Subscribe
Transcript
MayaPicture an agent that's brilliant at writing the patch and helpless at landing it. It produces a perfect diff — and then it can't get the project to install. It can't find why the build dies. It runs the wrong test command, mis-reads the error, and burns its whole budget thrashing in a shell it doesn't understand. The code was never the hard part. The terminal was.
LeoSo the thing under the microscope today isn't "can it code." It's "can it survive a real command line, start to finish."
MayaThat's the whole move. Most benchmarks we've covered hand the agent a clean room — repo's installed, tests wired up, here's your issue. Today's refuses to do that. It drops the agent into a raw terminal and says: do the entire job yourself, including the messy plumbing nobody writes a paper about.
LeoOkay, but last time we were somewhere pretty different. Aider Polyglot — that was about edit *reliability* across a bunch of languages. Could the model produce an edit in the exact format the tool expects, cleanly enough to apply, over and over.
MayaRight. Polyglot zooms way in on one motion: make a correct edit, get the format right, don't corrupt the file, and do it whether it's Rust or Go or Python. It's a precision-of-the-keystroke benchmark.
LeoAnd today zooms all the way back out.
MayaAll the way out. Terminal-Bench cares less about any single edit and more about whether the agent can run a long, multi-step task in a live shell and reach the actual goal. The source is called Terminal-Bench 2.0 — the second version of a benchmark built entirely around command-line work.
LeoPlain version first. When you say "a task in a terminal," what does one actually look like? Because "use the command line" could mean anything.
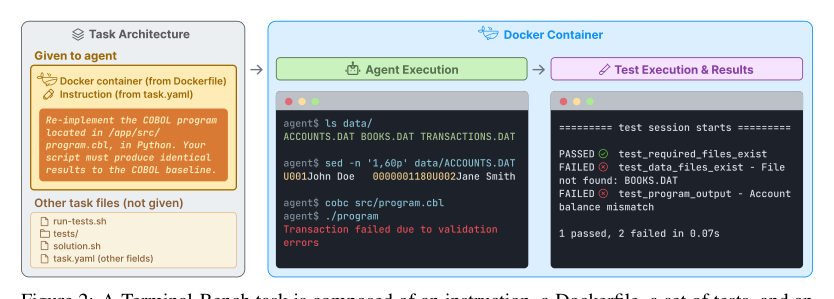
MayaFair, let me make it concrete. Each task is a little world. The page describes tasks drawn from real workflows — the kind of thing a working engineer actually opens a terminal to do. Set up an environment, get a stubborn project to compile, track down why a service won't start, wrangle some files, run a pipeline. Not a toy puzzle. A chore from someone's real Tuesday.
LeoAnd the agent is just... dropped at a shell prompt.
MayaDropped at a prompt, in its own sandboxed environment, with a goal stated in plain language. From there it's on its own. It types commands, reads what comes back, decides the next command, and keeps going. No one has pre-installed anything for it. No one has wired up the tests.
LeoSo the difference from a SWE-bench-style task is that the *environment itself* is part of the problem.
MayaThat's exactly it, and it's the heart of why this benchmark exists. In the issue-fixing benchmarks we covered, somebody already paid the environment tax — the container's built, dependencies installed, the test command known. Terminal-Bench hands the agent that bill. Figuring out how to even run the thing is now part of the test.
LeoWhich, honestly, is most of the frustration of real work. The code is fine. Getting it to *run* is the day.
Maya[chuckle] That's the lived experience the benchmark is trying to capture. And it's why "2.0" matters. A second version usually means somebody looked at the first one, found the tasks that were too easy or too flaky or too gameable, and rebuilt.
LeoOkay, so how does it grade? Because this is the part I always want pinned down. In a shell, "did it succeed" is fuzzy. The agent could reach the right end state by a totally different path than a human would.
MayaAnd that's the clever constraint. It doesn't grade the *path*. It grades the *world afterward*. Each task ships with its own verification — comprehensive tests, in the language of the page — that check the final state of the environment.
LeoSay more about "final state." That's the load-bearing idea.
MayaThink about what a terminal task leaves behind. A file that should now exist, with the right contents. A service responding on a port. A build that produces a working binary. The verification doesn't care which commands you typed — it checks whether the world ends up the way the goal demanded.
LeoAh. So it's an outcome oracle, not a transcript oracle. You can solve it your way, as long as reality matches at the end.
MayaOutcome oracle — I like that. And it's the right call for a terminal, because there are a hundred valid ways to get a project building. Grading the commands would punish creativity and reward mimicry. Grading the end state asks the only question that matters: is the job actually done.
LeoAnd each task brought its own tests, you said. Human-authored?
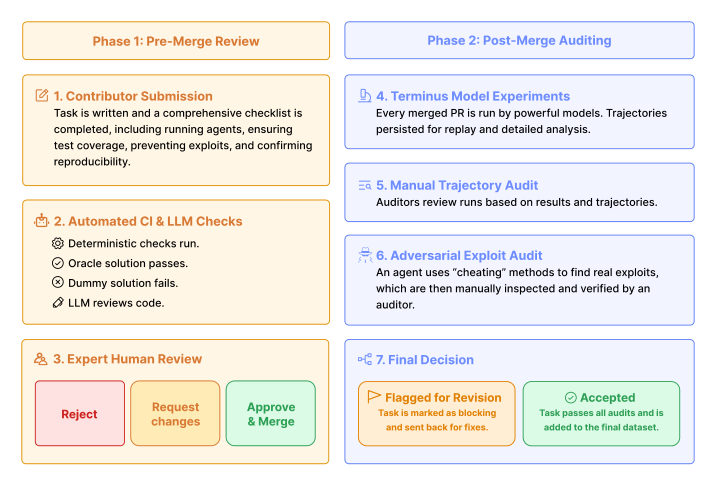
MayaHuman-authored solutions and human-written verification, from what the page describes. Somebody sat down, did the task the real way, and wrote checks for what "done" looks like. That's expensive — which is part of why the set is deliberately small and hard rather than huge and shallow.
LeoThat's a different philosophy from the thousands-of-issues benchmarks.
MayaTotally different. This is the curated-and-brutal end of the spectrum. A modest number of tasks, each one genuinely hard, each one hand-verified. The bet is that a small set of *real* problems tells you more than a giant set of easy ones.
LeoAnd does it work? Are the frontier agents crushing it or struggling?
MayaStruggling, and that's the headline the page leads with — even the strongest current models and agents land below a clear bar on this. They're nowhere near solving it. Which is the whole point of building a 2.0: the authors deliberately made it hard enough that today's best agents have real room to fail.
LeoAnd I want to be careful here — I don't want to throw a fake precise number out. Let's just say it's well short of solved.
MayaThat's the honest framing. The exact figure lives in the paper; what I'll stand behind is the shape — frontier agents are clearly under the ceiling, with lots of headroom. A benchmark that's already saturated tells you nothing about next year's models. This one has somewhere to go.
LeoSo why do they fall down? Did the page say where it breaks?
MayaIt points at an error analysis — the authors don't just report a score, they look at *how* agents fail. Without overstating specifics, the failure shape on long terminal tasks is recognizable. The agent loses track of state. It misreads an error message and confidently fixes the wrong thing. It runs a command, doesn't check whether it worked, and barrels forward on a false assumption.
LeoHmm, that last one is so human. Not checking your own work.
MayaIt's the core long-horizon failure. A single edit, you can get right. Twenty dependent steps, where step nineteen relies on step four having actually succeeded — that's where agents quietly drift off the rails. One unnoticed failure early and everything downstream is built on sand.
LeoOkay, give me the limitation now. The part where this benchmark itself has a weak spot.
MayaSeveral, and worth naming honestly. The biggest is the one we keep circling — environment reproducibility. A terminal task reaches into a real operating system. The page itself flags that a container doesn't guarantee perfect isolation, and that tasks can drift over time. Run the same task next year and an upstream tool changed, a default flipped — and now a task that was fair is flaky.
LeoSo the same rot we hit with the live benchmark, except here it's baked into every single task, because every task is basically a tiny system.
MayaExactly. The richer and more realistic the environment, the more surface area there is for it to shift underneath you. Realism and reproducibility are pulling against each other, and this benchmark sits hard on the realism side.
LeoWhat else?
MayaSmall size cuts both ways. A modest, hand-built set is high-quality, but it's a small sample — a few task draws going your way can move a percentage. And there's a subtler one: any verification you can write, an agent can in principle game. If a test checks that a file exists with certain contents, a clever-but-wrong agent might fake the artifact without doing the real work. Outcome-checking is strong, but it's not immune to shortcuts.
LeoReward hacking in a shell. Produce the thing the grader looks for without actually solving the problem.
MayaThat's the shadow over every outcome oracle. The tests have to be thorough enough that the only realistic way to pass is to genuinely do the task. The harder the task, usually the harder it is to fake — but it's never zero risk.
LeoLet me pull it back to our running thread. The little team shipping a fix to that open-source data library — where does a terminal benchmark touch them?
MayaBeautifully, actually. Their fix has to pass hidden tests *and* survive review. But before either gate, there's a step nobody glamorizes: getting the library to build and its test suite to run at all. On a real contributor's machine, that's half the battle — clone it, install the right versions, make the tests green before you've changed a line.
LeoRight. The boring part that decides whether you even get to play.
MayaAnd a terminal benchmark is the one that measures *that* boring part. Can the agent stand up the project's environment, run the suite, interpret a failing test, and not wander off when the build complains. The issue-fixing benchmark assumes the agent already cleared that bar. This one makes clearing it the actual exam.
LeoSo in the topic's bigger map, this is another instrument shaped to see a different slice of the work.
MayaThat's the throughline of this whole module. There's no single "coding agent" ruler. Polyglot sees keystroke-level edit reliability. The issue benchmarks see can-you-fix-a-bug. Terminal-Bench sees can-you-operate-a-live-machine-end-to-end. Same agent can look strong on one and fall apart on another — and that gap is information, not noise.
LeoAnd the lesson we keep landing on — the score isn't the product.
MayaSame as ever. The valuable artifact isn't "it solved sixty-some percent." It's the replayable task underneath — the sandbox, the goal, the human verification of the end state, and the trace of every command the agent typed trying to get there. Especially the failures. Watching an agent thrash in a terminal tells you more about its real competence than any clean success.
LeoThe trajectory through the shell is the evidence.
MayaThe trajectory is the whole evidence. A passing diff hides how the agent struggled. A terminal transcript shows you exactly where it lost the thread — which is the most useful thing you can hand a team trying to make the next agent better.
LeoHere's a question to sit with, then. If the hardest part of real engineering is operating the environment — not writing the code — should we be ranking coding agents mostly on the patches they produce, or mostly on whether they can survive the messy terminal long enough to land them?
Source material
← Back to Agentic Coding Capability: From Coding Models to Coding Agents