Subscribe
Transcript
MayaTwo agents look at the exact same pull request. The first one wrote it — it produced a clean patch, the tests go green, it's proud. The second one is reading it cold, and after a minute it circles one line and says, "this quietly turns off refunds for one currency."
LeoAnd only the second one caught the thing that actually matters.
MayaRight. Same diff, two completely different jobs. Writing the patch is one skill. Reading someone's patch and saying *what's wrong with it, where, and how bad* — that's a different skill living in a different head. Today is about treating that second job as a capability of its own.
LeoLast time, in the leaderboard episode, we pulled apart a single headline number — the work, the room, the judge — and the whole point was that a score is only evidence when you know what it's standing on.
MayaThat was the evaluation half: judging the patch the agent *produces*. Today flips it. The agent isn't on trial for the code it writes — it's the one doing the judging. Review is the other half of agentic coding, and almost nobody scores it directly.
LeoOkay, plain language first. When we say "review as a capability," what does the agent actually have to be good at?
MayaIt has to read intent, read the diff, reason across the rest of the codebase, find the defect nobody wrote a test for, decide how much you should care, and say something a tired engineer would actually act on. And the uncomfortable part — a model can be great at writing code and bad at every one of those.
LeoWait, why would those come apart? If you can write good code, surely you can spot bad code.
MayaYou'd think. But writing is generative — you steer toward one answer you control. Reviewing is forensic — you walk into a decision someone else already made, with their assumptions baked in, and you have to reconstruct *why* before you can say it's wrong. Different muscle.
LeoGive me the map before we walk it, so I don't lose the thread on a walk.
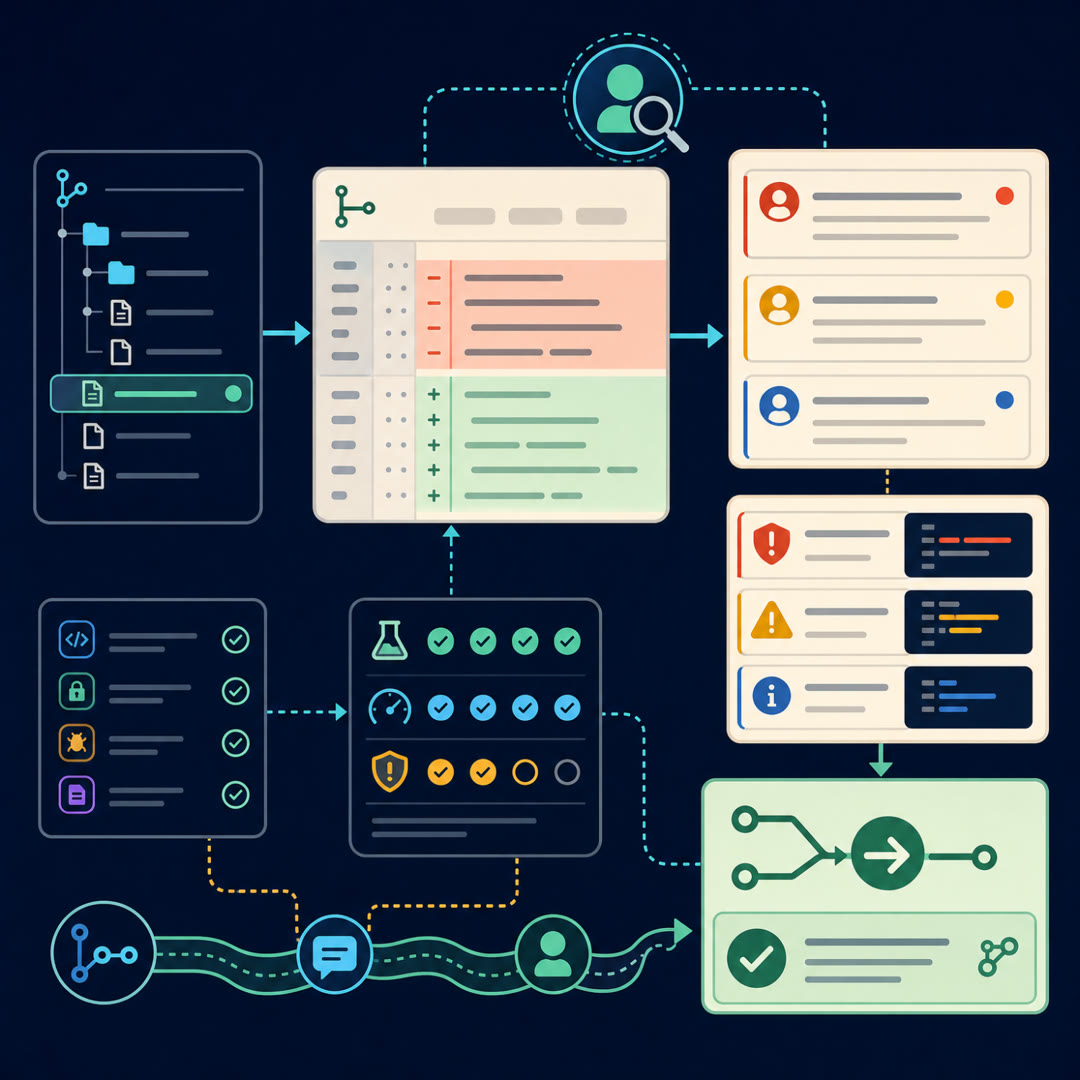
MayaThink of it as a reviewer's desk with a few stations. The agent picks up the request, understands the *intent*. It reads the *diff* and pulls in surrounding *context*. It *localizes* — points at the exact line. It assigns *severity*. And then there's the part everyone forgets: the *acceptance loop*, what the human did with the comment afterward.
LeoIntent, diff, context, localization, severity, and the acceptance loop. Got it.
MayaFirst station — intent. Before a reviewer can say a change is wrong, it has to know what the change was *trying* to do.
LeoBecause "wrong" is relative to a goal.
MayaExactly. Take our running example — a small team ships a fix to an open-source data library. The pull request says, "handle the empty-input case in the aggregation function." That sentence is the intent. A good reviewer reads it and now has a yardstick: did the patch handle the empty case, and *only* the empty case?
LeoSo intent isn't decoration, it's the measuring stick.
MayaIt's the measuring stick. And this is where pull-request context comes in — the title, the description, the linked issue, sometimes a discussion thread. A reviewer agent that ignores all that and just stares at the raw diff is reviewing in the dark. It can tell you the code is *unusual*, but not whether it's *wrong for this task*.
LeoHmm. So a comment like "this changes refund behavior" only lands if the agent knows refunds weren't supposed to change.
MayaThat's the whole game. The defect in our example isn't that the patch is malformed — it parses, it runs, it passes the obvious test. The defect is that it *exceeds its intent*. It handled the empty case and, as a side effect, silently disabled refunds for one currency. You can only call that a bug if you anchored on what the change was *for*.
LeoRecap for me — intent is the reviewer reconstructing the goal so it has something to measure the diff against.
MayaSecond station — the diff itself, and the context wrapped around it. The diff is the added and removed lines. But the bug usually isn't *in* the diff.
LeoWait, say that again. The bug isn't in the changed lines?
MayaOften it isn't. The changed lines look fine in isolation. The danger is how they interact with code the diff *doesn't* touch. In our example, the new empty-case branch returns early — totally reasonable on its own. The problem is three files over there's a refund hook that expected the old code path to run first. The diff is innocent. The *interaction* is the bug.
LeoSo a reviewer that only reads the red and green lines is structurally blind to that.
MayaStructurally blind. This is the single biggest reason review is hard for agents. Diff understanding has to reach past the diff. The reviewer needs to pull in the surrounding functions, the callers, the data flow — enough of the repository to see the collision.
LeoThis actually matches how the real tools describe themselves, right?
MayaIt does. GitHub's documentation for its Copilot code review agent says it analyzes your *entire repository* to understand a change, not just the patch — and it can leave suggested fixes you apply in a click. That's exactly this station. The honest footnote, from their own docs: it won't catch everything, it sometimes makes mistakes, keep a human in the loop.
LeoGood — I was about to ask whether anyone's pretending this is solved.
MayaNobody serious is. The whole research area around this exists because reaching the right context, reliably, is the unsolved part. My recap: the diff tells you *what changed*, the context tells you *whether that change breaks something it never touched*.
MayaThird and fourth stations together, because they're what turn a vague worry into a usable comment — localization and severity.
LeoLocalization first.
MayaLocalization is pointing at the *exact line*. Not "something feels off in this file." The precise statement. Compare "there might be an edge case here somewhere" with "line in the early-return branch skips the refund hook." One is a shrug. The other is a fix.

LeoThat's the difference between "there's a leak in the house" and "the joint under the kitchen sink."
Maya[chuckle] That's it exactly. And it's measurable. The review benchmarks score whether the agent landed on the *right line*, because a true warning aimed at the wrong place wastes the author's time almost as badly as a false one.
LeoOkay, severity. Why does that need its own station?
MayaBecause not every true comment deserves the same volume. Severity is the reviewer saying *how much you should care*. A naming nitpick and a silent data-corruption bug can both be technically correct comments. If the agent flags them at the same intensity, it's useless — you can't triage.
LeoSo in our example, the refund thing should be screaming.
MayaIt should be a top-severity flag — silent, user-affecting, money-touching. Meanwhile "you could rename this variable" should be a whisper, if it's there at all. A reviewer that can't rank is just a list. A reviewer that ranks is a *colleague*.
LeoRecap from me — localization says *where*, severity says *how loud*, and you need both before a comment is worth reading.
MayaLast station, and it's the one people skip — the acceptance loop. Everything so far happens before the human reacts. This is *after*.
LeoMeaning what the developer did with the comment.
MayaRight. A comment isn't really validated until someone responds to it. Did the author accept it or reject it? Did they push back in a reply — "no, that's intentional"? Did they actually *apply a fix* in response? And later, after merge, did the thing the reviewer warned about blow up or not?
LeoSo the ground truth for "was this a good review" lives in the human's reaction, not in the comment itself.
MayaThat's the deepest idea in this whole topic. You can't fully grade a review from the diff alone, the way you can grade a patch against hidden tests. The grade is partly *social* — accepted comments, rejected comments, author responses, applied fixes, post-merge signals. That's why the strongest review datasets are built from real pull requests where you can *see* what reviewers flagged and what authors did next.
LeoAnd there's industrial evidence this actually works at scale, isn't there?
MayaThere is. Meta has published on AI-assisted fixes to code-review comments across a huge internal codebase, and the signal they care about is exactly this: was the comment accepted, was a fix applied, did developers keep using it. Review measured by what humans *did*, not by a checkmark.
LeoLet me name the limitation, since every one of these owes one. The acceptance loop is noisy, right? A developer can reject a *correct* comment because they're rushed, or accept a wrong one because the agent sounded confident. So "the human acted on it" isn't a clean oracle.
MayaThat's exactly the soft spot. Human acceptance is the best ground truth we have *and* it's biased — by deadline pressure, by who's senior, by how confident the comment sounds. So you treat it as strong evidence, not truth. The same humility we keep hitting: every signal in evaluation has an edge where it lies to you.
LeoSo even the human-reaction signal needs a skeptical reader.
MayaAlways. The fix isn't to find a perfect signal — there isn't one. It's to collect *several* — the line, the severity, the accept-or-reject, the applied fix, the post-merge outcome — and cross-check them.
MayaSo here's the compact version. A code review agent is not your code generator wearing a different hat. It's a separate capability with its own job: read the intent, read the diff *and* the code around it, land on the exact line, rank the severity, and earn a real reaction from a human.
LeoAnd the running example carries the whole thing — the patch that passes every visible test, handles the empty case perfectly, and still quietly kills refunds for one currency. The generator's proud. Only a *reviewer*, reading intent against context, ever catches it.
MayaThat's the other half of agentic coding in one image. Writing code closes the task. Reviewing code is how the team keeps trusting the code that got written — and it has to be measured as its own skill, or it doesn't get measured at all.
LeoWhich loops right back to the series promise — store the whole story. For review, the story is the comment, the line it landed on, the severity it gave, whether the author took it, and what happened after merge.
MayaCollect that, and you can actually train and trust a reviewer. Collect only "found a bug: yes or no," and you've measured almost nothing.
LeoHere's the one to sit with: think about the last time someone reviewed *your* code and caught something real. Would a reviewer that only saw the changed lines — and never the intent or the code around them — have caught it too?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents