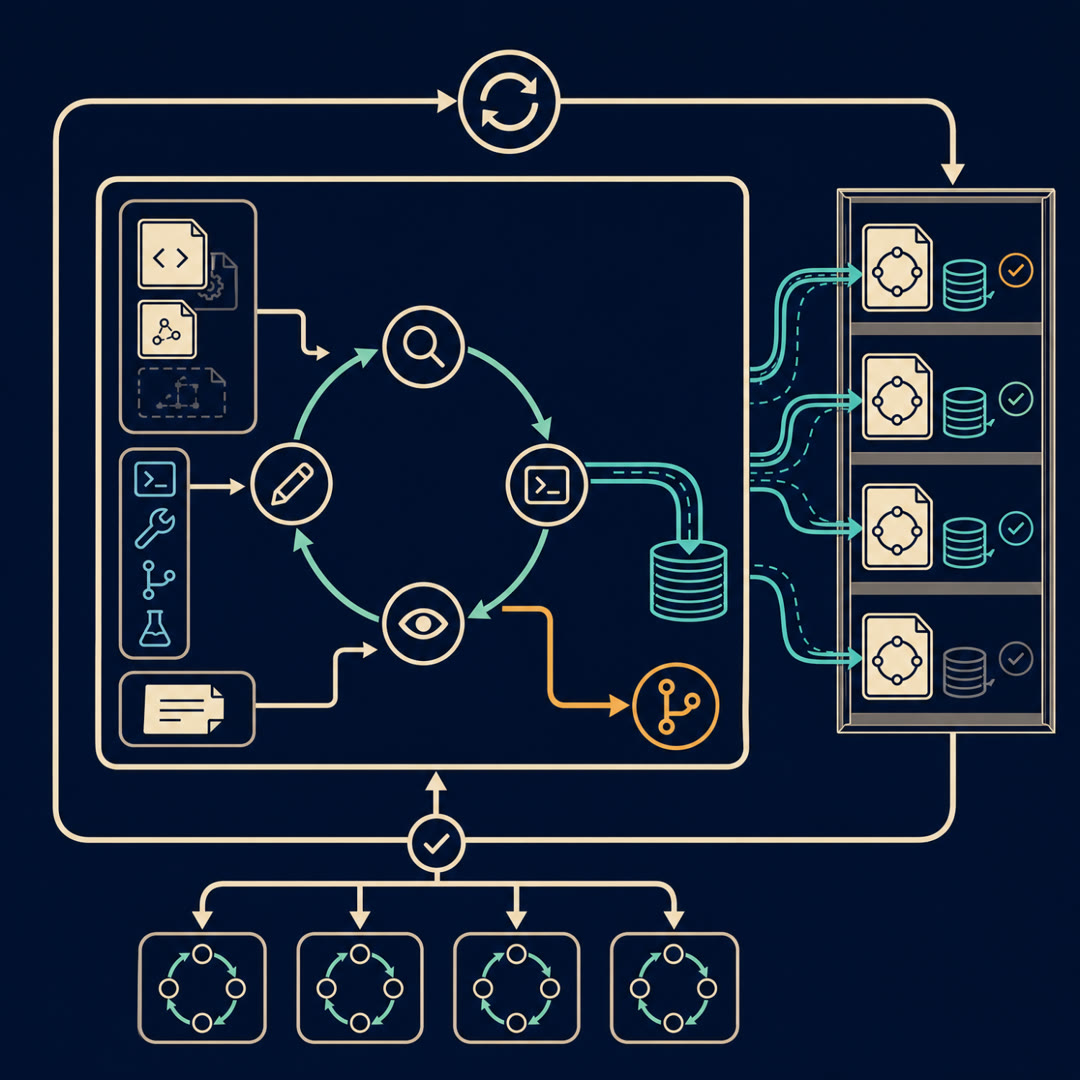
MayaLet me give us three landmarks to hang this on, because the system has three moving parts and they're easy to blur. Call them the Library, the Proposer, and the Ledger.
LeoWalk me through them one at a time.
MayaThe Library first. It's a filesystem holding every harness candidate that's ever been tried in this run — and not just the candidate. For each one: its full source code, its score, and its execution traces. The actual record of what happened when that harness ran the task.
LeoSo nothing gets thrown away. Every attempt, good and bad, stays on the shelf with its receipts.
MayaEvery attempt, with its receipts. Then the Proposer — that's the agentic part. It's an agent that reads the Library through that filesystem, and writes the next candidate. It can open any prior harness's code, read why it scored what it scored by looking at the traces, and decide what to try next.
LeoHuh.
MayaAnd the Ledger is just the scorekeeping — each candidate gets evaluated on the task, gets a number, and that number goes back into the Library for the next round to learn from.
LeoLibrary, Proposer, Ledger. The shelf, the writer, the scoreboard. So the loop is: read the shelf, write a new harness, score it, shelve it, repeat.
MayaThere's your engine. And now I can answer your "what's new" question, because it's hiding in the Library.
LeoGo. Because text optimizers reading feedback and proposing changes — that's not novel on its face.
MayaHere's the paper's sharp claim. Existing text optimizers are *poorly matched* to this setting — and the reason is they compress feedback too aggressively.
LeoDefine "compress feedback." What does that mean concretely?
MayaA typical prompt optimizer runs a candidate, takes the result, and boils it down to a short critique — "the model got confused by the long context, try summarizing." A sentence or two. Then it hands *that sentence* to the next round. The next proposer never sees the run. It sees the postcard about the run.
LeoAh — so it's playing a game of telephone with itself. Each generation only learns from a lossy summary of the last one.
MayaThat's exactly it. And for tuning a sentence of prompt text, a postcard might be enough. But you're not tuning a sentence here. You're tuning a *program*. To know why a harness underperformed, you might need to see the actual trace — where it spent its context budget, which tool call returned garbage, the exact step where it lost the thread. A two-line critique can't carry that.
LeoSo the bet is: don't compress. Give the proposer the whole filesystem — all the source, all the scores, all the traces — and let *it* decide what's relevant.
MayaWhole bet, right there. The richness of what the proposer can read *is* the contribution. The old way summarized to save space. This way says: space is cheap, put the entire history on a filesystem and let an agent rummage through it like a developer reading old commits and failed CI logs.
LeoOkay, that's a real difference.
MayaIt's the difference between handing your new hire a one-paragraph handoff doc versus giving them the full repo history and saying "go read why we tried and abandoned this."
MayaLet me ground this, because we've been abstract for a minute. Think about two investigators. One's handed a one-line incident report — "the harness got confused." The other's given the entire case file: every prior attempt's full source, its score, and the minute-by-minute record of how it actually played out.
LeoSo the old optimizer is the first investigator. It works the case off a summary somebody else already wrote.
MayaRight. And the Proposer is the second one — it walks into the evidence room and reads the *raw* files itself. Until today, the person redesigning the harness was a human working from those one-line reports. This paper hands the whole evidence room to an agent and lets it decide which detail in which old run actually mattered.
LeoSo the model is still the suspect's behavior we're trying to fix, the harness is still the procedure around it — and the meta-harness is the detective rebuilding that procedure by re-reading every closed case in full, not from a single line that says "lost the thread."
MayaAnd that's the upgrade. The old optimizer got the line — "lost the thread." The Proposer gets the full transcript and works out for itself that the thread was actually dropped three steps earlier, when a tool call returned garbage nobody flagged.
LeoDetail that a summary would've flattened.
MayaEvery time.
LeoMechanism's clean. Now I want evidence, because elegant ideas die on contact with benchmarks all the time. What did it actually beat, and by how much?
MayaThey ran it across three different settings, deliberately spread out so it's not one lucky domain. Start with online text classification — sorting a stream of incoming text into categories on the fly. They put it against a state-of-the-art context-management system, the kind of thing experts hand-build to decide what to keep in the window.
LeoAnd?
MayaThe discovered harness beat it by about seven and a half points — while using *four times fewer* context tokens.
Leo{gasp} Wait — better *and* cheaper on context? Those usually trade against each other.
MayaRight — and that's the part that made me sit up. You normally buy accuracy with more context. This found a harness that was more accurate on a quarter of the context budget. It didn't just tune the dial — it found a smarter shape.
LeoOkay, classification's one. Where else did they push it?
MayaMath reasoning — and this is the one I find almost spooky. Two hundred olympiad-level problems, the hard kind. A *single* harness it discovered improved accuracy by about four and a half points — and here's the kicker — averaged across five *held-out* models.
LeoHold on. Held-out meaning models it didn't optimize against?
MayaModels it never saw during the search. One harness, found once, transfers to five different models it wasn't tuned for, and lifts all of them.
LeoNow *that* — that's the claim I actually care about, because it's the one my skepticism was aimed at. If it only worked on the model you tuned it with, it's overfitting wearing a lab coat. Transferring to unseen models is — that's the thing that says you found a real harness improvement, not a benchmark exploit.
MayaWhich is exactly why it's the load-bearing result. A harness that generalizes across models is evidence that the *structure* it found is genuinely better, not memorized.
LeoAnd the one that's home turf for us?
MayaAgentic coding, yeah — that's the third. TerminalBench-2, terminal-based engineering tasks. The discovered harnesses beat the best *hand-engineered* baselines. The humans' best work, out-searched.
LeoOn our own benchmark. Okay.
LeoSo now let me earn my keep, because three wins doesn't close the case, and the honest version of this episode says where it's soft.
MayaPlease. This is the part I'd want a listener to actually hold onto.
LeoStart with contamination. We've spent the whole topic warning about it — tune against a fixed benchmark, get something brilliant at that benchmark and brittle everywhere else. The transfer result blunts that worry for the math case. But "beats hand-engineered baselines on TerminalBench-2" — did the search run *against* TerminalBench-2? Because if you optimize on the same benchmark you report, the alarm's back on.
MayaFair, and I won't paper over it — the abstract leads with the result, not the protocol. The math transfer to held-out models is the strongest generalization evidence in the paper. For the coding number, the thing that would settle it is the same thing we keep asking for all topic: held-out tasks, not just held-out runs of the same task.
LeoNoted.
LeoThen there's the one that nags me most — what does this *cost*? An outer loop that proposes whole programs, runs each one to completion, stores full traces of every candidate — that is not free. You're paying for every harness in the Library, not just the winner.
Maya{sigh} And the honest answer is the abstract doesn't put a price tag on it, which means I can't either. But the shape of the cost is obvious from the mechanism. Every candidate is a full run. The search burns inner-loop compute on a pile of harnesses that get thrown away. So even granting the wins, the live question is the ratio — how much search to find a harness, versus how much you save by running the good one forever after.
LeoWhich is actually the redeeming framing, isn't it. You pay the search cost *once*. The math harness was discovered once and reused across five models. If a found harness amortizes over thousands of downstream runs —
Maya— then it's a one-time capital expense, not a per-run tax. Yeah. The economics live in how many times you get to reuse the thing you found. Search is expensive; the artifact, if it transfers, is cheap to keep using.
LeoSo my objection survives as "we don't know the number," not as "this can't pay off."
MayaFair landing, yeah. And there's a third soft spot worth naming — the Proposer is itself an agent. It can read the whole Library and still propose something clever-looking that games the score instead of solving the task. The richer the information you hand an optimizer, the more surface it has to find a shortcut.
LeoThe reward-hacking risk, one level up. The thing optimizing your harness can learn to hack your harness metric.
MayaWhich is why the transfer test matters so much. A harness that's gaming the score won't survive five models it never saw. Generalization is the cheapest lie detector they had, and they ran it.
LeoSo step back. What's the durable takeaway, separate from any one number?
MayaThe takeaway is that the harness graduated from a thing you *write* to a thing you *search for*. All topic we treated the harness as the artifact of human craft. This paper treats it as an optimization target with a well-defined search space — programs — and a well-defined signal — scores plus traces.
LeoAnd the unlock that made it work wasn't a fancier optimizer. It was refusing to throw the history away.
MayaThat's the line I'd keep, honestly. Don't summarize the past — let the optimizer read it in full. The old way starved the search to save space. This way feeds it everything and lets the agent decide what mattered.
LeoIt's funny — that's the same lesson as observability from the overview, just pointed in a new direction. We said the trace is the asset because four teams read it. Turns out a fifth reader is *the optimizer building the next harness*.
MayaOh, that's the connection, yeah. The trace isn't just for debugging and training and safety. A rich enough trace is fuel for automatically inventing a better wrapper. Observability was the flywheel — this is one more thing the flywheel turns.
LeoNice.
MayaAnd it loops the whole topic shut. We opened by saying capability lives partly in the harness, not just the weights. If that's true, then optimizing the harness is optimizing capability — and now we have a method that does it by machine, reads its own full history, and ships a harness that transfers to models it never met.
MayaSo here's where I'd leave it for you. If a search process can read every past attempt in full and out-design the best harness humans have hand-built — across models it was never tuned for —
Leo— then the question stops being "is the meta-harness any good," and becomes something sharper.
MayaIf the harness can now be searched for instead of written by hand, and the only thing the optimizer truly needs is the *complete, un-summarized record* of every attempt — what's the first piece of your own system's history that you're currently throwing away, that a machine could be learning from instead?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents